









智谱AI:CogVideoX-2b——视频生成模型的得力工具

CogVideoX 简介——它是什么?
智谱AI公布了一项激动人心的技术创新:他们决定将他们开发的视频生成模型CogVideoX的源代码对外公开。
这个模型目前能够处理的提示词数量上限为226个token,这意味着它可以理解和响应较长的文本输入。生成的视频长度可以达到6秒钟,以每秒8帧的速度播放,分辨率则为720像素乘以480像素。虽然这只是一个初步的版本,但智谱AI已经透露,他们正在开发性能更优越、参数量更大的后续版本。
CogVideoX的核心优势在于其采用了先进的3D变分自编码器技术。这种技术能够将视频数据的体积压缩到原来的2%,极大地减少了处理视频所需的计算资源,同时保持了视频帧与帧之间的连贯性。这种技术的应用有效避免了在视频生成过程中可能出现的闪烁现象,保证了视频的流畅播放。
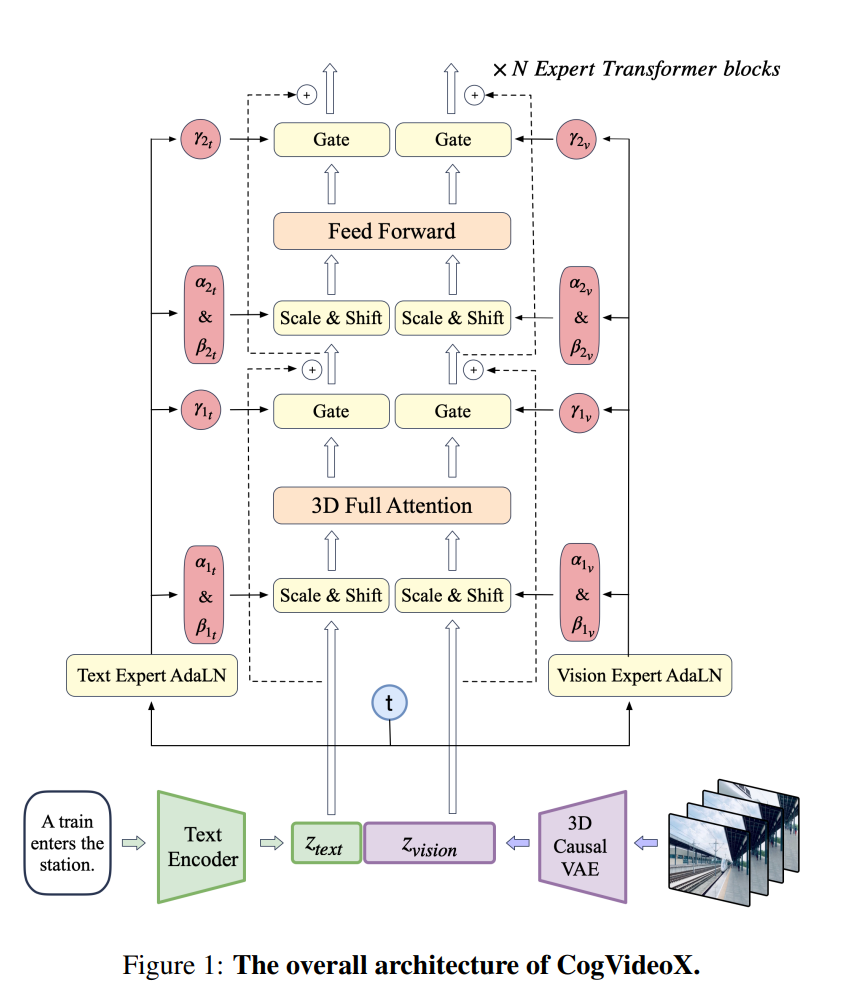
- 上图为3D旋转位置编码(3D RoPE)技术简介图
为了进一步提升视频内容的连贯性,CogVideoX还集成了3D旋转位置编码(3D RoPE)技术。这项技术使得模型在处理视频数据时,能够更加精准地捕捉到时间维度上帧与帧之间的关系,建立起视频中的长期依赖关系。这样的设计使得生成的视频序列更加流畅和连贯,提高了观看体验。
在提高视频生成的可控性方面,智谱AI开发了一个端到端的视频理解模型。这个模型能够为视频数据生成精确且与视频内容紧密相关的描述。这一创新显著增强了CogVideoX对文本的理解和对用户指令的执行能力,确保了生成的视频不仅与用户的输入高度相关,而且能够处理更长、更复杂的文本提示。
对于有兴趣深入了解和使用CogVideoX的开发者和研究者,智谱AI提供了以下资源:
- 代码仓库:可以通过GitHub访问,地址为:https://github.com/THUDM/CogVideo
- 模型下载:可以在Hugging Face平台上找到,地址为:https://huggingface.co/THUDM/CogVideoX-2b
- 技术报告:提供了详细的技术细节和模型性能分析,可以在GitHub上找到,地址为:https://github.com/THUDM/CogVideo/blob/main/resources/CogVideoX.pdf
本文将详细介绍如何在丹摩服务器上部署CogVideoX,并提供初步的使用指南,帮助用户快速上手并开始利用这个强大的视频生成工具。
CogVideoX 具体部署与实践指南
一、创建丹摩实例
要开始部署CogVideoX,首先需要在控制台中创建一个GPU云实例。以下是创建步骤:
- 登录到丹摩控制台。
- 选择并点击“GPU云实例”选项。
- 点击“创建实例”按钮。
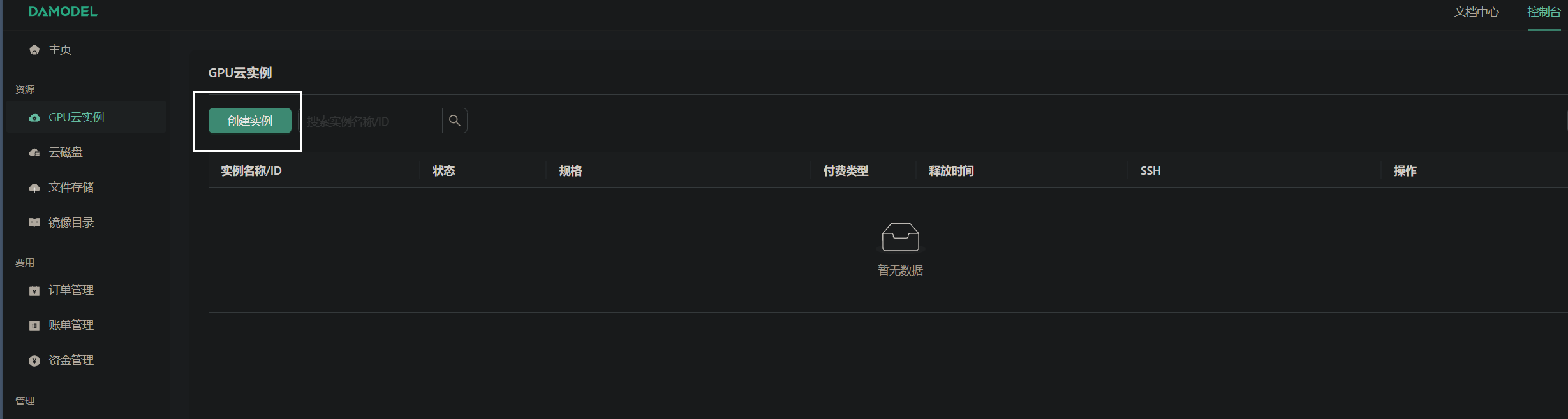
在实例配置中,考虑到CogVideoX在FP-16精度下进行推理至少需要18GB的显存,进行微调则需要40GB显存,因此推荐选择L40S或4090显卡。硬盘配置方面,可以选择100GB的系统盘和50GB的数据盘。操作系统镜像建议选择PyTorch 2.3.0、Ubuntu 22.04,CUDA 12.1版本。完成配置后,创建实例并绑定密钥对,然后启动实例。
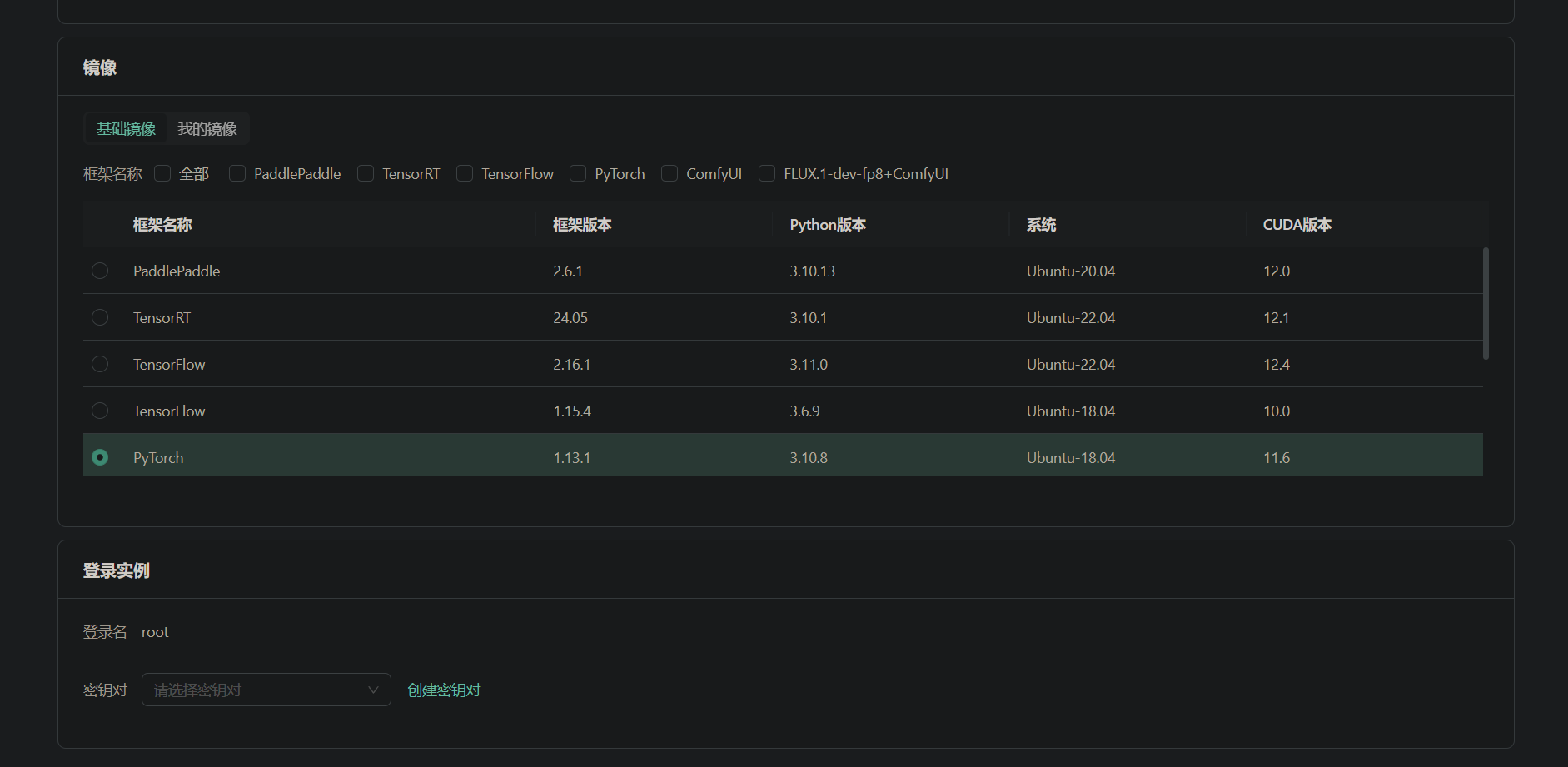
二、配置环境和依赖
创建好实例后,接下来需要配置环境和依赖。以下是详细步骤:
-
通过JupyterLab进入终端。
-
使用
wget命令下载CogVideo代码仓库:wget http://file.s3/damodel-openfile/CogVideoX/CogVideo-main.tar -
解压缩下载的文件:
tar -xf CogVideo-main.tar
-
进入
CogVideo-main目录,并安装依赖:cd CogVideo-main/ pip install -r requirements.txt -
安装完成后,可以通过以下Python代码测试依赖是否安装成功:
import torch from diffusers import CogVideoXPipeline from diffusers.utils import export_to_video如果运行无误,说明依赖安装成功。

三、上传模型与配置文件
除了代码和依赖,还需要上传CogVideoX模型文件和配置文件。以下是上传步骤:
-
访问官方模型仓库:https://huggingface.co/THUDM/CogVideoX-2b/tree/main,下载所有必要的模型和配置文件。

-
使用以下命令下载并解压模型文件:
cd /root/workspace wget http://file.s3/damodel-openfile/CogVideoX/CogVideoX-2b.tar tar -xf CogVideoX-2b.tar
四、开始运行
一切准备就绪后,可以开始运行CogVideoX。以下是运行步骤:
- 进入
CogVideo-main目录:cd /root/workspace/CogVideo-main - 运行
test.py文件:python test.py test.py文件中包含了使用CogVideoXPipeline生成视频的代码。例如:import torch from diffusers import CogVideoXPipeline from diffusers.utils import export_to_video prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest..." pipe = CogVideoXPipeline.from_pretrained("/root/workspace/CogVideoX-2b", torch_dtype=torch.float16).to("cuda") prompt_embeds, _ = pipe.encode_prompt(prompt=prompt, do_classifier_free_guidance=True, num_videos_per_prompt=1, max_sequence_length=226, device="cuda", dtype=torch.float16) video = pipe(num_inference_steps=50, guidance_scale=6, prompt_embeds=prompt_embeds).frames[0] export_to_video(video, "output.mp4", fps=8)- 运行成功后,可以在当前目录下找到生成的视频文件
output.mp4。
五、Web UI 演示
CogVideoX还提供了一个Web UI演示。以下是启动步骤:
- 进入
CogVideo-main目录:cd /root/workspace/CogVideo-main - 运行
gradio_demo.py文件:python gradio_demo.py - 运行后,访问本地URL http://0.0.0.0:7870 即可看到Web UI界面。
为了从外部访问这个Web UI,需要通过丹摩平台的端口映射功能将内网端口映射到公网:
- 进入GPU云实例页面,点击“操作” -> “更多” -> “访问控制”。
- 点击“添加端口”,添加7870端口。
- 添加成功后,通过提供的公网链接即可访问Web UI界面。
通过以上步骤,你可以成功部署并运行CogVideoX,生成高质量的视频内容。
















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











