







医院内跌倒的预测模型构建(Boruta+lightgbm+DCA分析)
跌倒有时候是很严重的事情,常常听说骨质疏松的老年人跌倒后造成髋骨骨折,导致长期卧床,进而导致肌肉萎缩、肺炎等等并发症,最终导致不良预后。医院内的跌倒也是相似的情况,而跌倒又是可以预防的事件,明确医院内跌倒的危险因素并进行预测,都会有助于预防医院内跌倒。数据集来自于dryad数据库,属于来自于临床的真实数据。
上篇文章中,我将分类预测模型分为两种类型,一类是直接预测类别,这类模型重视准确度等评价指标;另一类是将预测概率作为模型预测结果,重视校准曲线等评价指标。这里阐述后一类预测模型的构建流程,作为举例说明。完成代码请查看和鲸社区相关项目。
1. Boruta变量筛选
根据模型构建目的确定结局变量为是否发生了医院内跌倒。通过变量筛选迅速确定与结局指标相关的因素作为构建预测模型的预测变量。
library(Boruta)
#Boruta筛选变量
set.seed(1)
boruta_obj<-Boruta(event~.,data=data_m,doTrace=0,ntree=400,pValue=0.05)
print(TentativeRoughFix(boruta_obj))#分两类
print(boruta_obj)#三类,包含怀疑的数据

2. 构建临床预测模型
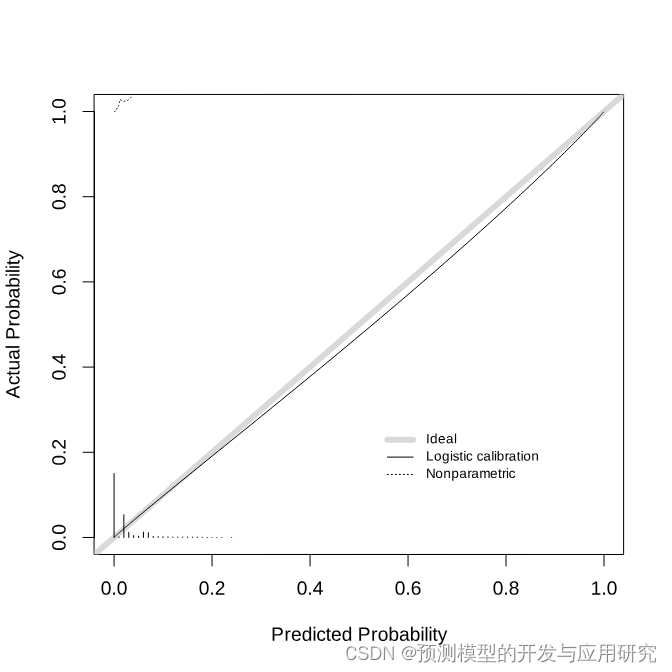
这一步唯一想说的就是下面的后概率校准过程。使用的是probably包,同时改善了ROC曲线和校准曲线的表现,而有一个良好的校准曲线是使用预测概率作为预测结果的前提条件。
#通过交叉验证进行模型评价
set.seed(345)
lightgbm_res_fit <-lightgbm_wf%>%
finalize_workflow(best_lightgbm)%>%
fit_resamples(resamples=cv_folds,metrics=cls_metrics,control=control_resamples(save_pred = TRUE))
lightgbm_res_fit %>%
collect_metrics()
# #
lg_predict_data <- lightgbm_res_fit %>%
collect_predictions()
# head(lg_predict_data)#用于dca分析的概率
logit_val <- cal_validate_logistic(lightgbm_res_fit, metrics = cls_metrics, save_pred = TRUE)
#矫正后的模型可以取metrics和probility
collect_metrics(logit_val)

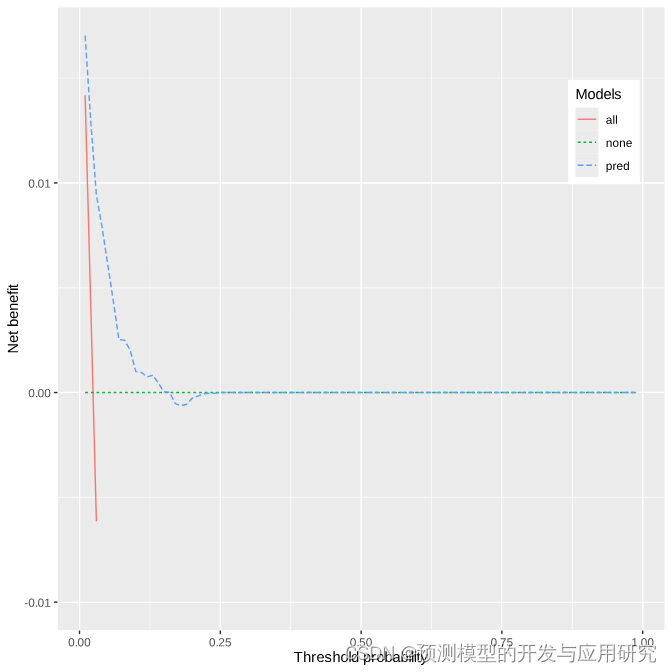
3. DCA分析确定决策阈值
DCA最大的价值在于确定决策阈值。图中可以看到模型的阈值仅在0-0.25之间才能产生临床收益,可以作为决策阈值的范围,具体的决策阈值可以在这个范围内确定。完整的代码中展示了如何通过概率来绘制决策曲线,就不局限与线性模型。因为跌倒数据集属于不平衡数据集,导致阈值范围偏一侧。
#借鉴代码,a method, this code was used to calculate the nb 。
ntbft<-function(data,outcome,frm=NULL,exterdt=NULL,pred=NULL,xstart=0.01,xstop=0.99,step=0.01,type="treated"){
#main func
pt<-seq(from=xstart,to=xstop,by=step)#生成threshold
lpt<-length(pt)
#type
if(type=="treated") coef<-cbind(rep(1,lpt),rep(0,lpt))
if(type=="untreated") coef<-cbind(rep(0,lpt),rep(1,lpt))
if(type=="overall") coef<-cbind(rep(1,lpt),rep(1,lpt))
if(type=="adapt") coef<-cbind(1-pt,pt)
#response
response<-as.vector(t(data[outcome]))#true_value
if(is.data.frame(exterdt)) response<-as.vector(t(exterdt[outcome]))# the nb of val data
event.rate<-mean(response)#?
nball<-event.rate-(1-event.rate)*pt/(1-pt)#ALL
nbnone<-1-event.rate-event.rate*(1-pt)/pt#none
#no pred, glm
if(is.null(pred)){
model<-glm(frm,data=data,family=binomial("logit"))
pred<-model$fitted.values
if(is.data.frame(exterdt))# val data
pred<-predict(model,newdata=exterdt,type="response")
}
# pred and response should be of the same length, pred and response was applied.计算NB
N<-length(pred)
nbt<-rep(NA,lpt)
nbu<-rep(NA,lpt)
for(t in 1:lpt){
tp<-sum(pred>=pt[t] & response==1)
fp<-sum(pred>=pt[t] & response==0)
fn<-sum(pred<pt[t] & response==1)
tn<-sum(pred<pt[t] & response==0)
nbt[t]<-tp/N-fp/N*(pt[t]/(1-pt[t]))
nbu[t]<-tn/N-fn/N*((1-pt[t])/pt[t])
}
nb<-data.frame(pt)#
names(nb)<-"threshold"
nb["all"]<-coef[,1]*nball
nb["none"]<-coef[,2]*nbnone
nb["pred"]<-coef[,1]*nbt+coef[,2]*nbu
return(nb)
}
plot.ntbft<-function(nb,nolines=2:dim(nb)[2], nobands=NULL,ymin=-0.01, ymax=max(nb[,c(nolines,nobands)],na.rm=T),
legpos=c(0.9,0.8)){
#主函数
ylow<-nb[,1]
yup<-nb[,1]
if(!is.null(nobands)){
ylow<-nb[,min(nobands)]
yup<-nb[,max(nobands)]
}
nb.melt<-melt(nb[,c(1,nolines)],
id.vars="threshold",
value.name="Netbenefit",variable.name="Models")
#绘图
print(ggplot(nb.melt)+
theme(legend.position=legpos)+
geom_line(aes(x=threshold,y=Netbenefit,
colour=Models,linetype=Models
))+
geom_ribbon(data=nb,aes(x=threshold,
ymin=ylow,ymax=yup),
linetype=2,alpha=0.2)+
scale_y_continuous(limits=c(ymin,ymax))+
xlab("Threshold probability")+ylab("Net benefit"))
}
4.最后
通过以上的步骤构建了一个临床预测模型,后续可以通过构建web APP 部署来方便临床实践,对医院内容易跌倒的人群进行预测,进而采取跌倒的保护措施,预防跌倒造成的危害。同时,建立相关的队列来评价预测模型是否能够产生临床影响,即是回答否保护了易跌倒的人群。在确认了这些之后,模型就可以进入到临床应用。
















 1785
1785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











