






脱发是一个复杂的问题,其中有许多危险因素可能导致脱发。某数据集收集了许多的变量,并以是否脱发作为结局变量,期望通过分析得出一定的结论。
本分析的目的是得出脱发相关的因素,随后使用相关的因素建立预测模型,最后对模型的输出做一定的解释。也借此展示一个数据的分析流程。
-
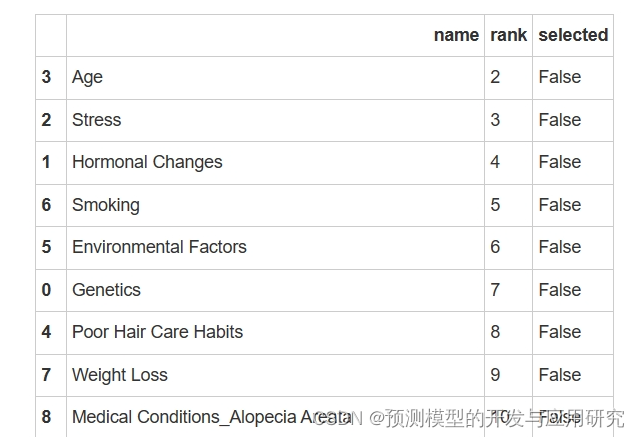
使用Boruta选择相关变量
Boruta是一种特征选择算法,它可以从众多的变量中选择与目标变量(在这里是脱发)相关的变量。它基于随机森林算法,通过对变量进行随机打乱和重新排列来检测变量的重要性。
使用Boruta算法对包含可能的脱发危险因素的数据集进行特征选择。该算法将根据随机森林的结果确定每个变量的重要性,并将其与其他变量进行比较。通过不断迭代,Boruta可以确定与脱发相关的变量。
这一步分析的作用可以让我们将注意力集中在相关的变量上,做到后续的分析有的放矢。
-
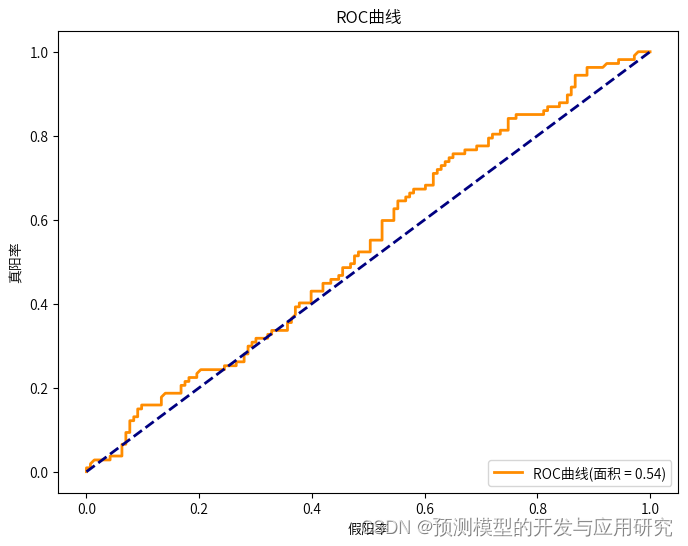
构建预测模型并进行评价
预测模型的构建是常规操作,并没有特殊的地方,这里从略。
-
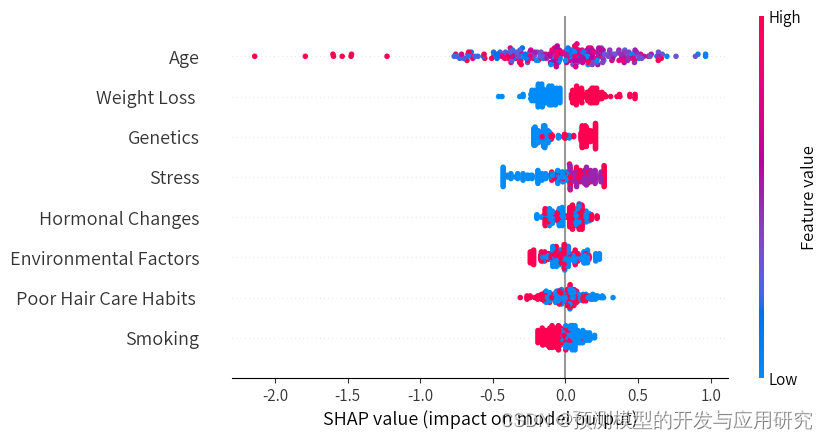
使用SHAP分析展示变量的贡献
SHAP(SHapley Additive exPlanations)是一种解释模型预测的方法。它可以对模型做三方面的解释:
-
1.每个变量对模型预测的贡献程度;年龄是相对比较相关的因素。
-
2.单个变量内部值的变化对其SHAP值的影响;年龄和SHAP值之间的趋势并不明显。
-
3.变量之间的交互作用。分析中显示年龄和激素变化之间有交互作用,从结果中可以看出45以上,激素变化会导致脱发的可能性增加
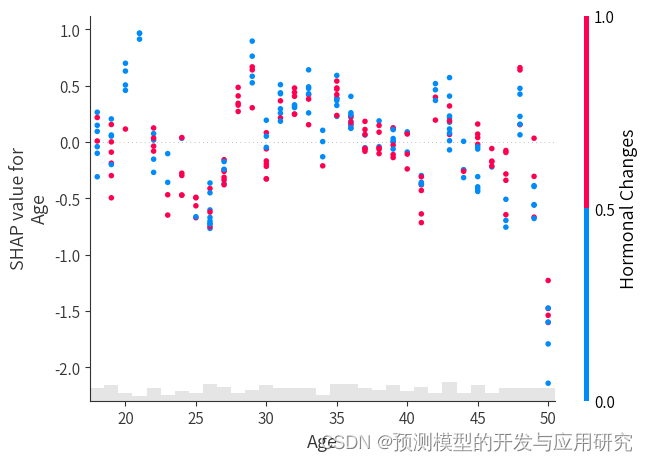
通过使用Boruta和SHAP分析,我们可以确定与脱发相关的危险因素,并了解每个因素对脱发的贡献程度。这样可以帮助我们识别和理解脱发的危险因素,从而采取相应的措施预防脱发的发生。
示例代码参见 和鲸社区示例代码


















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











