






背景:
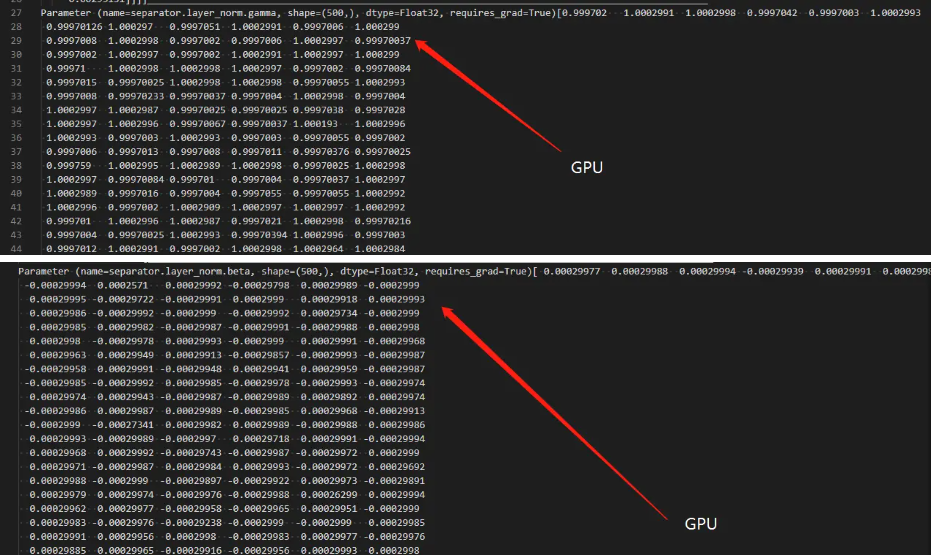
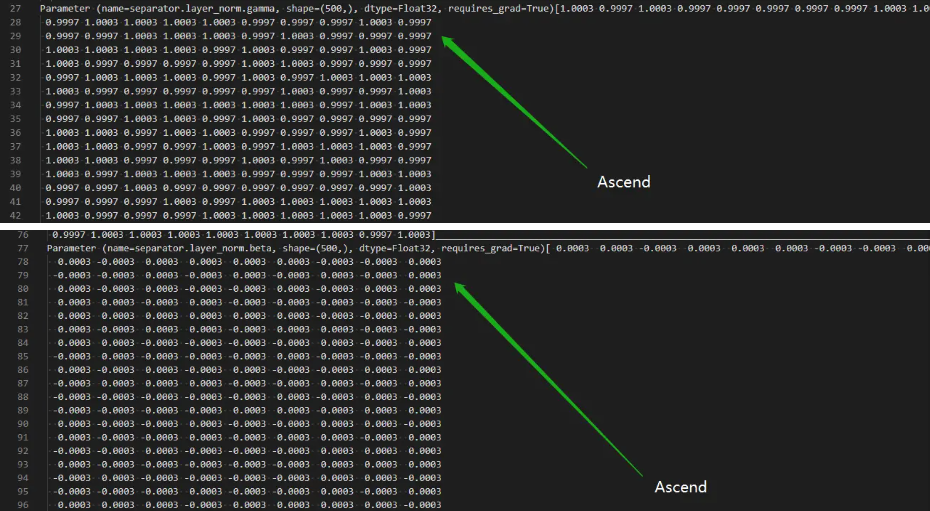
在模型迁移任务中,同样的代码在Ascend上和GPU上训练精度差了很多,在查找问题时发现layer_norm部分存在较大的精度差异,如何设置才能保证两个环境下精度一致?在gamma部分可以看到显示精度从小数点后第五位ascend直接四舍五入了,在beta部分更是产生了非常大的差异。
在模型迁移任务中,发现相同算子如conv1d表现出来存在一定的差别,怎么调整?
修改思路:
首先我们应该认识到不同机器存在差异是合理的。即算子计算在不同硬件上有误差很正常,友商也不会完全一样的。满足精度要求就是合理的结果,float32 是万分之一,float16 是千分之一。
其次我们要修改程序运行时的随机数,过去有过实验发现随机数在特定情况下会有一定影响。
最后我们要注意算子初始化的区别,即使是同名算子在不同框架下依然存在差异,如下图conv1d。

其中,上半部分为torch的conv1d初始化,下半部分为MindSpore的conv1d初始化,可以发现torch中它基于输入的相关信息构建了一个均匀分布的初始化。而MindSpore中则是对weight和bias分别使用了normal和zeros初始化,实测中发现不对初始化修正会对训练产生较大影响。
总之,在迁移任务中发现有精度差别和训练表现差异时可以优先尝试随机数和模型初始化对齐的思路。















 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









