







我们很多时候逛电商网站都会收到一些推销活动的通知,但是我们之前也没关注过那个商品,这些电商网站是为什么决定给我们推销这个商品的呢?这是因为电商网站,可以根据用户的年龄、性别、地址以及历史数据等等信息,将其分为,比如“年轻白领”、“一家三口”、“家有一老”、”初得子女“等等类型,然后你属于其中的某一类,电商网站根据这类用户的特征向其发起不同的优惠活动。那在利用用户的这些数据将用户分为不同的类别时,就会用到聚类分析。
聚类和分类是统计数据分析中的重要技术,聚类的定义即将一给定的大数据集聚为几个小的子数据集,并且每个子集(目标类)数据都具有共同或者相似特征。分类则是将一个或者多个未知类属的数据或特征向量划分到具有最接近特征的某个已知目标类别中。
实现聚类和分类的主要数学工具是距离测度,评价聚类效果的好坏依赖于两个因素:1.衡量距离的方法(distance measurement) 2.聚类算法(algorithm):
距离测度主要包括以下几类方法:
1.1数值变量(numerical)
计算数据之间距离的方法一般是根据数据的类型来选择的,数据的类型大概有数值变量,二元变量,类别变量,有序变量。

上述距离的计算方法中,每个变量x1,x2...的重要性相同,但是实际上变量的重要性之间存在区别,因此在计算距离时因引进了权重(就好比衡量一个人和另外一个人学习成绩差异的时候,语数外的成绩明显要比美术音乐的成绩更重要),所以引入马氏距离:
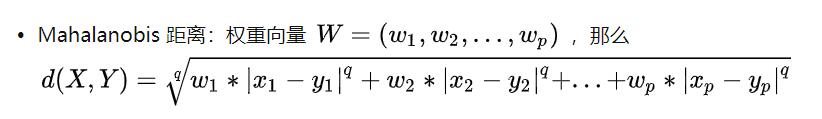
2.2二元变量
二元变量又分为对称二元变量和不对称二元变量。对称二元变量是指两个状态有相同的权重,比如性别,男性和女性就是对称二元变量。不对称二元变量时指两个状态的输出不是同样重要的,比如艾滋病阴性和阳性,阳性出现的几率更小。
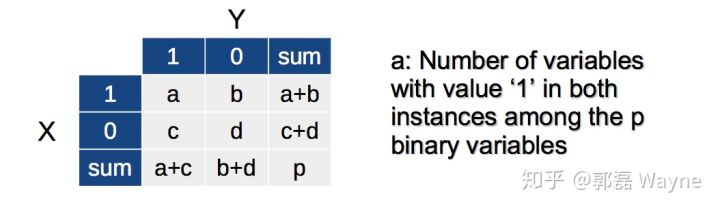
那二元变量的距离如何计算呢?------用列联表(contingency tabel),下面用一个例子解释更直观:
我们有三个同学,他们有不同的特征,我们想衡量他们哪一对特征是更接近的

我们首先将变量用0,1表示,这里我们只用到不对称二元变量来计算距离:

列联表是什么呢?我们建立了X,Y之间的列联表,a是X和Y同时都是1的次数,b是指Y是0,X是1的次数,c,d类似

2.3分类变量(categorical)

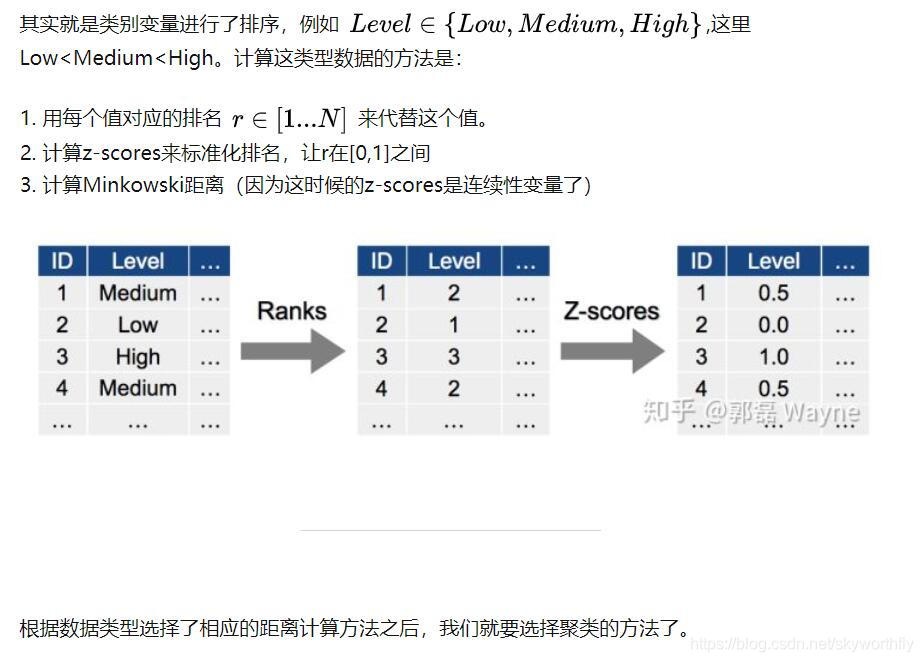
2.4有序变量(Ordinal)














 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









