









RNN初探(vanilla RNN)
前言
实习工作需要,不得不入个新坑。
为什么需要Recurrent Neuron Network (RNN)
全连接神经网络(FCN)和卷积神经网络(CNN)所针对的输入对象相互之间可以没有关系,不分先后顺序,比如如果要对猫和狗的图像进行分类,猫和狗的输入顺序是无所谓的。不过,如果要识别视频中狗的动作,那么就需要一个新的网络(当然这里就是RNN啦)来分析这种序列数据。
举例
序列数据其实在生活中无处不在:
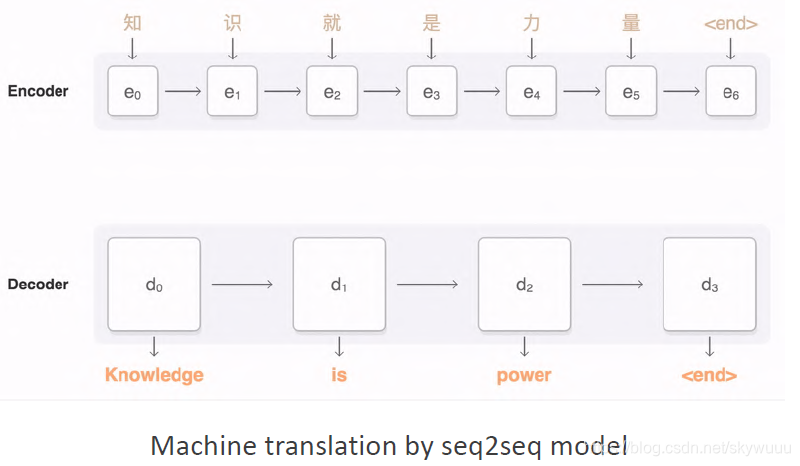
- 机器翻译
- 异常检测(图像)

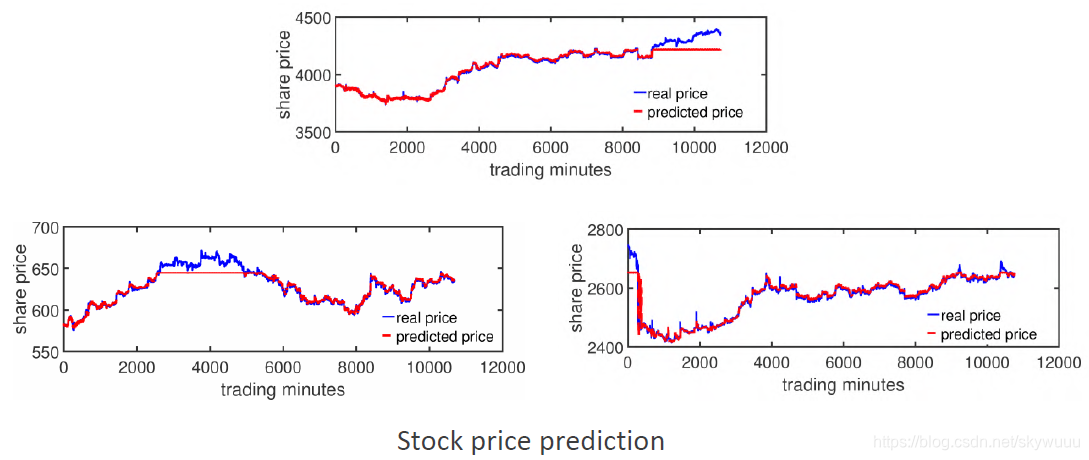
- 股票分析预测
- 天气与蚊虫繁殖的关系…
只要有序列数据,我们就可以用RNN来进行分析。
优点
- 无论序列长度如何,模型都月相同的输入大小 (same input size)
- 在每一步中都有可能使用相同的转换函数 f f f和相同的参数
RNN模型结构
输入
序列数据: x = [ x ( 1 ) , x ( 2 ) , . . . , x ( t ) , . . . , x ( τ ) ] \bold x = [\bold x^{(1)},\bold x^{(2)},..., \bold x^{(t)},...,\bold x^{(\tau)}] x=[x(1),x(2),...,x(t),...,x(τ)], t t t代表的是时间节点, τ \tau τ代表的是月 τ \tau τ个时间节点,每一个 x ( t ) x^{(t)} x(t)都是一个d维度的向量。
公式
h ( t ) = f ( h ( t − 1 ) , x ( t ) , θ ) \bold h^{(t)} = f(\bold h^{(t-1)}, \bold x^{(t)}, \theta) h(t)=f(h(t−1),x(t),θ), h ( t ) \bold h^{(t)} h(t)代表的是在时间节点 t t t的隐层(hidden layer), f f f是激活函数。这个公式的意思是:在时间节点t的隐层和在时间节点t的输入,上一个时间节点(t-1)的隐层以及一个 θ \theta θ(所有参数的统计,h和x拼起来之后乘一个W得到下一个h,简单来说W和b就是 θ \theta θ)有关,所以这个公式确实表达了序列数据中输出结果与先后顺序有关的这种思想。
结构
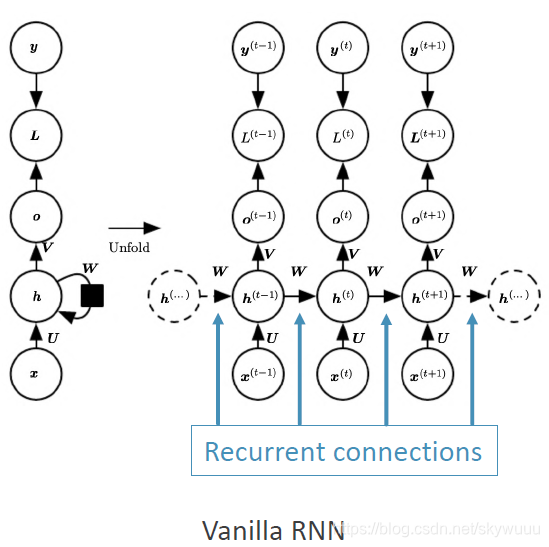
左侧是将隐层折叠起来的样子,其实很好理解。
x
x
x就是输入的序列数据,
h
h
h代表了所有隐层,
o
o
o就是输出(预测结果)了,
L
L
L是loss,
y
y
y就是真实数据(标签)。(注意:
y
y
y->
L
L
L<-
o
o
o表示
y
y
y和
o
o
o进行比较得到Loss)
接下来是三个权重矩阵:
U
U
U代表从输入到隐层(input-to-hidden)的权重矩阵,
W
W
W代表从一个隐层到下一个隐层(hidden-to-hidden)的权重矩阵,
V
V
V代表了从最后一个隐层到输出(hidden-to-output)的权重矩阵。
右侧是将隐层展开,我们可以发现
U
U
U,
W
W
W,
V
V
V三者全是相同的,这也就是在前面优点中所提到的,或者其实就是参数共享。其次,在每一个时间节点
t
t
t下,有
x
(
t
)
,
h
(
t
)
,
o
(
t
)
,
L
(
t
)
,
y
(
t
)
x^{(t)}, h^{(t)},o^{(t)},L^{(t)},y^{(t)}
x(t),h(t),o(t),L(t),y(t)一一对应。
了解了最基础的RNN结构,之后对双向RNN,多层的RNN的理解也会变得更容易。
前向传播(forward propagation)
公式
从时间节点
t
=
1
t=1
t=1到
t
=
τ
t=\tau
t=τ,前向传播是以下面的方式进行的:
a
(
t
)
=
b
+
W
h
(
t
−
1
)
+
U
x
(
t
)
\bold{a^{(t)} = b + Wh^{(t-1)}+Ux^{(t)}}
a(t)=b+Wh(t−1)+Ux(t)
h
(
t
)
=
tanh
(
a
(
t
)
)
\bold{h^{(t)}} = \tanh\bold{(a^{(t)})}
h(t)=tanh(a(t)),
tanh
\tanh
tanh作为激活函数
o
(
t
)
=
c
+
V
h
(
t
)
\bold{o^{(t)} = c + Vh^{(t)}}
o(t)=c+Vh(t)
y
^
(
t
)
=
s
o
f
t
m
a
x
(
o
(
t
)
)
\bold{\hat{y}^{(t)}} = softmax(\bold{o^{(t)}})
y^(t)=softmax(o(t))
L
(
t
)
=
J
(
y
^
(
t
)
,
y
(
t
)
)
L^{(t)} = J(\bold{\hat{y}^{(t)},y^{(t)}})
L(t)=J(y^(t),y(t)),
J
J
J作为计算loss的函数(
L
2
L_2
L2或者交叉熵等等)
RNN的前向传播其实和CNN的大同小异
反向传播(back-propagation through time)
公式
大家应该注意到了,RNN的反向传播的名字是BPTT,比CNN多了个TT,其实就是多了一个从时间尽头向时间开始反向传播的通道,下面我们来介绍一下BPTT吧。

从图上看其实非常显而易见,就是要找那几个红色的梯度加上在前向传播中引入的
b
b
b和
c
c
c的梯度。也就是:
∇
V
L
,
∇
W
L
,
∇
U
L
,
∇
b
L
,
∇
c
L
\nabla_\bold{V}L,\nabla_\bold{W}L,\nabla_\bold{U}L,\nabla_\bold{b}L,\nabla_\bold{c}L
∇VL,∇WL,∇UL,∇bL,∇cL
公式如下:
∇
c
L
=
∑
t
∇
o
(
t
)
L
\nabla_\bold{c}L=\sum_{t}\nabla_\bold{o^{(t)}}L
∇cL=∑t∇o(t)L
∇
b
L
=
∑
t
d
i
a
g
(
1
−
(
h
(
t
)
)
2
)
∇
h
(
t
)
L
\nabla_\bold{b}L=\sum_{t}diag(1-(\bold{h}^{(t)})^2)\nabla_\bold{h^{(t)}}L
∇bL=∑tdiag(1−(h(t))2)∇h(t)L (
d
i
a
g
(
)
diag()
diag()代表对角矩阵,也就是除了对角线,其他位置全是0)
∇
V
L
=
∑
t
(
∇
o
(
t
)
L
)
h
(
t
)
T
\nabla_\bold{V}L=\sum_{t}(\nabla_\bold{o^{(t)}}L)\bold{h}^{(t)^T}
∇VL=∑t(∇o(t)L)h(t)T
∇
W
L
=
∑
t
d
i
a
g
(
1
−
(
h
(
t
)
)
2
)
(
∇
h
(
t
)
L
)
h
(
t
−
1
)
T
\nabla_\bold{W}L=\sum_{t}diag(1-(\bold{h}^{(t)})^2)(\nabla_\bold{h^{(t)}}L)\bold{h}^{(t-1)^T}
∇WL=∑tdiag(1−(h(t))2)(∇h(t)L)h(t−1)T
∇
U
L
=
∑
t
d
i
a
g
(
1
−
(
h
(
t
)
)
2
)
(
∇
h
(
t
)
L
)
x
(
t
−
1
)
T
\nabla_\bold{U}L=\sum_{t}diag(1-(\bold{h}^{(t)})^2)(\nabla_\bold{h^{(t)}}L)\bold{x}^{(t-1)^T}
∇UL=∑tdiag(1−(h(t))2)(∇h(t)L)x(t−1)T

















 1996
1996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









