







InnerProductLayer 也是主要为三部分:初始化,前向传播,后向传播。
1. LayerSetUp()
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num_output = this->layer_param_.inner_product_param().num_output();
bias_term_ = this->layer_param_.inner_product_param().bias_term();
transpose_ = this->layer_param_.inner_product_param().transpose();
N_ = num_output; // N为输出节点数
const int axis = bottom[0]->CanonicalAxisIndex( //axis 默认值为1,注意,这个axis=1表示从第二维度开始,因为axis是从0开始的。
this->layer_param_.inner_product_param().axis());
// Dimensions starting from "axis" are "flattened" into a single
// length K_ vector. For example, if bottom[0]'s shape is (N, C, H, W),
// and axis == 1, N inner products with dimension CHW are performed.
K_ = bottom[0]->count(axis); // K = C * H * W。
// Check if we need to set up the weights
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// Initialize the weights
vector<int> weight_shape(2);
if (transpose_) {
weight_shape[0] = K_;
weight_shape[1] = N_;
} else {
weight_shape[0] = N_; //weight 的 blob 为N x K
weight_shape[1] = K_;
}
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get()); //weight 数值初始化
// If necessary, intiialize and fill the bias term
if (bias_term_) {
vector<int> bias_shape(1, N_);
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get()); // bias 数值初始化
}
} // parameter initialization
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
2.Reshape()
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Figure out the dimensions
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
const int new_K = bottom[0]->count(axis); // new_K = K
CHECK_EQ(K_, new_K)
<< "Input size incompatible with inner product parameters.";
// The first "axis" dimensions are independent inner products; the total
// number of these is M_, the product over these dimensions.
M_ = bottom[0]->count(0, axis); // M为 bottom 的num,即batch_size
// The top shape will be the bottom shape with the flattened axes dropped,
// and replaced by a single axis with dimension num_output (N_).
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1);
top_shape[axis] = N_; //top_shape 为 M x N即(num, num_output),这个num为batch_size,而num_output 为单个picture 输出的全连接的vector 的长度
top[0]->Reshape(top_shape);
// Set up the bias multiplier
if (bias_term_) {
vector<int> bias_shape(1, M_); //bias_shape 为 1x M
bias_multiplier_.Reshape(bias_shape); //bias_multiplier_的数值全为1
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data());
}
}
3.Forward()
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
const Dtype* weight = this->blobs_[0]->cpu_data();
caffe_cpu_gemm<Dtype>(CblasNoTrans, transpose_ ? CblasNoTrans : CblasTrans,
M_, N_, K_, (Dtype)1., //矩阵运算
bottom_data, weight, (Dtype)0., top_data);
if (bias_term_) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,
bias_multiplier_.cpu_data(),
this->blobs_[1]->cpu_data(), (Dtype)1., top_data);
}
}
weight 项:
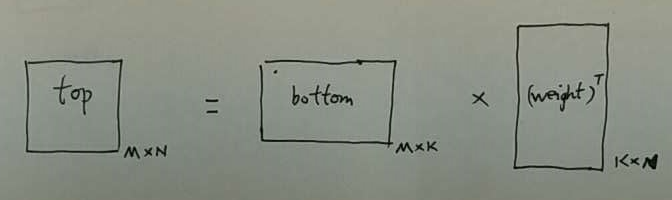
bias 项:
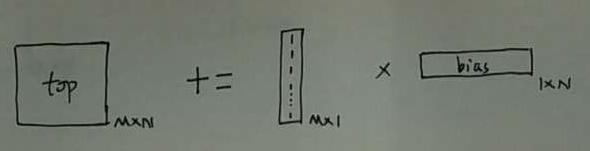
在前向传播中,没有涉及梯度。所以这里的bottom 和 top 分别指的是 bottom_data 和 top_data. weight 和 bias 同理。
我们再来分析一下 caffe_cpu_gemm() 函数:
对于 C += A* B。
A, B, C 三个矩阵,三个形参 M, N, K:
M:A的行数, C的行数
N:B的列数, C的列数
K:A的列数, B的行数
在 CblasRowMajor (对Blob 按行主序进行展开)的基本条件下,CblasNoTrans 表示不需要转置,而CblasTrans则需要转置。也就相当于:
CblasRowMajor + CblasNoTrans :按 行主序 展开
CblasRowMajor + CblasTrans :按 列主序 展开
而关于 CblasTrans 的前后两个形参分别对应A 和B是否需要转置。
此外,InnerProductLayer 和 ConvolutionLayer 比较,在利用 gemm 进行矩阵运算时,前者可以对整个Blob进行计算,而后者出于内存的考虑,只能在for循环里,对batch_size 的每一张图分别进行矩阵运算。
4. Backward()
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (this->param_propagate_down_[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* bottom_data = bottom[0]->cpu_data();
// Gradient with respect to weight
if (transpose_) {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
K_, N_, M_,
(Dtype)1., bottom_data, top_diff,
(Dtype)1., this->blobs_[0]->mutable_cpu_diff());
} else {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, //计算 weight 的梯度
N_, K_, M_,
(Dtype)1., top_diff, bottom_data,
(Dtype)1., this->blobs_[0]->mutable_cpu_diff());
}
}
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->cpu_diff();
// Gradient with respect to bias
caffe_cpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff, //计算bias 的梯度
bias_multiplier_.cpu_data(), (Dtype)1.,
this->blobs_[1]->mutable_cpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
// Gradient with respect to bottom data
if (transpose_) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->cpu_data(),
(Dtype)0., bottom[0]->mutable_cpu_diff());
} else {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, //计算 bottom_diff 的梯度
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->cpu_data(),
(Dtype)0., bottom[0]->mutable_cpu_diff());
}
}
}
weight_diff:

bias_diff :
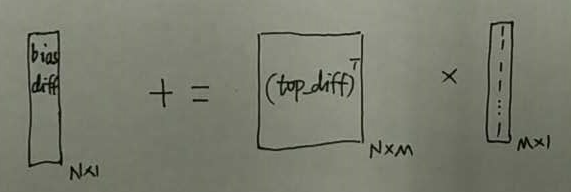
因为 bias_diff 是个向量,所以bias_diff 无论表示成行向量还是列向量,在连续的内存中都是一样的顺序。
bottom_diff :
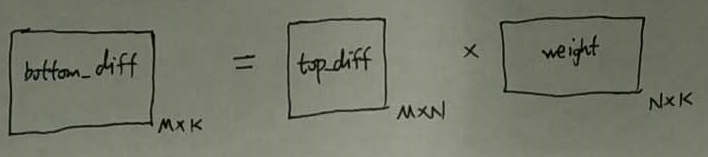
我们来分析一下caffe_cpu_gemv() 函数:
对于 y += Ax。
A为矩阵,x 为输入向量,y 为输出向量。M,N 两个形参:
M: x 的行数(即输入vector的长度),A的列数
N: y 的行数(即输出vector的长度),A的行数
关于数学公式的由来,这里不做解释。可以自行推导。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









