







SoftmaxLayer
1. softmax 的数学公式如下:
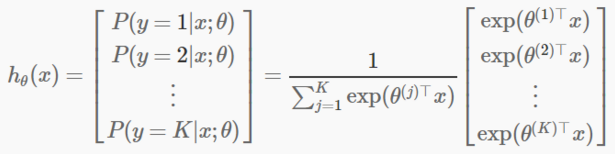
所以,softmax 的输入和输出的 blob 形状大小是一样的。
2. forward()
template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = bottom[0]->shape(softmax_axis_);
int dim = bottom[0]->count() / outer_num_;
caffe_copy(bottom[0]->count(), bottom_data, top_data); //先将bottom_data拷贝到top_data,方便后续计算
// We need to subtract the max to avoid numerical issues, compute the exp, 为了避免指数爆炸问题,首先用scale_data[0](假设inner_num_=1) 来记录每个样本所有channel 上的最大值
// and then normalize.
for (int i = 0; i < outer_num_; ++i) {
// initialize scale_data to the first plane
caffe_copy(inner_num_, bottom_data + i * dim, scale_data);
for (int j = 0; j < channels; j++) {
for (int k = 0; k < inner_num_; k++) {
scale_data[k] = std::max(scale_data[k],
bottom_data[i * dim + j * inner_num_ + k]);
}
}
// subtraction 先实现top_data = bottom_data - max(bottom_data)
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_,
1, -1., sum_multiplier_.cpu_data(), scale_data, 1., top_data);
// exponentiation 再求exp(top_data)
caffe_exp<Dtype>(dim, top_data, top_data);
// sum after exp 然后计算用于归一化的分母记录于 scale_data,利用gemv 计算
caffe_cpu_gemv<Dtype>(CblasTrans, channels, inner_num_, 1.,
top_data, sum_multiplier_.cpu_data(), 0., scale_data);
// division 最后是归一化, top_data = top_data / scale_data
for (int j = 0; j < channels; j++) {
caffe_div(inner_num_, top_data, scale_data, top_data);
top_data += inner_num_;
}
}
}
为什么要防止指数爆炸? 为什么会指数爆炸?
因为bottom_data的值是
θ 和 x 的内积,可能值很大,如果直接求exp的话,我们知道,指数函数的正半轴的增长很快,那么求得的 top_data = exp(bottom_data) 可能会溢出。就算没有溢出,这时候的 top_data 也会很大。那么我们在计算用于归一化的分母项的时候,累计结果也会很大,则存在溢出的可能。
防止指数爆炸的原理:

根据上图可以知道,
exp( bottom_data - max(bottom_data) ) 等价于 exp(bottom_data) / exp(max(bottom_data))。
且不影响求h(x) 的结果。
这时候,我们先把bottom_data - max(bottom_data) 后,各项都小于等于0,那么再求exp 的时候,top_data 都是小于等于 1 的值。这时候再对top_data进行归一化,则不会存在指数爆炸,不存在溢出的可能性。
3. backward()
template <typename Dtype>
void SoftmaxLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* top_data = top[0]->cpu_data();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
Dtype* scale_data = scale_.mutable_cpu_data();
int channels = top[0]->shape(softmax_axis_);
int dim = top[0]->count() / outer_num_;
caffe_copy(top[0]->count(), top_diff, bottom_diff); //先将 top_diff 拷贝到bottom_diff,方便后续计算
for (int i = 0; i < outer_num_; ++i) {
// compute dot(top_diff, top_data) and subtract them from the bottom diff
for (int k = 0; k < inner_num_; ++k) {
scale_data[k] = caffe_cpu_strided_dot<Dtype>(channels, // 求bottom_diff (实际指top_diff) 和top_data 的内积
bottom_diff + i * dim + k, inner_num_,
top_data + i * dim + k, inner_num_);
}
// subtraction 这里是 top_diff 减去 内积
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_, 1,
-1., sum_multiplier_.cpu_data(), scale_data, 1., bottom_diff + i * dim);
}
// elementwise multiplication 上面的结果 和 top_data 进行点乘得到最终的 bottom_diff
caffe_mul(top[0]->count(), bottom_diff, top_data, bottom_diff);
}
关于softmax 的后向传播公式推导,可以看下图:
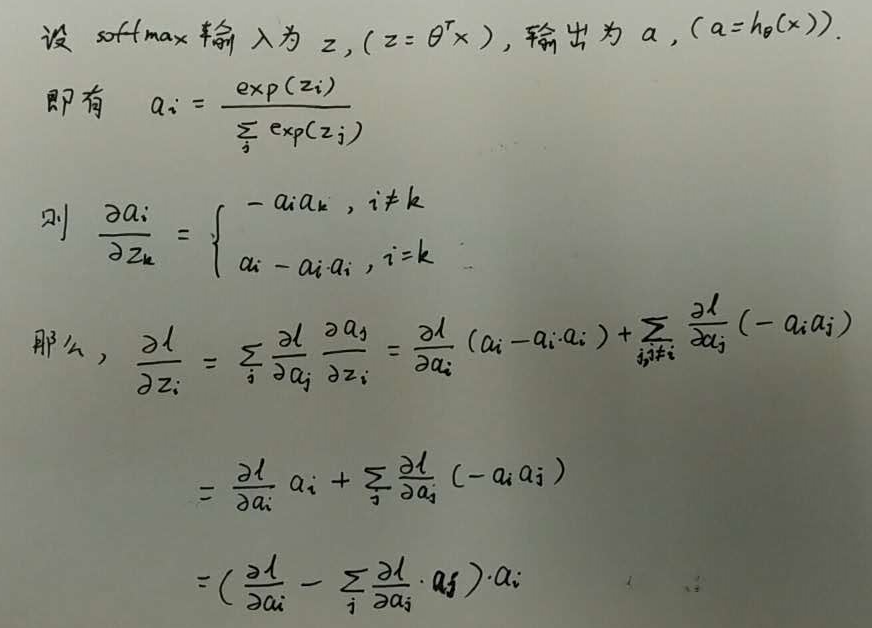
caffe 里的代码如何对应上面的公式呢?大家看上图中最下面的式子, 实现该公式 caffe 中主要有以下三步:
scale_data[k] = caffe_cpu_strided_dot<Dtype>(channels,
bottom_diff + i * dim + k, inner_num_,
top_data + i * dim + k, inner_num_);
}
这里对应于括号里减号右边一项,求的是一个 top_diff 和 top_data 的内积。
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_, 1,
-1., sum_multiplier_.cpu_data(), scale_data, 1., bottom_diff + i * dim);
这里对应括号中相减的过程。
caffe_mul(top[0]->count(), bottom_diff, top_data, bottom_diff);
这里对应括号中的计算结果与 top_data 的点乘。
关于 caffe_cpu_strided_dot()、caffe_mul()、caffe_cpu_gemm() 等的介绍,可以参考这个博客:















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









