







 本文详细介绍了如何在PyTorch中使用TensorDataset和DataLoader对数据进行批处理,包括设置batch_size、shuffle选项,以及其对模型训练效果的影响。通过实例展示了不同shuffle设置下的训练过程和结果。
本文详细介绍了如何在PyTorch中使用TensorDataset和DataLoader对数据进行批处理,包括设置batch_size、shuffle选项,以及其对模型训练效果的影响。通过实例展示了不同shuffle设置下的训练过程和结果。
前言
本文主要介绍pytorch里面批数据的处理方法,以及这个算法的效果是什么样的。具体就是要弄明白这个批数据选取的算法是在干什么,不会涉及到网络的训练。
先说明一下批数据训练和直接全部数据训练的区别吧!
批数据训练在神经网络训练中有几个重要的好处:
- 减少内存需求和计算成本: 批数据训练允许我们一次性处理一小批数据,而不是整个数据集。这样可以大大减少每次迭代所需的内存和计算资源。特别是对于大型数据集和复杂的神经网络结构,批数据训练可以显著提高训练效率。
- 加速收敛过程: 批数据训练通常比在线数据训练(即逐个样本训练)更快地推进训练过程。每一轮迭代都考虑了批中多个样本的信息,有助于更稳定和快速地优化模型参数,从而加速收敛速度。
- 降低梯度方差: 批数据训练可以减少梯度更新的方差。在每个小批次中,梯度的计算是基于多个样本的,因此梯度的方向和大小更加稳定。这有助于更加可靠地更新模型参数,减少训练过程中的震荡。
- 实现并行化处理: 批数据训练更容易实现并行化处理。可以同时处理多个批次,每个批次可以在不同的计算单元或GPU上并行计算,从而进一步提高训练效率和速度。
总之,批数据训练通过减少计算负担、加速收敛过程、降低梯度方差以及实现并行化处理,显著改善了神经网络的训练效率和稳定性。
需要用到的模块
from torch.utils.data import DataLoader, TensorDataset
主要实现就是上面的数据集和数据载入两个类来实现该算法功能,这里只要求会调用接口就够了。
一、生成数据集
import torch
from torch.utils.data import TensorDataset, DataLoader
# 准备数据集与定义batch_size
batch_size = 8
x = torch.linspace(1,10,10)
y = torch.linspace(10,1,10)
print(x)
print(y)
输出:
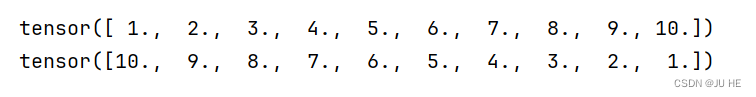
二、将训练数据进行batch处理
# 将训练数据放入torch的数据集
train_dataset = TensorDataset(x, y)
# 载入batch批次选取数据规则
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True, # True表示每一个epoch都打乱抽取
num_workers=2 # 定义工作线程个数
)
三、epoch训练
# 训练模型
epochs = 3
for epoch in range(epochs):
# 每一个epoch表示将整个数据集所有数据都训练一遍
for step,(batch_x, batch_y) in enumerate(train_loader):
# training......
# 这里用enumerate是为了让你更加情况观察,batch的逻辑是怎么样的
# 实际中只要 for batch_x,batch_y in train_loader就可以了
print('Epoch:',epoch,'| Step:',step,'| batch x:',batch_x.data.numpy(),'| batch y:',batch_y.data.numpy())
# 测试模型(略)
输出:

【注】:可以看到每一个epoch将所有样本点都涉及到了一次,并且还是打乱顺序了的。
下面看看将shuffle=False不打乱顺序会发生什么:

【注】:可以看到每一个epoch,都是相同的结果,可想而知这样训练效果肯定没有打乱的好。
注意到,上半batch=5,恰好将样本总数10均分为2分,那么要是不能均分会发生什么,下面将batch=8,看看会发生什么。

可以看到直接将不够的组就直接剩下的了。
总结
后面我们会经常用到这种batch和epoch的训练方法。

















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









