






思考:
核心需求:在不明显降速的前提下,让GPU显存占用量尽可能减少;
带宽:GPU显存带宽>CPU主存带宽>GPU和CPU之间的PCI-E总线带宽;相邻相差1个数量级;
CPU不擅长计算密集型任务(任务中,计算量和访存量的比例)。Forward、Backward的矩阵乘法,时间复杂度是O(BM),B:Batch-size, M:Model weight size; Optimizer更新算法、量化,时间复杂度是O(M);因此,前者适合GPU来计算,后者适合CPU来计算。
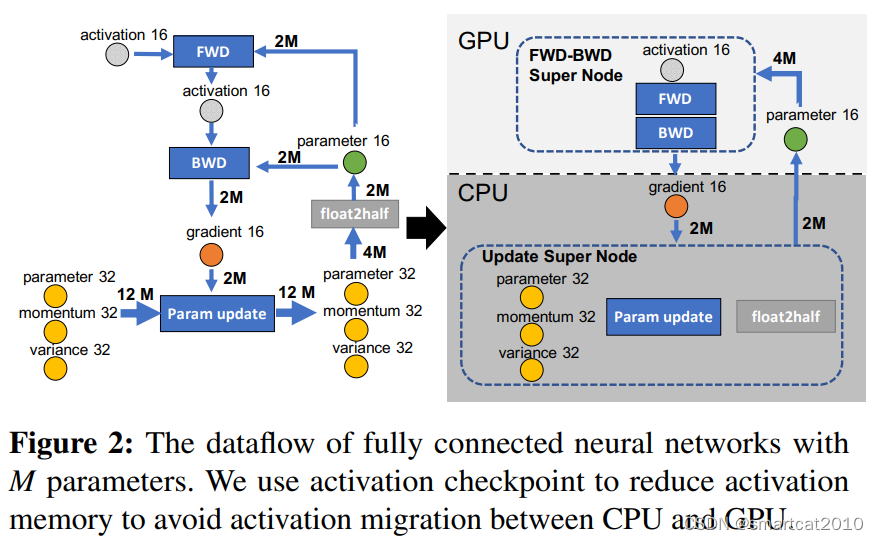
GPU上的是FP16的model、activation;
CPU上的是FP32的model、gradient、optimizer-states和FP16的gradient;
CPU和GPU的数据传输,全部是FP16的,省带宽速度快!
Activation checkpoint: Backward时需要用到的activation,可以checkpoint到CPU内存保存一会儿,Backward用的时候再swap到GPU显存;(可以用gradient checkpointing只保存lgN层的激活值,backward时相当于重新计算一遍forward)
图右上角,为什么是4M而不是2M?
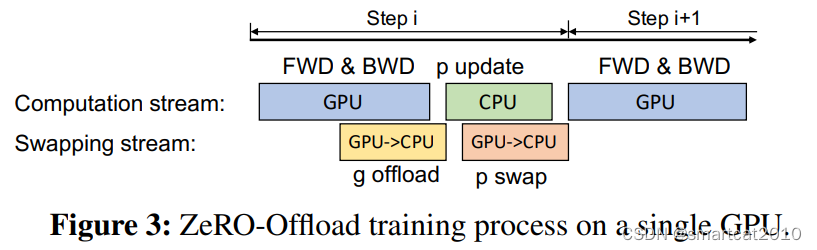
单卡:
Overlap一部分的计算和传输:
Gradients: Backward的时候,每算出来一部分(partition),就reduce到某一个GPU里去;该GPU再offload到CPU内存里去;update model时直接在CPU内存里计算;
我:可以每收到一层gradient,就更新该层的weights、optimizer;为什么要全部gradient都接收到之后才开始计算?
多卡:
也就是Zero-2 + Offloading;
- 梯度加和:Reduce-Scatter,每次Reduce 1/N的gradient,发到负责的那个rank上;
- GPU每得到一小块儿的reduced gradient,马上发送给CPU,不保留大块在GPU;
- CPU上将梯度FP16-->FP32,optimizer状态和weight更新;再将weight进行FP32-->FP16,传输至GPU;
- 权重凑齐:FP16的weights,每个rank只有1/N,进行一遍AllGather,得到完整weights;

One step delay:
注意:刚开始的N-1轮梯度快速变化,如果采用one step delay,会造成训练效果不稳定;所以,从第N步开始,才用这招。
CPU在更新第N个batch的states时,GPU不等待,直接用之前的weights,计算Forward和Backward;什么时候收到了第N个batch的weights,下一轮用之;

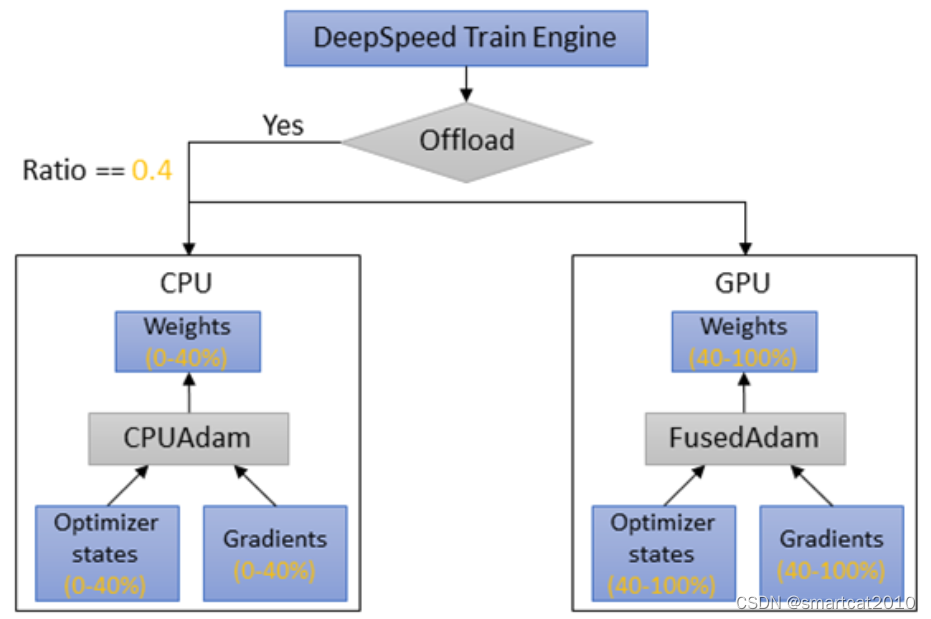
Zero Offload++
痛点:gradients GPU-->CPU、Optimizer更新、weights CPU-->GPU,这期间,GPU在闲着;
解决:一部分optimizer状态放在GPU上,另一部分放在CPU上;两者并行更新;
我:前提是GPU memory够用;这相当于又把庞大的optimizer的参数们的一部分放到显存了,不那么ZeRO了;















 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









