








DeepSpeed: Extreme-scale model training for everyone - Microsoft Research
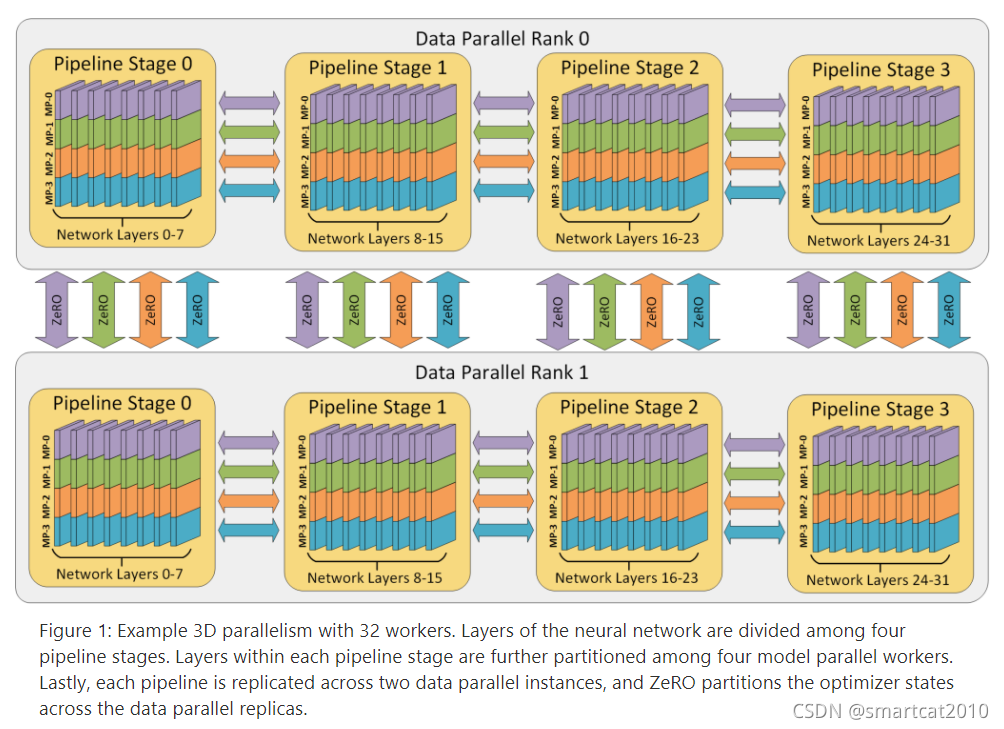
Why model-parallelism is most communication cost?
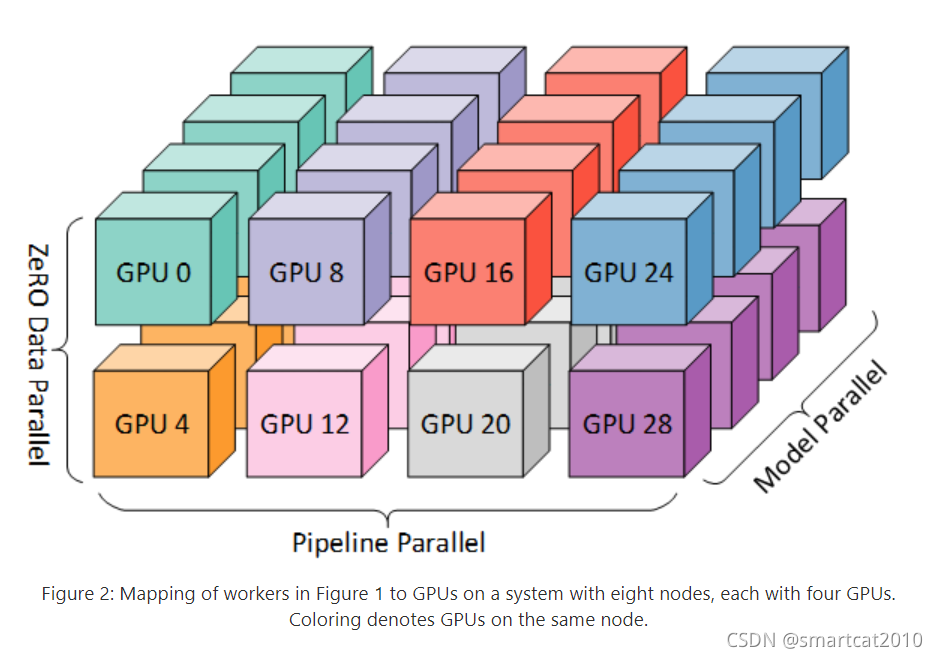
动图演示:【大规模训练】Optimizer state sharding (ZeRO) - 掘金 (juejin.cn)
朴素的Zero-1、2、3,指参数们全部在GPU显存上,不利用任何CPU-Memory-Offloading;
Baseline(上图第1行):FP16的weight和gradient;FP32的optimizer状态(weight、2组参数)
Zero-1(上图第2行):Gradient还是完整的AllReduce;更新完自己这部分weight后,新增了AllGather让所有rank都拿到最新的weight;
Zero-2(上图第3行):Gradient分成N份,每个rank只保存自己那份;原来对完整梯度的AllReduce,变成了N次对1/N梯度的Reduce(也就是Reduce-Scatter);其余同上;
Zero-3(上图第4行): Weight分成N份,每个rank只保存自己那份;每次forward、backward之前,都要把该层的weight进行AllGather,使得每个rank都有该层完整的weight,才能计算。
实际上,Gradient在每层完成weight更新之后,就可以删除释放显存了,同一时刻最多只保留一层即可。我不知道为什么Zero-1需要gradient占用跟weight同样大小的空间。对于Zero-2,我认为可以每次Reduce完1/N,不负责这1/N的其余N-1个rank,可以释放掉该1/N梯度;

通信开销(按照数据move量来统计):
0. 原始版,每轮只有1次所有gradient的AllReduce;AllReduce的state-of-art实现:先Reduce-Scatter,再AllGather; 两者都是pipeline实现的
Reduce-Scatter: 两种实现方式:
1. 每轮发送skip加1(1-bit quantization所用):所有节点先向id-1发送(3, 0, 1, 2)号数据包;再向id-2发送(2, 3, 0, 1)号数据包;再向id-3发送(1, 2, 3, 0)号数据包,至此,0号节点包含所有0号包,1号节点包含所有1号包...加和即可;设S为每个节点上的所有数据,N为节点数,则,每个节点发送数据为(N-1)*S/N约等于S,每个节点接收数据为(N-1)*S/N约等于S
2. Ring-AllReduce的前半部分,每轮发送skip都是1;
All-Gather: 也是两种方式,类似上面;每个节点发送、接收数据量,都为S;
综上,原始版的两者加起来,对每个节点,发送数据量和接收数据量都是S+S=2S;
2. Zero-2:
1. 先对Gradient做Reduce-Scatter; 同上,每个节点,发送、接收数据量,都是S;
2. 每个节点用从所有节点接收到的“属于自己”的partial梯度,加和之后,更新“属于自己”的optimizer状态和weight;通信量为0;
3. 每个节点,对“属于自己”的partial weight,进行AllGather;同上,每个节点,发送、接收数据量,都是S;
综上,Zero-2的1和3加起来,每节点的单向通信数据量是S+S=2S;
3. Zero-3:
1. Forward时,每一层,每个节点要把所有weight都凑齐,所以是个AllGather通信;所有层,每个节点,总通信量为S;(实际中,每层的通信可以和上一层的计算,overlap起来);
2. Backward时,同上,weight总通信量为S;
3. Backward时,同Zero-2,gradient的通信操作是Reduce-Scatter,总通信量为S;
综上, Zero-3的1、2、3加起来,每节点的单向通信数据量是S+S+S=3S;
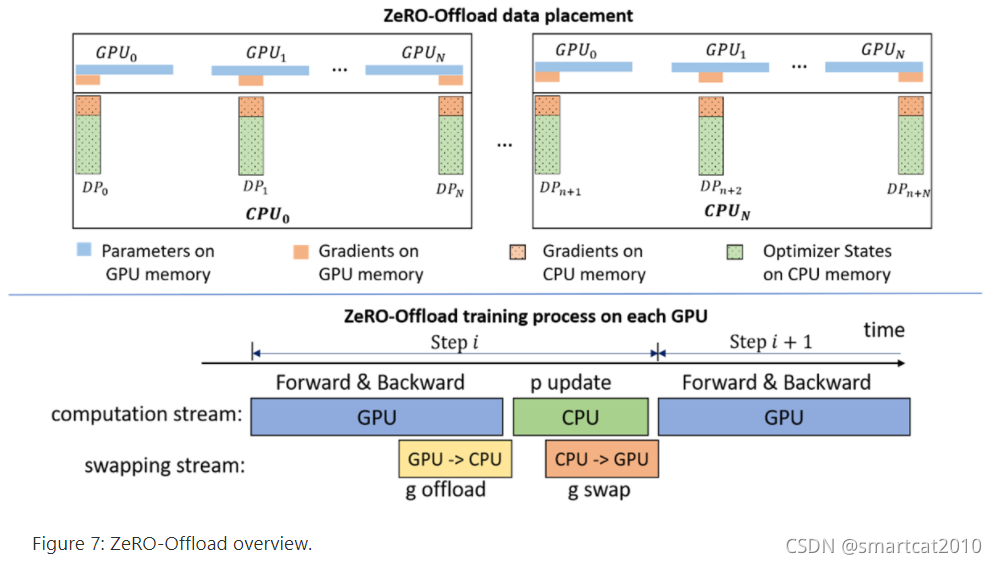
模型参数在CPU上有一份(只保留自己这个GPU的partition即可);update的时候直接把offload到CPU上的gradients以及常驻CPU内存的optimizer-states, 更新到同样在CPU内存里的模型参数,然后把模型参数swap到GPU上,最后要调GPU的allgather来让所有GPU上的weight-partition都gather到所有GPU上;
Forward&Backward, gradient offload(GPU->CPU), update model, swap(CPU->GPU), 这几个环节之间可以pipeline/overlapped执行!
- Gradients: Backward的时候,每算出来一部分(partition),就reduce到某一个GPU里去;该GPU再offload到CPU内存里去;update model时直接在CPU内存里计算;
- Optimizer states: 每个进程存自己的partition; 常驻CPU内存;update model时既做输入,也做输出;
- Model wegiths: 整个模型常驻GPU显存(我认为,可以每次swap进来几层即可(ZeRO-Infinity?));每个进程把自己那份partition常驻在CPU内存;
GPU上的是FP16的model、activation、gradient;
CPU上的是FP32的model、gradient、optimizer-states;
CPUßàGPU的数据传输,全部是FP16的,省带宽速度快!
Activation checkpoint: Backward时需要用到的activation,可以checkpoint到CPU内存保存一会儿,Backward用的时候再swap到GPU显存;
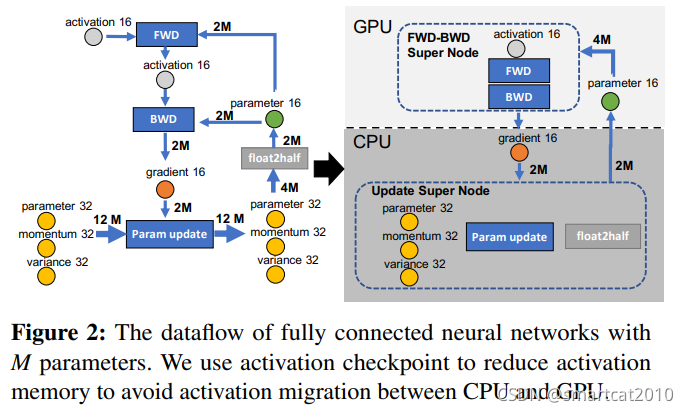
以上Zero Offload就是Zero-3
分层来取,是Zero Infinity
DeepSpeed 本质上是一种“节省显存”的数据并行
DeepSpeed 假设了单层参数量可以在单张显卡上放得下,如果不满足这个假设,那么仍然需要使用模型并行,而且 DeepSpeed 的模型并行是通过调用 Megatron 来实现的。
根据 NVIDIA 最新的那篇 论文 (也是下面本文重点要介绍的),Megatron 在大规模训练的效率是超过 DeepSpeed 不少的。
而 DeepSpeed 的论文一直强调:我可以用更少机器训练更大的模型,但没有突出过在效率上的优势。
DeepSpeed 后来又出了一篇论文: ZeRO-Infinity ,当单层参数量在单张显卡上放不下的时候,它通过对这一层算子切片,一片一片来执行,使得单卡也能跑得起来一个巨大的层,可以理解成一种 “时间”轴上展开的模型并行。

















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









