






有一个分类明细表格
| A | B | |
| 1 | Name | Name 2 |
| 2 | Unique 1 | ex 1 |
| 3 | Unique 1 | ex 2 |
| 4 | Unique 1 | ex 3 |
| 5 | Unique 2 | ext 1 |
| 6 | Unique 2 | ext 2 |
| 7 | Unique 2 | ext 3 |
| 8 | Unique 2 | ext 4 |
| 9 | Unique 2 | ext 5 |
要求分类后用分号合并明细
| D | E | |
| 1 | Unique 1 | ex 1;ex 2;ex 3 |
| 2 | Unique 2 | ext 1;ext 2;ext 3;ext 4;ext 5 |
使用 SPL XLL
=spl("=E@b(?.groups(~1;concat(~2;$[;])))",A2:B9)
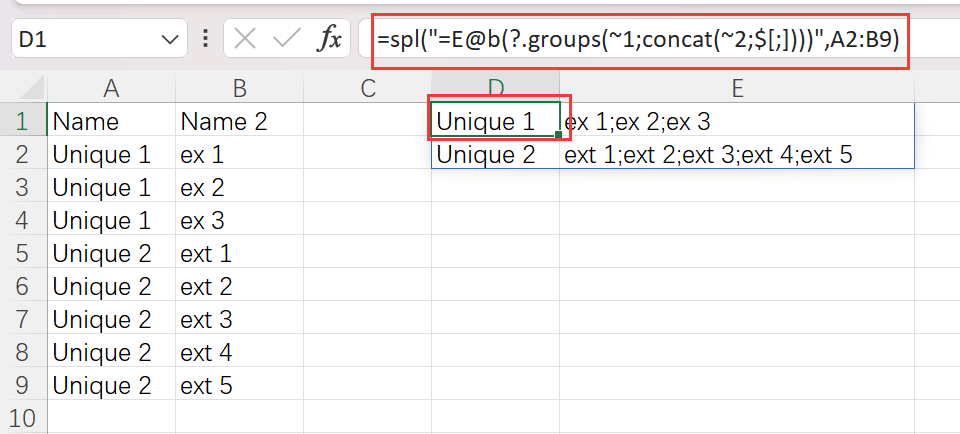
函数 E@b 将二维表转为序列,~1 表示当前成员的第 1 个子成员,$[] 是字符串标志















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









