







这篇记录python的爬虫学习历程,会不断更新。
urllib除了以双下划线开头结尾的内置属性外,还有4个重要的属性,分别是error,parse,request,response。Error,由urllib举出的exception类;Parse,解析绝对和相对的URLs;Request用各种协议打开URLs的一个扩展库;Response,被urllib使用的response类。
import urllib.request as ur
response = ur.urlopen('https://www.baidu.com/')
result = response.read().decode("utf-8")
结果如下
<html>
<head>
<script>
location.replace(location.href.replace("https://","http://"));
</script>
</head>
<body>
<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>
</body>
</html>
result_getcode = response.getcode() 返回状态码,结果为200,表示成功处理请求。关于状态码:https://www.cnblogs.com/cjwxf/p/6186287.html。
result_info = response.info()返回的元信息,有http表头信息等。
import urllib.error as ue
try:
response = ur.Request("http://www.google.com/")
html = ur.urlopen(response)
result = html.read().decode("utf-8")
except ue.URLError as e:
if hasattr(e,'reason'):
print('错误原因是' + str(e.reason))
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print('错误状态码是' + str(e.code))
else:
print('请求成功通过。')
用google测试的结果是:“错误原因是[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。” 可以的。
关于request库:
保存图片
import requests
web_url = "http://img.ivsky.com/img/tupian/pre/201708/30/kekeersitao-002.jpg"
response = requests.get(web_url)
b = response.content
with open("D://code_save/pic.jpg",'wb') as f:
f.write(b)
头信息如何找?
在浏览器中输入about:version可以看到

里面的用户代理部分就是我们需要的头信息。
import requests
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
设置代理:
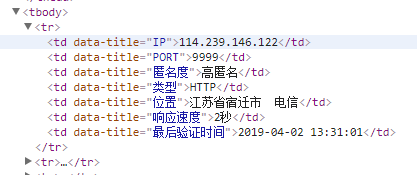
这是代理网站的html结构,我们需要爬取到ip后面的内容,所以,利用正则表达式抓取其中的内容
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="类型">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
我们用这种方法爬取了ip后面的内容,port后面的内容以及类型后面的内容,之后我们利用一个三层循环把他们组合起来变成一个完整的url
for i in range(len(iplist)):
for p in range(len(portlist)):
for t in range(len(typelist)):
if i is p is t:
a = typelist[t]+','+iplist[i] + ':' + portlist[p]
sumray.append(a)
print('高匿代理')
print(sumary)
即 http,ip:port的结构。最后我们用get_ipport(get_html(url))来启动,gethtml传入一个url当作参数返回爬取到的url的text内容。把这个内容传给getipport通过正则表达式寻找到需要的ip结构最后打印出来。
关于post请求:get请求会把需要的参数都表现在url中所以不够安全,post通过request body传递参数。
import requests
data = {'name':'Tom','age':'22'}
response = requests.post('http://httpbin.org/post', data=data)
print(response.text)
异常处理:
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException
while _:
try:
response = requests.get('http://www.google.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
显然是reqerror,依然无fuck说。















 2623
2623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









