







spark源码分析之随机森林(Random Forest)(一)
spark源码分析之随机森林(Random Forest)(二)
spark源码分析之随机森林(Random Forest)(四)
spark源码分析之随机森林(Random Forest)(五)
6. 随机森林训练
6.1. 数据结构
6.1.1. Node
树中的每个节点是一个Node结构
class Node @Since("1.2.0") (
@Since("1.0.0") val id: Int,
@Since("1.0.0") var predict: Predict,
@Since("1.2.0") var impurity: Double,
@Since("1.0.0") var isLeaf: Boolean,
@Since("1.0.0") var split: Option[Split],
@Since("1.0.0") var leftNode: Option[Node],
@Since("1.0.0") var rightNode: Option[Node],
@Since("1.0.0") var stats: Option[InformationGainStats])emptyNode,只初始化nodeIndex,其他都是默认值
def emptyNode(nodeIndex: Int): Node =
new Node(nodeIndex, new Predict(Double.MinValue),
-1.0, false, None, None, None, None)根据node的id,计算孩子节点的id
* Return the index of the left child of this node.
*/
def leftChildIndex(nodeIndex: Int): Int = nodeIndex << 1
/**
* Return the index of the right child of this node.
*/
def rightChildIndex(nodeIndex: Int): Int = (nodeIndex << 1) + 1左孩子节点就是当前id * 2,右孩子是id * 2+1。
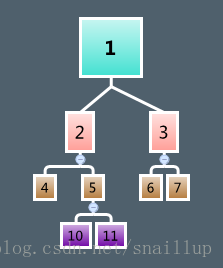
6.1.2. Entropy
6.1.2.1. Entropy
Entropy是个Object,里面最重要的是calculate函数
/**
* :: DeveloperApi ::
* information calculation for multiclass classification
* @param counts Array[Double] with counts for each label
* @param totalCount sum of counts for all labels
* @return information value, or 0 if totalCount = 0
*/
@Since("1.1.0")
@DeveloperApi
override def calculate(counts: Array[Double], totalCount: Double): Double = {
if (totalCount == 0) {
return 0
}
val numClasses = counts.length
var impurity = 0.0
var classIndex = 0
while (classIndex < numClasses) {
val classCount = counts(classIndex)
if (classCount != 0) {
val freq = classCount / totalCount
impurity -= freq * log2(freq)
}
classIndex += 1
}
impurity
}熵的计算公式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1900
1900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









