







目录
classification 与 regression 的区别
Training data 出现的问题
训练完一次模型后,根据训练集以及测试集的损失来确定改进方向。

如果训练集的损失大,一是考虑Model bias,是否是模型不够复杂,提供不了最够好的结果;又或者optimization不够好,没有从结果中找到最小的loss。
这时可以去调整模型的复杂度,对于优化器而言,不合适的优化方法在寻找最优解时,可能会陷入局部最优解,可以采用更好的优化器结合一线更合适的优化方法(Adam、RMS)

如果训练集的损失较小,但测试集损失较大,考虑模型可能过于复杂,出现过拟合的情况,这时候可以考虑增加训练集的数据量(data augmentation 数据增强)或者简化当前模型(Constrained model 约束模型 less or share parameters \less feature \early stopping \regularization \dropout),也可能训练集跟测试集的分布不一样不匹配导致。
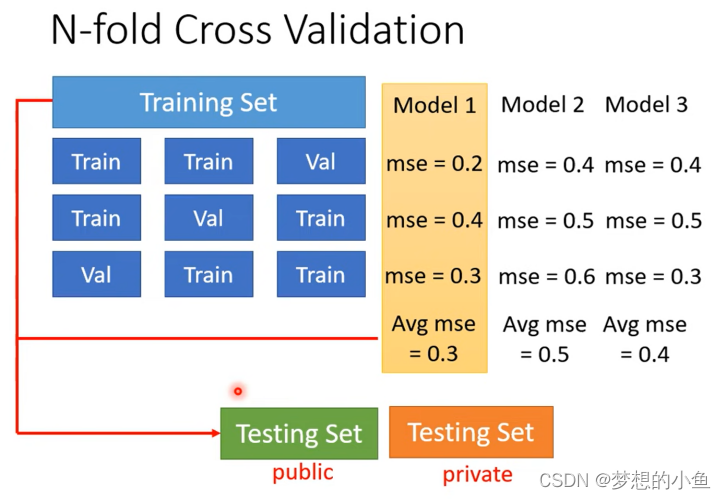
N折交叉验证:
1.先把训练集切成N等份,取其中一份当作Validation Set,另外N-1份当Training Set,然后要重复N次
2. 将组合后的N个model,相同环境下,在 Training data set 和 Validation data set 上面通通跑一次。然后把这每个 model 在这三类数据集的结果都平均起来,看看哪个 model 计算出的结果最好
如果你用这N个fold(层)得出来的结果是 model 1 最好,便把 model 1 用在它所划分的N-1组Training Set 上,然后训练出来的模型再用在 Testing Set 上面
Local minima:局部最优点
Saddle point:鞍点

如何判断临界点的类型
考察 θ 附近Loss的梯度(泰勒展开)

Hessian
Minimum ratio = Number of Positive Eigen valuesNumber of Eigen values
![]()
第一项中,L(θ),当θ'跟θ很近的时候,很靠近
第二项中,g 代表梯度(一阶导数),可以弥补 L(θ' ) 与 L(θ) 之间的差距; g 的第i个component , 就是θ的第i个 component 对L的微分
第三项中,H表示海塞矩阵,是L的二阶导数
结论

解决卡在 critical point 的办法
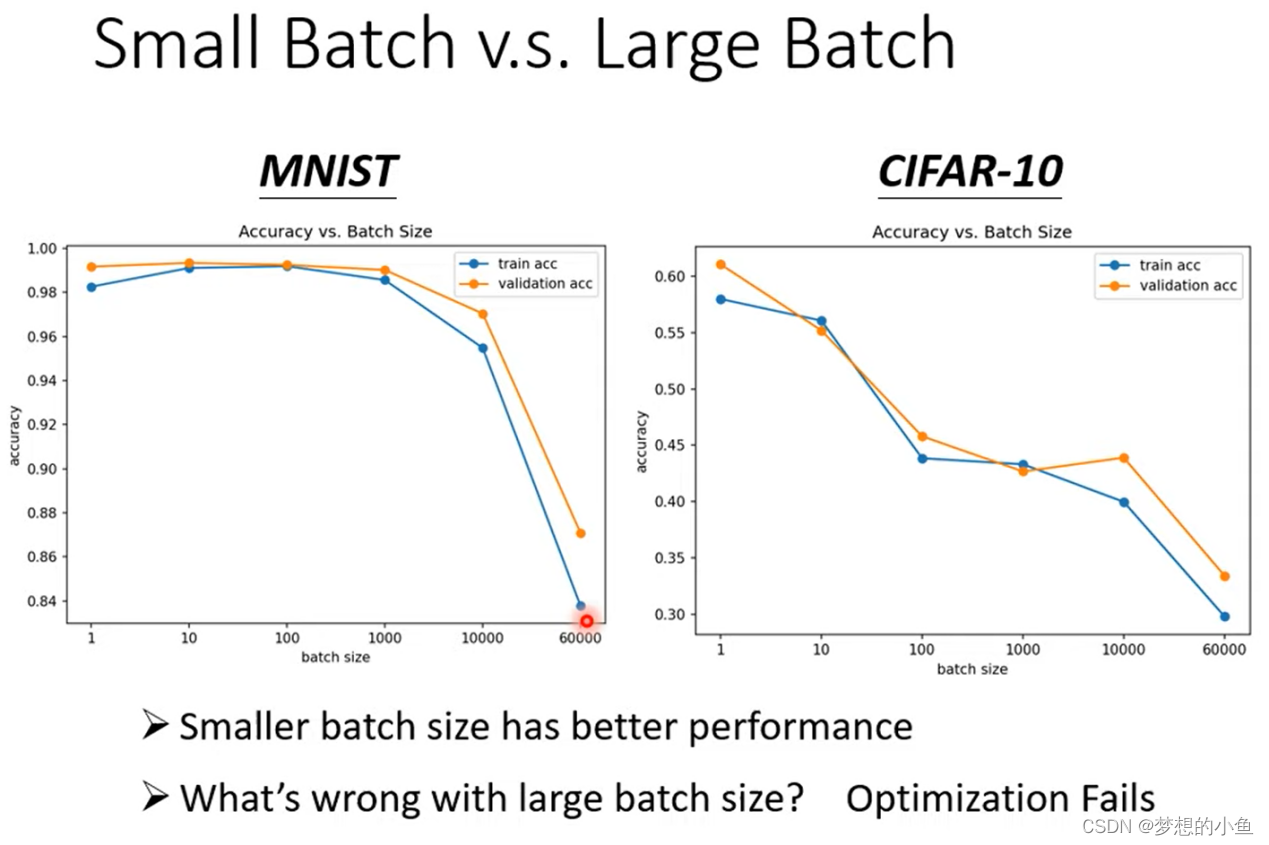
BatchSize

调整bantch的大小

Momentum
在更新现在的梯度下降方向的时候,考虑在此之前计算过的 所有的 梯度下降方向

自适应学习率调整
采用固定的学习率将会很难达到最优解。

Root Mean Square
将历史梯度绝对值的大小进行考虑,使得随着网络的训练,learning rate的值越来越小

RMS Prop
添加参数(表示当前梯度大小对于 learning rate 的影响比重,是一个超参数
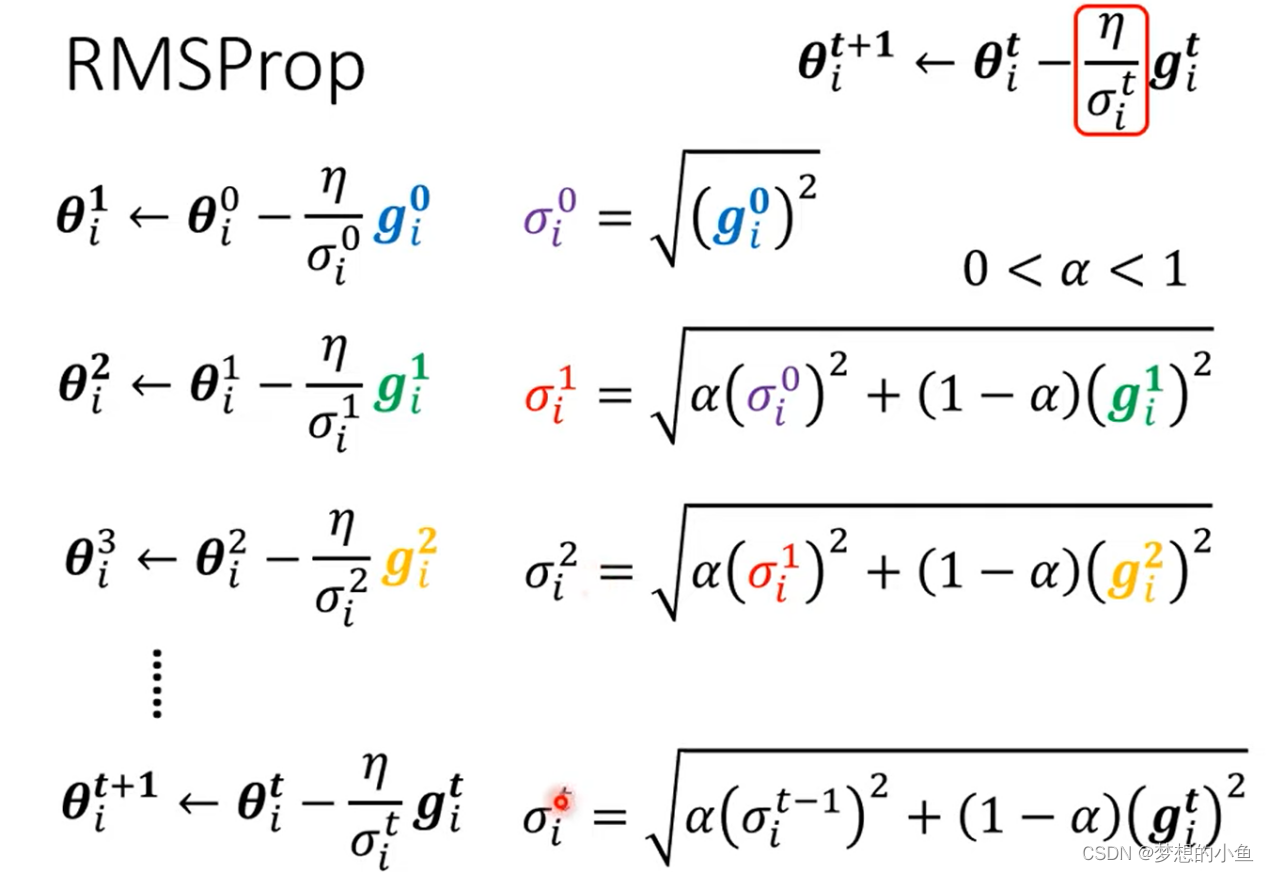
Adam = RMSProp + Momentum

Learning Rate Scheduling
使用 Warm Up的方式,随着时间先变大后变小

总结

学习率是变化的,一是将学习率变成一个随训练次数增加而减小的时间函数,二是将学习率的变化考虑之前一段时间的梯度的平方和开根,三是在梯度的计算时,加入一阶动量,即考虑上一次的梯度加入。
classification 与 regression 的区别
1. 在输出数量方面, R只输出一个预测y值,而C通过one-hot vector(独热编码)表示不同的类别(一个向量中只有1个1,其余都为0,1在不同的位置代表不同类别);
2. 在计算 Loss 时,R直接拿预测输出数值y,与真实数值计算接近度,而C将多个输出数值组成一个向量,向量经过 softmax(归一化,保证输出y′在0与1之间,并且总和为1,可以理解为 预测输出是y所代表类别的的概率值) 后形成新的向量,再拿新的向量去和不同类别计算接近度。
3. 计算loss的方法不同(新学习的)
① 介绍:regression采用MSE和MAE的方法计算loss函数;而classification采用cross entropy(交叉熵)的方法计算 loss 函数,当ŷ跟y'一模一样的时候,为最小交叉熵(等价于 maximizing likelihood 最大似然估计)
② 交叉熵适用于classification的原因:交叉熵改变了loss函数,也就改变了error surface,使得在大loss的地方也会有大的gradient,而不像MSE在大loss处的 gradient 很小,不易梯度下降。所以交叉熵计算出来的loss函数更容易做梯度下降,不容易卡在critical point。

















 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











