







1.前期准备
数据来源
阿里巴巴天池:baby goods info data
字段含义
总共有两个csv文件,用excel打开。
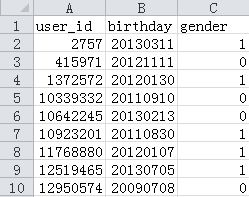
此为婴儿信息表。
三个字段:用户ID, birthday:出生日期 gender:性别(0 male,1 female, 2 未知)
总共953条记录

此为商品购买记录表。
七个字段:用户ID, 购买行为编号,商品序列号,商品类别号,商品属性,购买数量,购买日期。
共29971条记录
业务分析角度
由于缺少大量必要数据(客单价,订单金额等),只从以下三个角度分析:
- 销售角度
销量对比、销量变化趋势 - 产品角度
商品市场额度(大类、具体商品) - 用户角度
用户购买行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









