










论文地址:https://arxiv.org/pdf/1905.09998v3.pdf
项目地址:https://github.com/jialinwu17/Self_Critical_VQA
摘要
Visual Question Answering (VQA) deep-learning systems tend to capture superfi-cial statistical correlations in the training data because of strong language priors and fail to generalize to test data with a significantly different question-answer (QA) distribution [1]. To address this issue, we introduce a self-critical training objective that ensures that visual explanations of correct answers match the most influential image regions more than other competitive answer candidates. The
influential regions are either determined from human visual/textual explanations or automatically from just significant words in the question and answer. We evaluate our approach on the VQA generalization task using the VQA-CP dataset, achieving a new state-of-the-art i.e., 49.5% using textual explanations and 48.5% usingautomatically annotated regions.
目前的VQA任务依赖训练数据中的表面统计相关性,为解决这个问题,作者引入了一个自我批判的训练目标,确保正确答案的视觉解释比其他候选人给的答案更符合最有影响力的图像区域。影响区域要么由人类的视觉/文本解释决定,要么由问题和答案中的重要词自动决定。
1 贡献
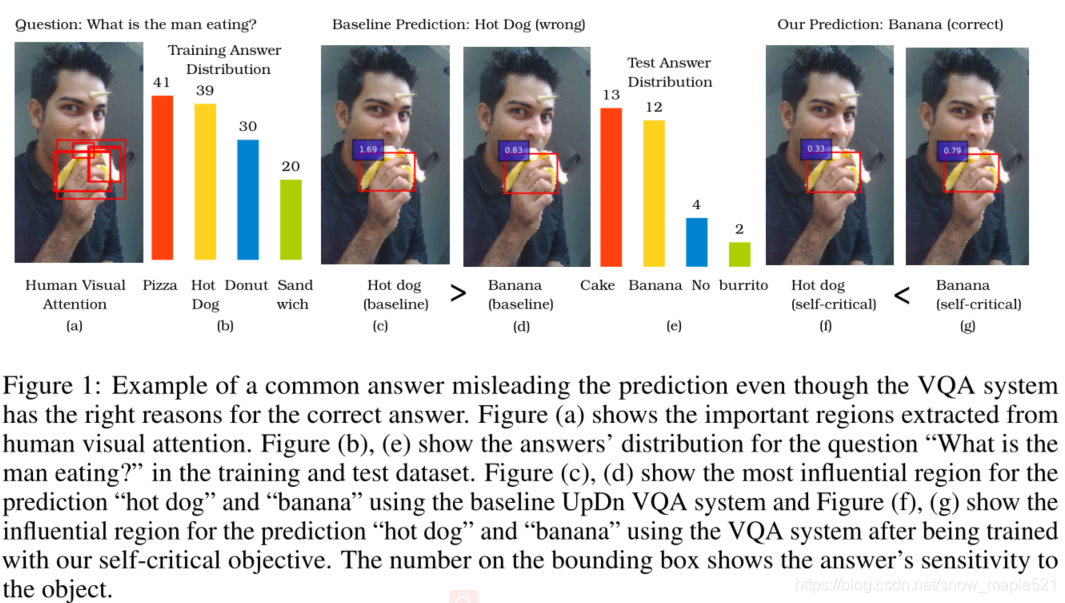
作者发现之前的VQA任务不考虑图像内容过度依赖语言先验就回答问题,虽然后来有VQA系统学会以正确的理由获得正确的答案,这些系统训练网络关注图像中被人类以某种方式标注的重要区域,但是存在缺点,作者发现很多时候即使答案预测错了,网络也会关注这些重要区域,如图1:
图1中,图(a)显示了从人类视觉注意中提取的重要区域。cd是基线UpDn VQA系统对“热狗”和“香蕉”预测最具影响力的区域,fg用自我批评目标训练后的VQA系统对“热狗”和“香蕉”预测最具影响力的区域。边框上的数字显示了答案对对象的敏感性。
为了解决这个问题,作者提出一个”自我批评“的方法,直接批评不正确答案对重要区域的敏感性。
- 首先确定影响网络预测正确答案最重要的区域
- 如果答案预测错误,就惩罚它对这个区域的关注度。
- 自我批评方法是端到端的可训练的。
研究了三种确定重要区域的方法:
- 人工标注为重要的区域
- 使用来自VQA- x[18]数据集的人类文本VQA解释来确定重要的对象,来结合图像确定重要区域
- 尝试只使用问题或答案中提到的对象来确定重要区域
2 核心
首先作者的方法需要构建一个提议的对象集,该对象集包含最具影响力的对象,人类在回答问题时会关注这些对象。
1 构建提议对象集
作者研究了三种方法
方法1:Construction from Visual Explanations.
作者采用VQA-HAT数据集作为图像解释源,HAT共包含59457个图像问题对,约占VQA-CP训练集和测试集的9%,而且作者还继承了HINT的对象评分系统,该系统基于提议对象框内相对于框外归一化的人类注意图,并根据自底向上的注意给每个检测到的对象打分,并通过选择顶部的【I】对象来构建潜在对象集。
方法2:Construction from Textual Explanations.
[18]引入了一个文本解释数据集,它注释了32,886个图像-问题对,相当于整个VQA-CP数据集的5%。为了提取潜在的对象集,首先使用空间词性标记器[11]为解释中的每个单词分配词性标记,然后提取句子中的名词。然后,选择其类别名的手套嵌入[19]与提取的任何一个名词的余弦相似度大于0.6的检测对象。最后,选择相似度最高的|I|对象。
方法3:Construction from Questions and Answers.
由于上述解释在其他数据集中可能无法得到,还考虑一种简单的方法,仅从训练QA对中提取建议对象集。这种方法与我们从文本解释中构造势集的方法非常相似。唯一的区别是,我们不是解析解释,而是解析QA对并从中提取名词
3 方法
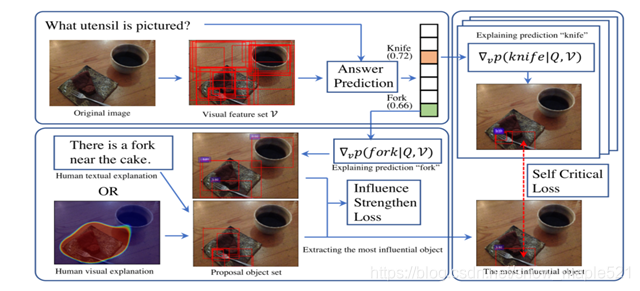
图2:模型概述。在左上角,基本UpDn VQA系统首先检测一组对象并预测一个答案。然后通过视觉解释分析正确答案对被检测对象的敏感性(Fork),提取建议对象集合中最具影响力的作为最具影响力的对象,并通过影响力增强损失(左下角块)进一步加强。最后,我们分析了竞争不正确答案对最具影响力对象的敏感性(Knife),并对该敏感性进行批判,直到VQA系统正确回答问题(right block)。边界框上的数字是答案对给定对象的敏感度
作者使用改进的GradCAM[24]来计算答案a对第i个对象特征vi的灵敏度,如Eq. 1所示
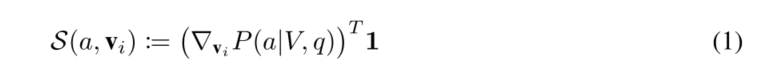
对GradCAM有两个修改:(1)移除ReLU单元,(2)不再由特征向量加权梯度。
识别并加强影响力区域
我们首先为答案a引入一个灵敏度违反项SV(a,vi,vj),第i和第j个对象将vi和vj作为vj超过vi的灵敏度量,如图所示
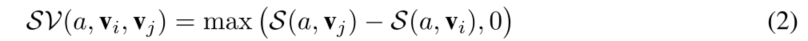
假设建议集至少包含一个有影响力的对象,人类将使用该对象来推断答案,因此施加了一个约束,即建议集中最敏感的对象不应低于建议集之外的任何对象,因此,我们引入了增强损失的影响Linfl
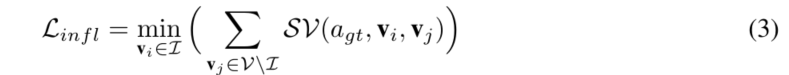
agt代表事实答案,作者的影响力强化损失和基于排名的HINT损失的主要区别是:(1)作者放松了对象应该遵循精确的人类排序这一不必要的约束,(2)在无法获得详细排序的情况下,更容易适应不同类型的解释(例如文本解释)。
批评不正确的答案
对于排名高于正确答案的错误答案,我们试图降低有影响对象的敏感性。例如,在VQA-CP中,卧室是最常见的房间类型。因此,在测试过程中,系统经常错误地将浴室(这在训练数据中很少见)分类为卧室。由于人类在识别浴室时将水槽视为一个有影响力的物体,所以我们想要减少水槽对总结卧室的影响。
为了解决这个问题,设计了一个自我批评的目标来批评VQA系统不正确但具有竞争性的决策,这些决策基于Eq. 4中定义的正确答案最敏感的最有影响力的对象v∗
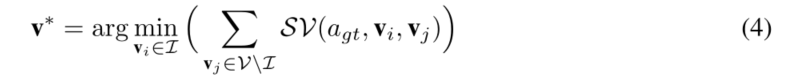
具体地说,提取了最多B个比正确答案更有信心的预测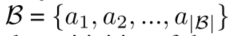 并利用提出的自我批评损失,直接减小B中答案对选定的最具影响力对象的加权敏感度,如下图所示:
并利用提出的自我批评损失,直接减小B中答案对选定的最具影响力对象的加权敏感度,如下图所示:
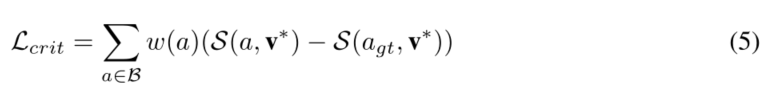
因为几个答案候选人可能是相似的(例如,奶牛和牛),权衡的敏感性差距(公式5)通过答案之间的余弦距离300-d手套嵌入
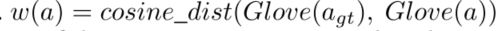
在多词回答的情况下,将这些答案的手套嵌入量计算为每个单词的手套嵌入量之和。
4 实验
利用关节损失对系统进行微调
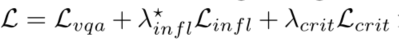
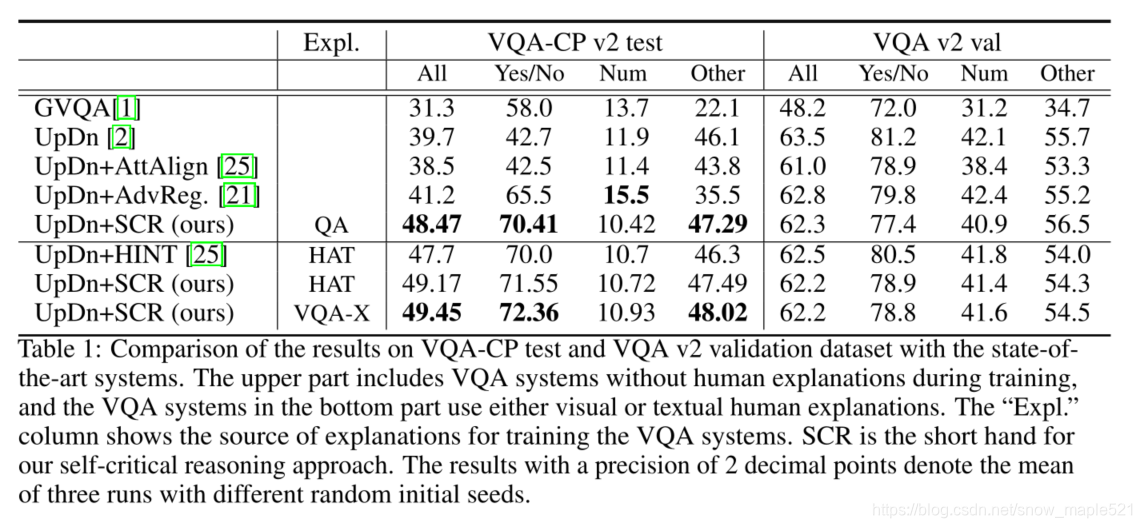
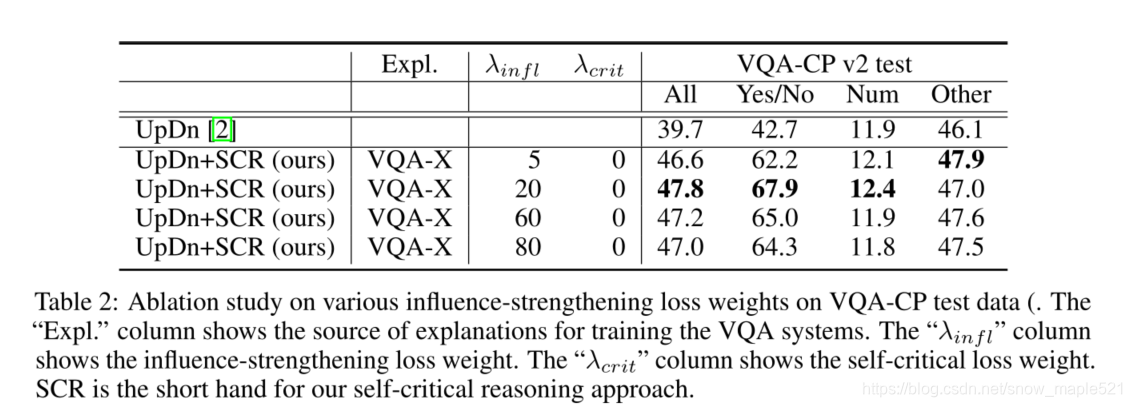
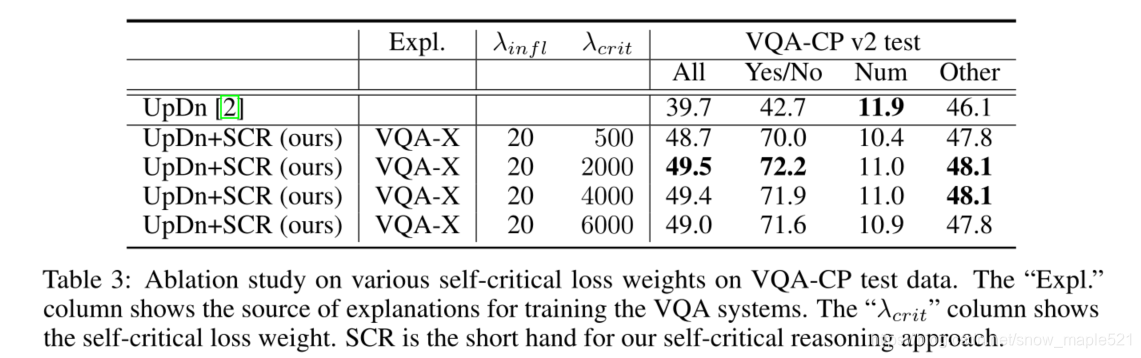

5 总结
在本研究中,探讨了如何通过批评不正确答案对正确答案最具影响力的对象的敏感性来提高VQA的性能。有影响对象是从人类视觉或文本解释中提取的建议集中选择的,或者只是从答案和问题中提到的对象中选择。
6 引用
[11] M. Honnibal and I. Montani. spacy 2: Natural language understanding with bloom embeddings, convolutional neural networks and incremental parsing. 2017.
[18] D. H. Park, L. A. Hendricks, Z. Akata, A. Rohrbach, B. Schiele, T. Darrell, and M. Rohrbach.
Multimodal Explanations: Justifying Decisions and Pointing to the Evidence. In CVPR, 2018.
[19] J. Pennington, R. Socher, and C. Manning. Glove: Global Vectors for Word Representation. In
EMNLP, 2014
[24] R. R. Selvaraju, M. Cogswell, A. Das, R. V edantam, D. Parikh, D. Batra, et al. Grad-CAM:
Visual Explanations from Deep Networks via Gradient-Based Localization. In ICCV, 2017.
[25] R. R. Selvaraju, S. Lee, Y . Shen, H. Jin, D. Batra, and D. Parikh. Taking a HINT: Leveraging
Explanations to Make Vision and Language Models More Grounded. In ICCV, 2019














 1546
1546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









