







使用Selenium爬取万方论文数据
文章目录
项目代码详见:https://github.com/xiaozhou-alt/WanfangPaperCrawler-Selenium
一、项目介绍
本项目基于万方数据库获取学术论文,通过 Selenium 能够自动化地搜索指定关键词的论文,并提取论文的关键元数据,包括标题、作者、发表年份、期刊信息、摘要、关键词等,并支持csv或tsv两种格式输出。保存之后进行数据清洗并评估数据质量。
二、Selenium库介绍
1.Selenium库的由来
在 2000 年代初,软件测试领域的主流工具是 Mercury Interactive 公司的产品(如 QuickTest Professional, QTP)。Mercury(汞)是一种有毒的化学元素,而 Selenium(硒)在自然界中恰好是 汞 的解毒剂(例如,硒化合物可以中和汞的毒性)。
Selenium 项目的创始人 Jason Huggins 以此为隐喻,将新工具命名为 Selenium,暗指它是“对抗” Mercury 公司垄断测试工具的一种 “解毒方案”。
2.Selenium库有什么用
Selenium库可谓是爬虫的好助手,它可以自动化浏览器操作的工具,主要用于 Web 应用的测试和爬取动态数据,模拟复杂用户行为(比如点击、下拉选择、文件上传、滚轮滚动等等)
那么话不多说让我们直接进入代码实现部分–>
三、代码实现
1.库引入以及项目环境
项目环境(requirements.txt):
selenium>=4.0
beautifulsoup4>=4.9
pandas>=1.3
tqdm>=4.60
lxml>=4.6
导入的库
import os # 文件路径操作,创建输出目录
import re # 正则表达式,用于文本匹配和清洗
import random # 生成随机数,用于反爬虫延迟
import time # 时间相关操作,生成时间戳
import pandas as pd # 数据处理,将结果保存为CSV/TSV
from bs4 import BeautifulSoup # HTML解析,提取页面元素
from selenium import webdriver # 浏览器自动化,模拟用户操作
from selenium.webdriver.chrome.options import Options # 浏览器配置
from selenium.webdriver.common.by import By # 元素定位策略
from selenium.webdriver.support.ui import WebDriverWait # 显式等待
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.common.exceptions import TimeoutException, NoSuchElementException # 异常处理
from tqdm import tqdm # 进度条显示
import urllib # URL编码处理
import json # JSON格式数据处理
from random import uniform # 生成随机浮点数
from time import sleep # 延迟控制
2.文件目录
- WanfangPaperCrawler-Selenium
- output # 储存爬到的数据
- wanfang.py # 爬虫
- clean.ipynb # 数据清洗
3.爬虫实现
1)浏览器初始化
初始化爬虫核心参数,包括目标网站URL、浏览器驱动实例和输出目录;配置Chrome浏览器选项,禁用自动化特征,伪装真实浏览器指纹,绕过网站自动化工具检测。
class WanfangPaperCrawler:
def __init__(self):
self.base_url = 'https://s.wanfangdata.com.cn'
self.driver = self.init_browser() # 初始化浏览器
self.output_dir = 'output'
os.makedirs(self.output_dir, exist_ok=True) # 自动创建输出目录
def init_browser(self):
chrome_options = Options()
# 浏览器配置项:
# --disable-gpu:禁用GPU加速(兼容性优化)
# --no-sandbox:禁用沙盒模式(服务器环境常用)
# user-agent:伪装浏览器身份
# 禁用自动化控制特征(绕过反爬虫检测)
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("user-agent=...")
driver = webdriver.Chrome(options=chrome_options)
driver.set_page_load_timeout(30) # 页面加载超时设置
# 注入JavaScript代码隐藏Selenium特征
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {...})
2)论文搜寻与分页
根据用户手动输入的关键词和最大爬取数目跳转到指定网页,此处实现跳转的方法是直接在网址地址中加入q=你的关键词,代码中设置爬取近三年的论文(即2022-2025年),图片实例中关键词为量子计算
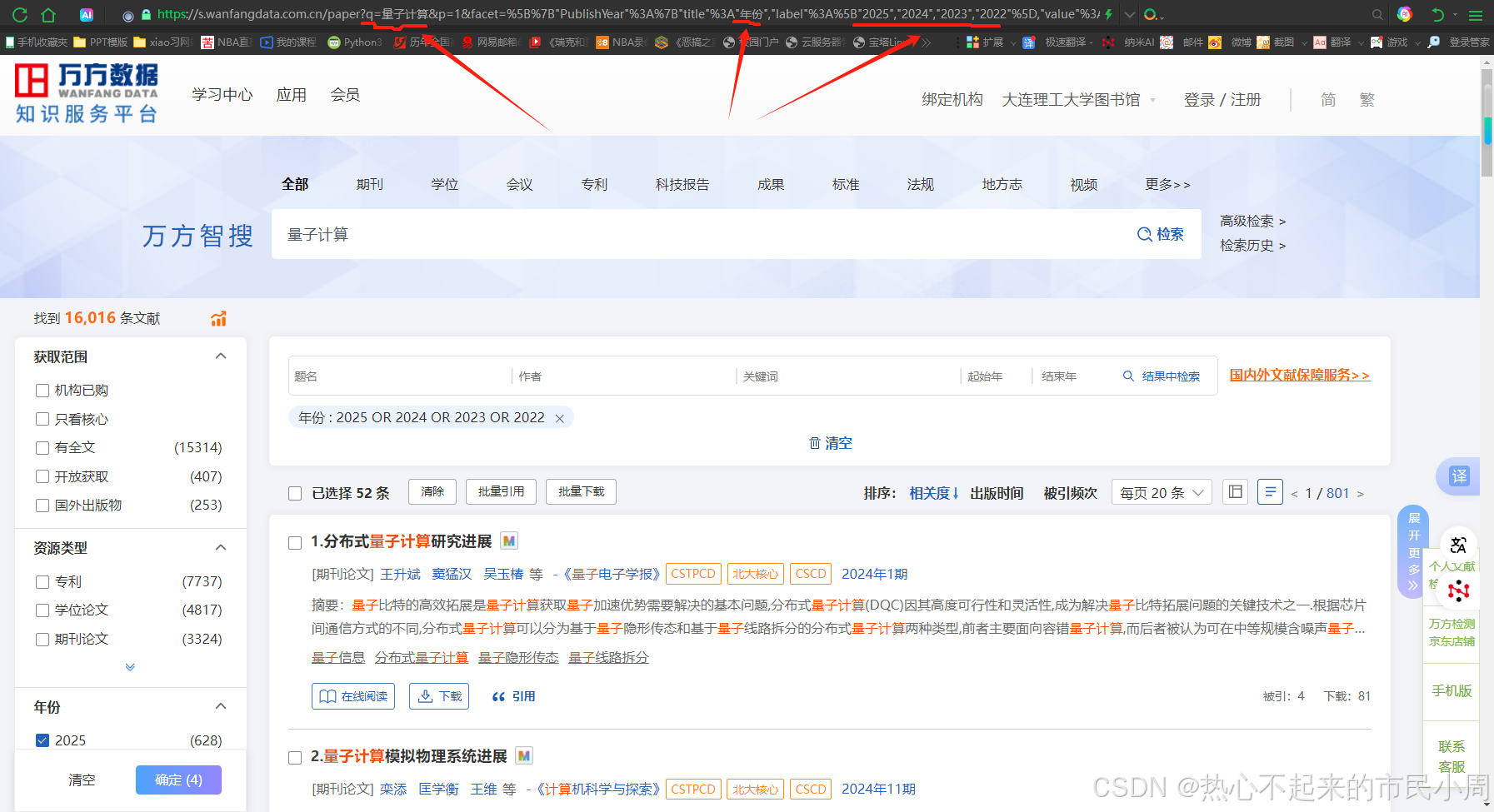
同时根据查找到的页面依次点击每一个论文分页,执行后续的get_paper_detail 函数操作然后返回到上一页,直到页面中20篇论文信息爬取完毕
def search_papers(self, keyword, max_papers=10, file_format='csv'):
# 构建带筛选条件的URL(年份+期刊类型)
base_params = { "q": keyword, "facet": [...] }
encoded_facet = urllib.parse.quote(json.dumps(...))
search_url = f"{self.base_url}/paper?q={keyword}&facet={encoded_facet}"
# 分页处理逻辑
while collected < max_papers:
papers = self.driver.find_elements(By.CSS_SELECTOR, '.title-area')
for paper in papers:
title_element.click() # 点击进入详情页
self.driver.switch_to.window(self.driver.window_handles[1])
paper_info = self.get_paper_details() # 提取详情数据
self.driver.close() # 关闭详情页
collected += 1
3)论文元素获取
从详情页HTML中解析结构化数据,包括标题、年份、作者单位等,使用多套匹配规则应对网页模板变化。
def get_paper_details(self):
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(self.driver.page_source, 'html.parser')
# 标题提取
title_element = soup.select_one('.detailTitleCN span')
title = title_element.text.strip() if title_element else ''
# 年份提取(适配多模板)
year = "未知"
if thesis_year_div := soup.find('div', class_='thesisYear'):
year = re.search(r'\d{4}', thesis_year_div.text).group()
elif publish_div := soup.find('div', class_='publish'):
year = re.search(r'\d{4}', publish_div.text).group()
# 作者单位清洗
organizations = [re.sub(r',\S+$', '', org.text) for org in soup.select('.detailOrganization a')]
当最大获取论文量超过20时,涉及到翻页的问题,代码中一开始使用直接在网址地址中修改&p=1虽然人为直接点击可以实现跳转,但是并不能获取到元素,无可奈何,只能更改逻辑为:
获取到页面中的>(下一页)标志,模拟用户点击进行翻页,同时添加滚轮滚动的逻辑,确保页面中存在下一页按钮
next_btn = WebDriverWait(self.driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR,'span.next')))
self.driver.execute_script("arguments[0].scrollIntoView({block: 'center'});", next_btn)
self.random_delay(1, 1.5) # 短延迟让滚动完成
next_btn.click()
WebDriverWait(self.driver, 15).until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, 'span.pager.active'),str(current_page + 1)))
current_page += 1
print(f"✅ 成功跳转到第 {current_page} 页")
4)数据储存
将爬取结果转换为 DataFrame,按用户选择的格式(csv/ tsv )保存,自动生成含时间戳的文件名避免覆盖。
def save_data(self, data, keyword, file_format):
df = pd.DataFrame(data)
filename = f"wanfang_papers_{keyword}_{time.strftime('%Y%m%d_%H%M%S')}"
if file_format == 'tsv':
df.to_csv(f"{filename}.tsv", sep='\t', index=False)
else:
df.to_csv(f"{filename}.csv", encoding='utf_8_sig') # 兼容Excel
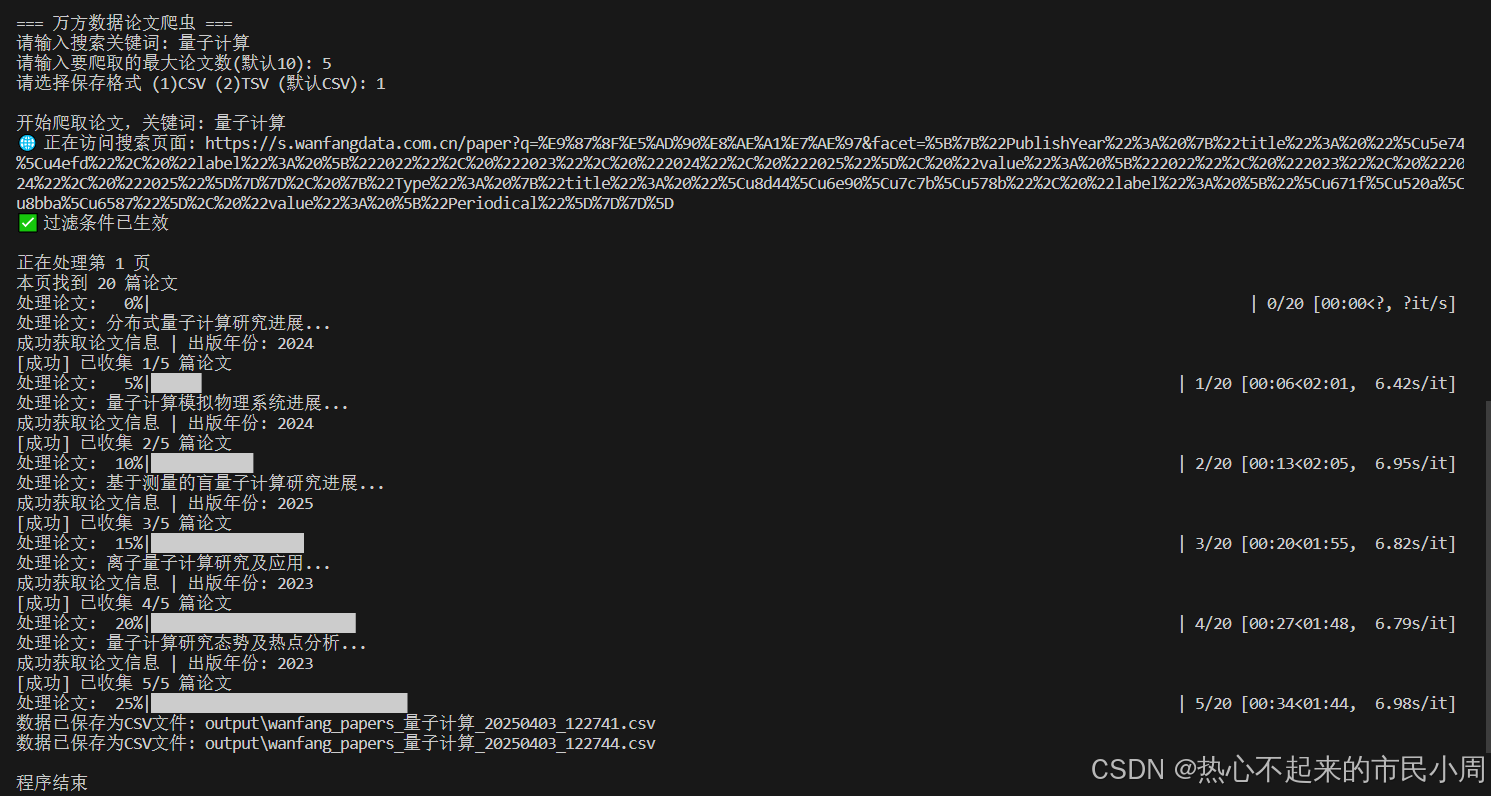
代码运行终端显示如下:
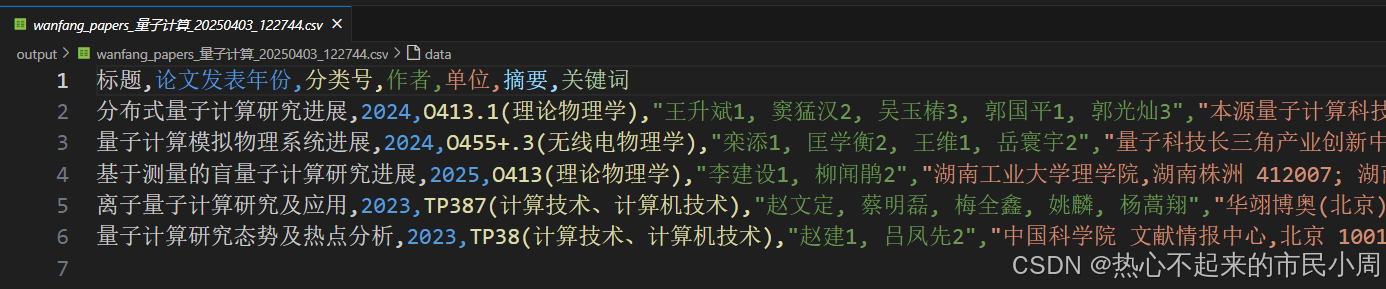
保存的csv 格式如下:
其中应对反爬机制的策略包括:
动态等待:所有页面操作后均添加随机延迟(random_delay)
浏览器指纹伪装:通过 CDP 命令修改 navigator.webdriver 属性
请求头模拟:设置真实 User-Agent 和窗口尺寸
多模板适配:在 get_paper_details 中使用多种选择器应对页面结构变化
分页容错:显式等待分页元素更新后再继续操作
四、清洗爬取到的数据
1.格式转换为xlsx
首先将爬取到的数据整理汇总到xlsx表格中,并排除不需要的字段做初步清洗,去除空字段。
def process_txt(input_dir, output_file):
# 定义列顺序(排除不需要的字段后)
columns_order = [
...
]
all_entries = []
# 遍历输入目录下的所有txt文件
for filename in os.listdir(input_dir):
if filename.endswith('.txt'):
filepath = os.path.join(input_dir, filename)
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read().strip()
...
# 使用正则表达式匹配字段
match = re.match(r'^\{(.+?)\}: (.+)$', line)
if match:
field = match.group(1)
value = match.group(2).strip()
# 排除不需要的字段
if field not in excluded_fields:
entry_dict[field] = value
...
# 创建DataFrame并保存为Excel
df = pd.DataFrame(all_entries, columns=columns_order)
# 数据清洗:处理可能的空字符串
df.replace({'': pd.NA}, inplace=True)
# 保存结果
df.to_excel(output_file, index=False)
print(f'成功处理 {len(all_entries)} 篇文献,已保存到 {output_file}')
2.统计缺失值
使用函数统计每一个领域论文关键指标的缺失数目,以及每一个指标的缺失数量,去除对应的条目,得到关键指标完整的数据集。
def analyze_missing_values(file_path):
"""统计Excel文件各列的缺失值情况"""
# 读取Excel文件
df = pd.read_excel(file_path)
# 统计缺失值
missing_count = df.isnull().sum()
missing_rate = missing_count / len(df) * 100
# 创建统计结果表
stats_df = pd.DataFrame({
'总记录数': len(df),
'缺失值数量': missing_count,
'缺失率(%)': missing_rate.round(2),
'数据类型': df.dtypes.values
})
print("各列缺失值统计:")
print(stats_df.sort_values('缺失率(%)', ascending=False))
return stats_df
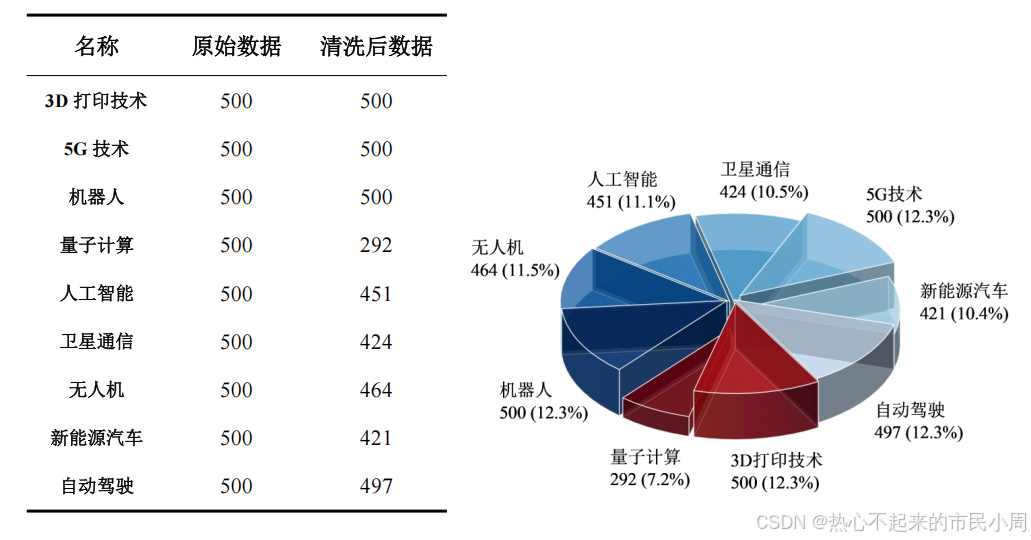
爬取的数据处理后,报告结果如下所示:

3.数据质量评估
我们从完整性、准确性、一致性三个角度评估数据质量,公示如下:

def process_sheets(input_file, output_folder):
...
quality_metrics = {
'完整性': round(1 - df.isnull().mean().mean(), 2),
'准确性': validate_data(cleaned_df),
'一致性': check_consistency(cleaned_df)
}
...
def validate_data(df):
"""准确性验证"""
# 示例验证规则:数值列非负
numeric_cols = df.select_dtypes(include='number').columns
error_rate = df[numeric_cols].apply(lambda x: (x < 0).sum()).sum() / df.size
return round(1 - error_rate, 2)
def check_consistency(df):
"""一致性检查"""
# 检查日期格式一致性
date_cols = [col for col in df.columns if 'date' in col.lower()]
if date_cols:
return df[date_cols].apply(lambda x: x.str.contains(r'\d{4}-\d{2}-\d{2}').mean()).mean()
return 1.0

如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









