









基于Neo4j创建中国先进技术知识图谱
PS:本次实验使用的数据库为Neo4j图形数据库,关于Neo4j的下载配置包jdk的配置课件这篇文章: Neo4j安装与配置以及JDK安装与配置教程(超详细)
一、项目介绍
本次项目基于Neo4j对中国先进技术领域构建知识图谱,并完成对于知识图谱的基础增删改查操作
二、数据集介绍
本次项目使用的数据集为爬取到的万方网的论文数据,爬取代码和操作说明详见:使用Selenium爬取万方论文数据并进行数据清洗
本文使用的数据集即为清洗处理后的论文信息,具体格式如下:

项目“中国先进技术”的领域及其数量如下所示:

三、项目实现
1.数据预处理
首先对已有的xlsx数据进行预处理,将九个领域每一个 sheet 分别保存为一个单独的 csv 文件,便于后续处理创建图数据库:
import pandas as pd
import os
from datetime import datetime
def excel_to_csv_all_sheets(excel_path, output_folder='csv_output'):
"""
将Excel文件所有工作表批量转换为CSV
参数:
excel_path: Excel文件路径
output_folder: 输出目录名称(默认在当前目录创建csv_output文件夹)
"""
try:
# 创建输出目录(如果不存在)
os.makedirs(output_folder, exist_ok=True)
# 读取Excel所有工作表
all_sheets = pd.read_excel(excel_path, sheet_name=None)
# 遍历每个工作表
for sheet_name, df in all_sheets.items():
# 生成CSV文件名(保留原Excel文件名+工作表名)
excel_name = os.path.splitext(os.path.basename(excel_path))[0]
csv_filename = f"{excel_name}_{sheet_name}.csv"
csv_path = os.path.join(output_folder, csv_filename)
# 保存为CSV(8编码避免中文乱码)
df.to_csv(csv_path, index=False, encoding='utf-8-sig')
print(f"成功转换:{sheet_name} -> {csv_filename}")
print(f"\n转换完成!所有CSV文件已保存至:{os.path.abspath(output_folder)}")
except Exception as e:
print(f"转换失败:{str(e)}")
# 使用示例(修改为你的Excel文件路径)
excel_to_csv_all_sheets('data.xlsx', # 替换为你的Excel文件路径
output_folder='output' # 默认输出目录(可自定义)
)
统一分隔符为英文分号,并清除多余的分号防止处理错误,同时增加地址数和作者数统计栏,并确保地址数量大于作者数量,防止作者在创建隶属关系是找不到对象(这也是笔者在进行图数据库创建的过程中,出现报错后发现的问题。找了我半天,岂可修! 请读者根据自身数据的情况注意调整):
import pandas as pd
def preprocess_address(csv_path):
df = pd.read_csv(csv_path)
# 统一分隔符为英文分号
df['Author Address'] = df['Author Address'].str.replace(';', ';')
# 清理尾部多余分号
df['Author Address'] = df['Author Address'].str.rstrip(';')
# 确保地址数量≥作者数量
df['Author_count'] = df['Author'].str.count(';') + 1
df['Address_count'] = df['Author Address'].str.count(';') + 1
# 填充缺失地址
def fill_address(row):
addrs = row['Author Address'].split(';')
if len(addrs) < row['Author_count']:
addrs += ['未知机构'] * (row['Author_count'] - len(addrs))
return ';'.join(addrs)
df['Author Address'] = df.apply(fill_address, axis=1)
# 保存处理后的CSV
df.to_csv('output/data_3D打印技术.csv', index=False)
# 使用示例
str = 'output/data_'
input = ['5G技术','机器人','量子计算','人工智能','卫星通信','无人机','新能源汽车','自动驾驶']
for i in input:
preprocess_address(str+i+".csv")
print(i+"√")
2.Neo4j数据库三要素
鉴于读者可能从未使用过Neo4j图数据库,我在这里就本项目而言,简单说明一下图数据库的三要素:实体、属性与关系
下面先想象一个场景:小明今年28岁,身高180,住在翻斗花园。然后让我们在看三要素的概念:
实体:数据库中的一个具体对象或事物,例如一个人、一本书或一家公司;示例中就是小明这个人(节点 Node = Person)和翻斗花园(节点 Node = Address)这个小区。
属性:实体所具有的特征或属性,例如一个人的姓名、年龄或性别。每个实体都有其自己的属性,这些属性描述了实体的特征或特性;示例中就是小明(name = ‘小明’)今年28岁(age = 28),身高(height = 180),翻斗花园(name = ‘翻斗花园’)
关系:实体之间的联系或连接,例如一个人与一本书之间的借阅关系或一家公司与其员工之间的雇佣关系;示例中就是小明住在(relationship = “LIVED_IN”)翻斗花园
3.图数据库信息介绍
讲明白了三要素,下面首先介绍一下我们构建完成的数据库的基本信息
数据库包含 7 类,共 24014 个 节点:
- AdvancedTechnologyInChina:根节点,代表中国先进技术,也就是项目的主题

- TechnologyDomain:领域节点,代表我们数据中有关中国先进技术的九个领域

- Article:论文节点,代表每一篇搜集到的论文,其中含有论文的一些非节点的属性信息,比如摘要、issn、网址

- Author:作者节点,代表每一个涉及到的作者,每一篇论文会包含多个作者,属性仅包含作者姓名

- Institution:机构节点,代表作者所属的单位和机构,属性仅包含机构名称

- Journal:期刊节点,代表论文所属的期刊名称,属性包含期刊名称以及期刊的ISSN号

- Keyword:关键词节点,代表论文涉及到的关键词,不同论文可能会有相同的关键词

包含6 类,共 37591 条 关系:
- SUB_DOMAIN_OF:领域属于 关系,由TechnologyDomain指向AdvancedTechnologyInChina

- BELONGS_TO:论文属于 关系,由Article指向TechnologyDomain

- WRITTEN_BY:创作 关系,由Author指向Article

- AFFILIATED_WITH:隶属于 关系,由Author指向Institution

- HAS_KEYWORD:包含关键词 关系,由Article指向Keyword

- PUBLISHED_IN:发表于 关系,由Article指向Journal

展示图如下所示:

4.开始创建数据库
Neo4j数据库使用Cypher语言进行增删改查,所以此处我们也使用Cypher语言进行数据库的创建:
首先我们需要将自己的 csv 文件放入自己的 Neo4j 文件夹中的 import 文件夹,数据库读取文件是从 import 文件夹中读取:

首先创建一个名为 “中国先进技术” 的 根节点:
CREATE (:AdvancedTechnologyInChina {
name: "中国先进技术",
})
我们对 csv 文件进行依次处理,先创建 领域节点,并关联根节点和领域节点:
MERGE (domain:TechnologyDomain {name: "3D打印技术"})
WITH domain
MATCH (root:AdvancedTechnologyInChina {name: "中国先进技术"})
MERGE (domain)-[:SUB_DOMAIN_OF]->(root);
我们依次创建 文章节点 并为文章节点创建摘要、ISSN、网址、编号等属性信息;将创建完成的文章节点关联到 3D打印技术 这个领域:
LOAD CSV WITH HEADERS FROM 'file:///output/data_3D打印.csv' AS row
// 创建文章节点
MERGE (a:Article {title: row.Title})
SET a.abstract = row.Abstract,
a.isbn_issn = row.`ISBN/ISSN`,
a.url = row.URL,
a.notes = row.Notes
// 关联到3D打印技术子领域
WITH a, row
MATCH (domain:TechnologyDomain {name: "3D打印技术"})
MERGE (a)-[:BELONGS_TO]->(domain)
创建 作者节点 和 机构节点,并将两个节点进行关联,代码中包含错误处理,对于没有机构的作者,使用未知机构进行填充,防止在导入信息时出现报错:
// 机构和作者
LOAD CSV WITH HEADERS FROM 'file:///output/data_3D打印.csv' AS row
WITH row,
[a IN SPLIT(row.Author, ';') | TRIM(a)] AS authors,
[addr IN SPLIT(row.`Author Address`, ';') |
CASE WHEN TRIM(addr) = '' THEN '未知机构' ELSE TRIM(addr) END] AS addresses
WHERE SIZE(addresses) >= SIZE(authors) // 双重验证
UNWIND RANGE(0, SIZE(authors)-1) AS i
MERGE (auth:Author {name: authors[i]})
MERGE (inst:Institution {address: addresses[i]})
MERGE (auth)-[:AFFILIATED_WITH]->(inst)
MERGE (a:Article {title: row.Title})
MERGE (auth)-[:WRITTEN_BY]->(a)
创建 期刊节点:
// 期刊种类
CREATE CONSTRAINT IF NOT EXISTS FOR (j:Journal) REQUIRE j.name IS UNIQUE;
// 带数据清洗的导入
LOAD CSV WITH HEADERS FROM 'file:///output/data_3D打印.csv' AS row
WITH TRIM(row.Journal) AS journalName
WHERE journalName IS NOT NULL AND journalName <> ''
MERGE (j:Journal {name: journalName})
SET j.importTime = datetime()
RETURN count(j) AS createdNodes
创建 关键词节点 ,按照 “ ; ” 的间隔来读入所有关键词,将没有关键词的论文设定为 Unknow_Keyword:
// 关键词
// 第一部分:创建约束(需单独执行)
CREATE CONSTRAINT keyword_unique IF NOT EXISTS
FOR (k:Keyword) REQUIRE k.keyword IS UNIQUE;
// 第二部分:数据导入(单独执行)
LOAD CSV WITH HEADERS FROM 'file:///output/data_3D打印.csv' AS row
WITH row,
[k IN SPLIT(row.Keywords, ';') | TRIM(k)] AS keywords
UNWIND keywords AS keyword
WITH row, keyword,
CASE
WHEN keyword = '' THEN 'Unknown_Keyword'
ELSE keyword
END AS cleanKeyword
MERGE (k:Keyword {keyword: cleanKeyword})
MERGE (a:Article {title: row.Title})
MERGE (a)-[:HAS_KEYWORD]->(k);
5.结果展示
创建完成的图数据库如下所示:
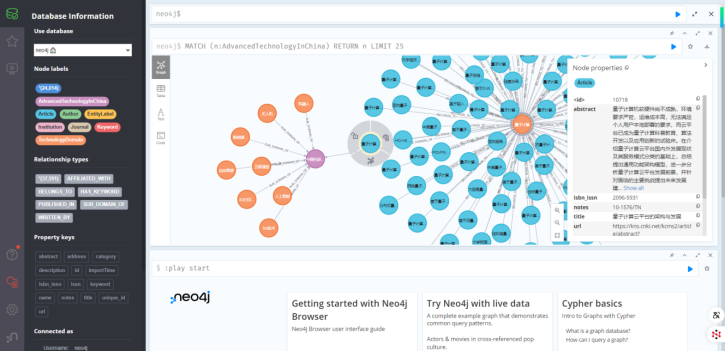
为了便于图谱可视化,我使用 github 上的开源项目 GraphXR 对图谱进行3D可视化:
环状结构:

球状结构:

如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!

















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









