










📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
最近,在知识星球《AI技术实践案例》中看到一位小伙伴分享了《AutoGen + DeepSeek实战》的文章,深受启发。于是,我结合自己的测试工作场景,尝试将 Streamlit、AutoGen 和 DeepSeek 结合起来,实现从 PRD 文件智能生成测试用例的全流程自动化。本文将分享我的实践过程,包括如何通过 Streamlit 快速构建交互式应用、利用 AutoGen 实现多智能体协作,以及调用 DeepSeek 模型生成高质量测试用例。希望我的经验能为大家提供一些参考和灵感!
工具组合的核心价值
-
Streamlit:
-
快速构建交互式 Web 应用,支持上传 PDF 文件、输入 PRD 内容、选择导出格式等功能。
-
实时展示生成的测试用例,提供友好的用户界面。
-
-
AutoGen:
-
通过多智能体协作,模拟测试团队的分工与协作(如需求分析、测试设计、用例评审)。
-
支持自定义角色,提升复杂需求的解析能力。
-
-
DeepSeek:
-
深度理解 PRD 内容,提取关键需求点并生成高覆盖率的测试用例。
-
支持多种格式导出,满足不同团队的需求。
-
实战场景与操作步骤
场景 1:上传 PDF 格式的 PRD 文件生成测试用例
需求:用户上传 PDF 格式的 PRD 文件,系统自动解析内容并生成测试用例。
步骤:
-
Streamlit 界面设计:
import streamlit as st # 设置页面配置 st.set_page_config( page_title="上传需求文档&测试用例生成器", page_icon="✅", layout="wide" ) ... # 创建选项卡 source_tab1, source_tab2 = st.tabs(["📄 文档上传", "✏️ 手动输入"]) with source_tab1: uploaded_file = st.file_uploader("上传需求文档", type=["pdf"]) if uploaded_file isnotNone: # 保存上传的文件到data目录 file_path = os.path.join("data", uploaded_file.name) with open(file_path, "wb") as f: f.write(uploaded_file.getvalue()) st.session_state.uploaded_file_path = file_path st.success(f"文件已上传并保存到: {file_path}") # 调用 AutoGen 和 DeepSeek 解析 PRD 并生成测试用例-
创建文件上传组件,支持上传 PDF 文件。
-
添加按钮,触发测试用例生成流程。
-
-
AutoGen 多智能体协作:
from autogen import AssistantAgent # 从PDF提取文本 def extract_text_from_pdf(pdf_file) -> Dict[str, Any]: """从PDF文件中提取文本内容""" start_time = time.time() try: # 直接从内存加载PDF pdf_bytes = pdf_file.getvalue() doc = fitz.open(stream=pdf_bytes, filetype="pdf") # 提取文本 # 创建测试用例生成器 @st.cache_resource def get_testcase_writer(): return AssistantAgent( name="testcase_writer", model_client=model_client, system_message=TESTCASE_WRITER_SYSTEM_MESSAGE, model_client_stream=True, )-
解析 PRD 内容。
-
生成测试用例。
-
-
DeepSeek 生成测试用例:
示例输出:
-
输出测试用例,支持多种格式导出(Excel、JSON、Markdown)。
-
-
导出功能实现:
# 导出为Markdown def export_to_markdown(testcases: TestCaseCollection) -> str: """将测试用例导出为Markdown格式""" # 导出为Excel def export_to_excel(testcases: TestCaseCollection) -> bytes: """将测试用例导出为Excel文件""" # 导出为JSON def export_json(testcases: TestCaseCollection) -> str: """将测试用例导出为JSON字符串"""-
添加导出选项,支持 Excel、JSON、Markdown 格式。
-
场景 2:手动输入 PRD 内容生成测试用例
需求:用户手动输入 PRD 内容,系统生成测试用例。
步骤:
-
Streamlit 界面设计:
with source_tab2: manual_input = st.text_area( "需求描述", height=300, placeholder="请详细描述你的功能需求,例如:\n开发一个用户注册功能,要求用户提供用户名、密码和电子邮件。用户名长度为3-20个字符,密码长度至少为6个字符且必须包含数字和字母,电子邮件必须是有效格式。", key="manual_requirements_input" ) if manual_input: st.session_state.extracted_text = manual_input # 调用 AutoGen 和 DeepSeek 生成测试用例-
创建文本输入框,支持用户手动输入 PRD 内容。
-
-
AutoGen 多智能体协作:
-
使用与场景 1 相同的流程,生成测试用例。
-
-
导出功能实现:
-
支持与场景 1 相同的导出功能。
-
常见问题
-
安装环境问题:
-
确保 Python 版本 >= 3.11。
-
安装依赖库:
-
pip install -r requirements.txt
# 若遇到如图所示的问题,则安装
pip install openai

-
调用模型失败:
-
检查网络连接,确保能访问 DeepSeek API。
-
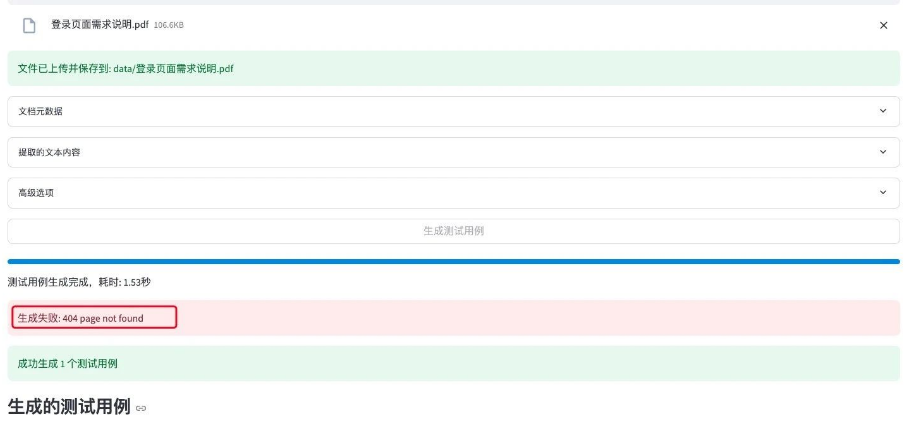
-
-
确认 API 密钥配置正确。
-
from autogen_ext.models.openai import OpenAIChatCompletionClient
model_client = OpenAIChatCompletionClient(
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
base_url="https://api.siliconflow.cn/v1",
api_key=your_api_key,
model_info={
"vision": False,
"function_calling": True,
"json_output": True,
"family": "unknown",
},
)
3.用例结果调优:
-
-
在 PRD 中明确需求细节(如边界值、异常场景)。
-
调整 AutoGen 的提示词(prompt),增加生成用例的精准度。
-
调整不同 AI模型,例如:Qwen/QwQ-32B、deepseek-ai/DeepSeek-R1
-
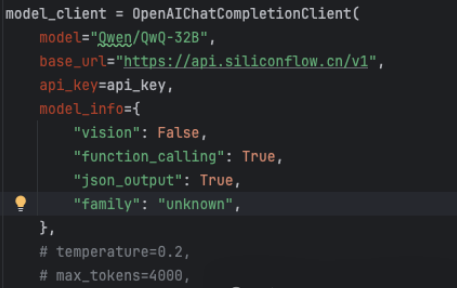
-
-
文件过大时,建议将需求拆成模块,阶段分别生成对应用例,单次生成用例数在30条内
-
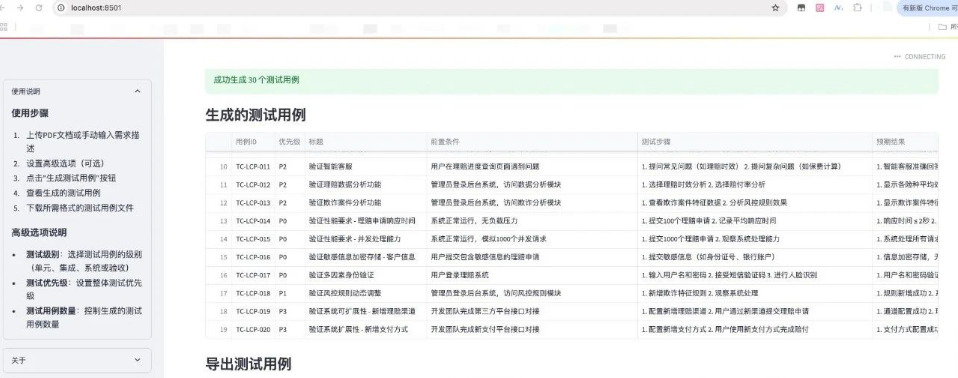
七、总结
通过 Streamlit + AutoGen + DeepSeek 的组合,测试工程师可以:
-
快速解析 PRD 文件,无论是上传 PDF 还是手动输入内容,都能高效生成测试用例。
-
支持多种格式导出,满足不同团队的需求(如 Excel 用于测试管理工具、Markdown 用于文档共享)。
-
提升测试设计效率,将需求到测试用例的转化时间从几周缩短到几分钟。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



















 81
81

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









