







1 前期准备
1.1 采集数据
采集有关南京博物院的有关数据,并进行中文分词(其中还需要用户自定义词典),其主要技术为:python爬虫、 jieba分词
内容如下:

1.2 构建语料库
根据已经采集好的数据构建语料库,其相关技术:MITIE工具
2 RASA_NLU
NLU模块的任务是:
- 意图识别 (Intent):在句子级别进行分类,明确意图;
- 实体识别(Entity):在词级别找出用户问题中的关键实体,进行实体槽填充(Slot Filling)。
2.1 进行rasa_nlu配置
配置文件如下:
language: "zh"
pipeline:
- name: "nlp_mitie"
model: "data/total_word_feature_extractor.dat"
- name: "tokenizer_jieba"
user_dicts: "./user.dict"
- name: "ner_mitie"
- name: "ner_synonyms"
- name: "intent_entity_featurizer_regex"
- name: "intent_featurizer_mitie"
- name: "intent_classifier_sklearn"
2.2 准备训练数据
数据格式如下:

2.3 训练
代码如下:
from rasa_nlu.training_data import load_data
from rasa_nlu.config import RasaNLUModelConfig
from rasa_nlu.model import Trainer
from rasa_nlu import config
from rasa_core.agent import Agent
from rasa_core.policies.memoization import MemoizationPolicy
from rasa_core.interpreter import RasaNLUInterpreter
from rasa_core.policies.keras_policy import KerasPolicy
from rasa_core.channels.console import ConsoleInputChannel
# 训练模型
def train():
# 示例数据
training_data = load_data('data/museum.json')
# pipeline配置
trainer = Trainer(config.load("sample_configs/museum_config.json"))
trainer.train(training_data)
model_directory = trainer.persist('./models/demo/')
print(model_directory)
predict(model_directory)
# 识别意图
def predict(model_directory):
from rasa_nlu.model import Metadata, Interpreter
interpreter = Interpreter.load(model_directory)
# 使用加载的interpreter处理文本
print (interpreter.parse(u"这里有什么好看的展览"))
if __name__=='__main__':
train()
2.4测试rasa_nlu

3 RASA_CORE
3.1 定义domain.yml
格式如下:
3.2 进行在线学习
代码如下:
from rasa_nlu.training_data import load_data
from rasa_nlu.config import RasaNLUModelConfig
from rasa_nlu.model import Trainer
from rasa_nlu import config
from rasa_core.agent import Agent
from rasa_core.policies.memoization import MemoizationPolicy
from rasa_core.interpreter import RasaNLUInterpreter
from rasa_core.policies.keras_policy import KerasPolicy
from rasa_core.channels.console import ConsoleInputChannel
def train_online(input_channel=ConsoleInputChannel(),
interpreter=RasaNLUInterpreter("models/demo/default/model_20180701-171646"),
domain_file="data/domain.yml",
training_data_file="data/museum_story.md"):
agent = Agent(domain_file,
policies=[MemoizationPolicy(), KerasPolicy()],
interpreter=interpreter)
agent.train_online(training_data_file,
input_channel=input_channel,
max_history=2,
batch_size=50,
epochs=200,
max_training_samples=300)
if __name__=='__main__':
train_online()
训练过程如下:
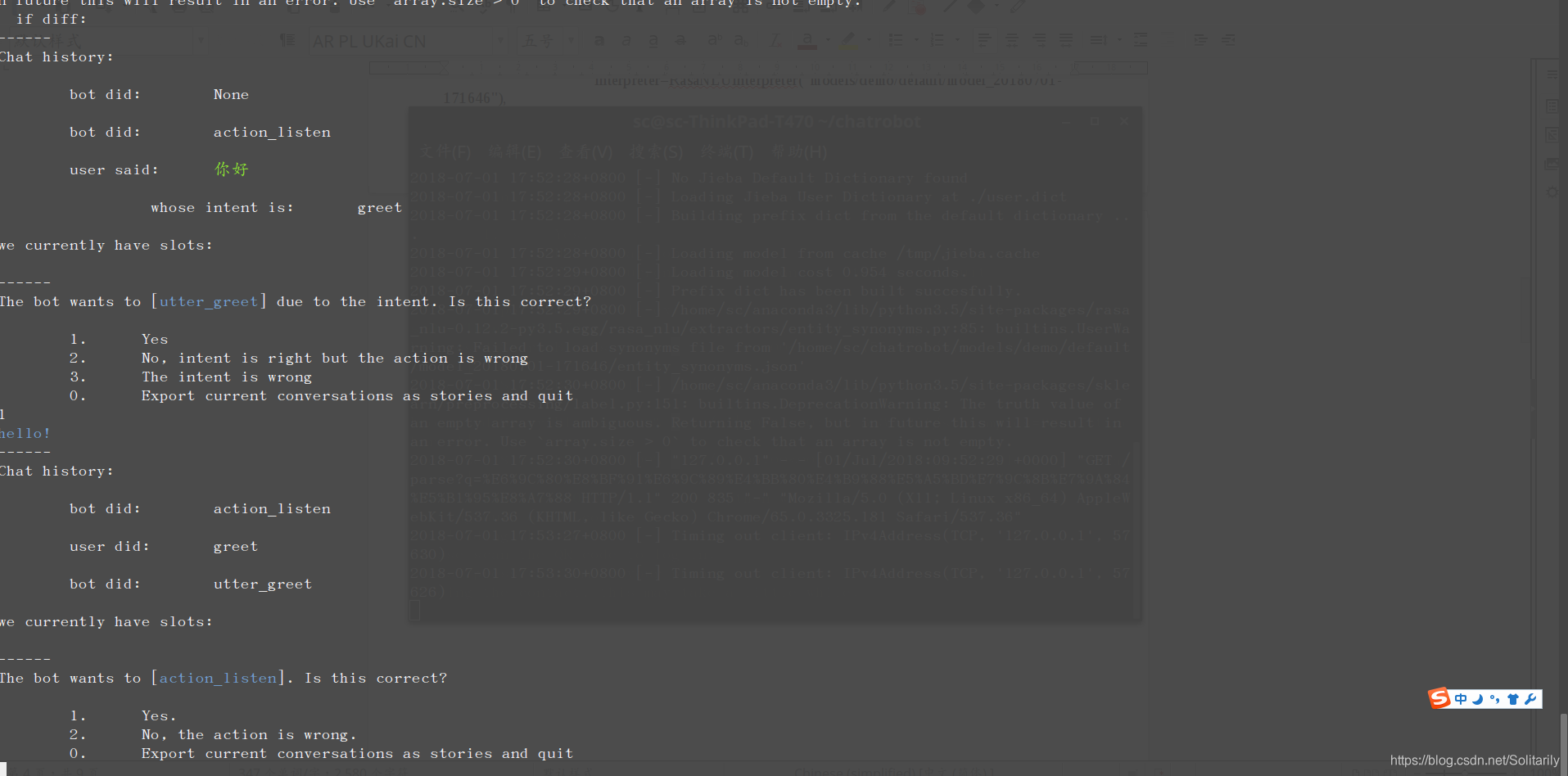
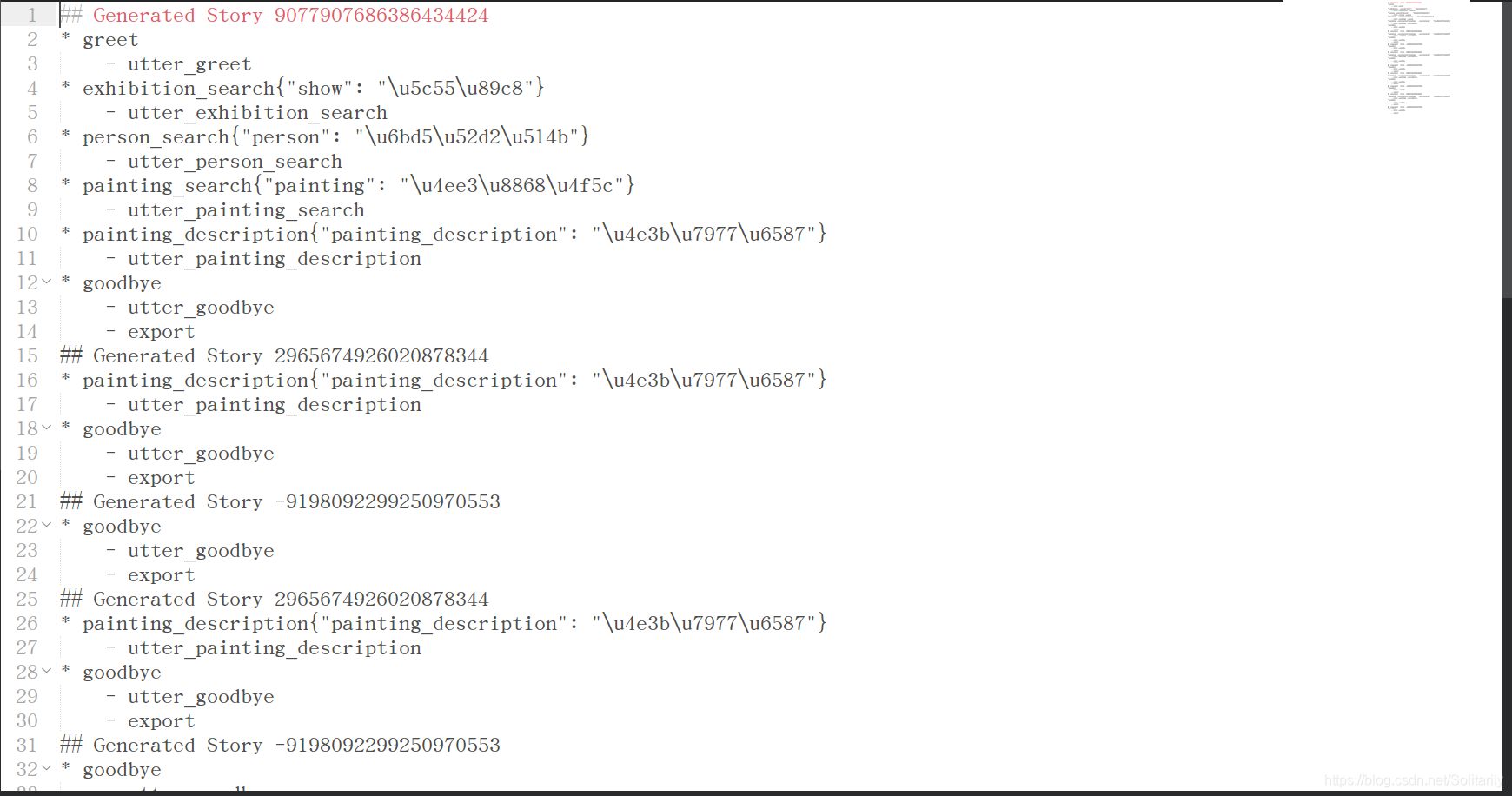
最终得到stories.md
格式如下:
3.3 训练对话
采用LSTM网络训练对话
代码如下:
from rasa_nlu.training_data import load_data
from rasa_nlu.config import RasaNLUModelConfig
from rasa_nlu.model import Trainer
from rasa_nlu import config
from rasa_core.agent import Agent
from rasa_core.policies.memoization import MemoizationPolicy
from rasa_core.interpreter import RasaNLUInterpreter
from rasa_core.policies.keras_policy import KerasPolicy
from rasa_core.channels.console import ConsoleInputChannel
def train_dialogue(domain_file="data/domain.yml",
model_path="models/dialogue",
training_data_file="stories.md"):
agent = Agent(domain_file,policies=[MemoizationPolicy()])
agent.train(
training_data_file,
max_history=3,
epochs=100,
batch_size=50,
augmentation_factor=50,
validation_split=0.2
)
agent.persist(model_path)
if __name__=='__main__':
train_dialogue()
4 微信展示
4.1 前言
由于域名需要备案(正在审查),所以微信小程序的接口不能申请成功,于是调用了微信的接口实现了对话过程。并且这里的代码将回答直接写进代码只作为测试使用,并没有去数据库查询数据。
代码如下:
from wxpy import *
import requests
bot = Bot(cache_path=True)
friend =bot.friends().search('蒋双庆')[0]
@bot.register()
def reply_msg(msg):
url = 'http://127.0.0.1:5005/conversations/default/parse'
p = {'query':msg.text}
r = requests.get(url, params=p)
intent = r.json()['tracker']['latest_message']['intent']['name']
if(intent=='greet'):
msg.reply("您好!我是您的专属智慧导游“小博”!")
elif(intent=='goodbye'):
msg.reply('再见!')
elif(intent=='person_search'):
msg.reply('弗朗特斯克·毕勒克,19世纪末20世纪初捷克新艺术运动的杰出代表。他和其他艺术家一样“还生活于艺术”,又和其他艺术家不一样,用自己的艺术感觉在宗教和神秘中找寻曾经的安全感。')
msg.reply_image('images/1.jpg')
elif(intent=='exhibition_search'):
msg.reply('近期有一场新的展览“毕勒克——捷克新艺术运动大师”,展出毕勒克绘画、雕塑等35件作品,展现了他“还生活于艺术”的创作理念,也表达了对人类命运的反思。')
elif(intent=='painting_search'):
msg.reply('弗朗特斯克·毕勒克的主要代表作有《主祷文》、《我的太阳》、《手》等等')
elif(intent=='painting_description'):
msg.reply('《主祷文》是耶稣基督传给门徒的祷告词,是礼拜仪式中通用的祈祷文。毕勒克认为艺术是生活的表现,生活因真理而存在,他的艺术态度即为宗教忏悔。创作这几幅《主祷文》主题的画作时毕勒克28岁,年轻的他在作品中表现出神奇的洞察力,并用奇特的表现手法,展露了与众不同的艺术风格。')
msg.reply_image('images/2.jpg')
embed()
4.2 对话过程展示
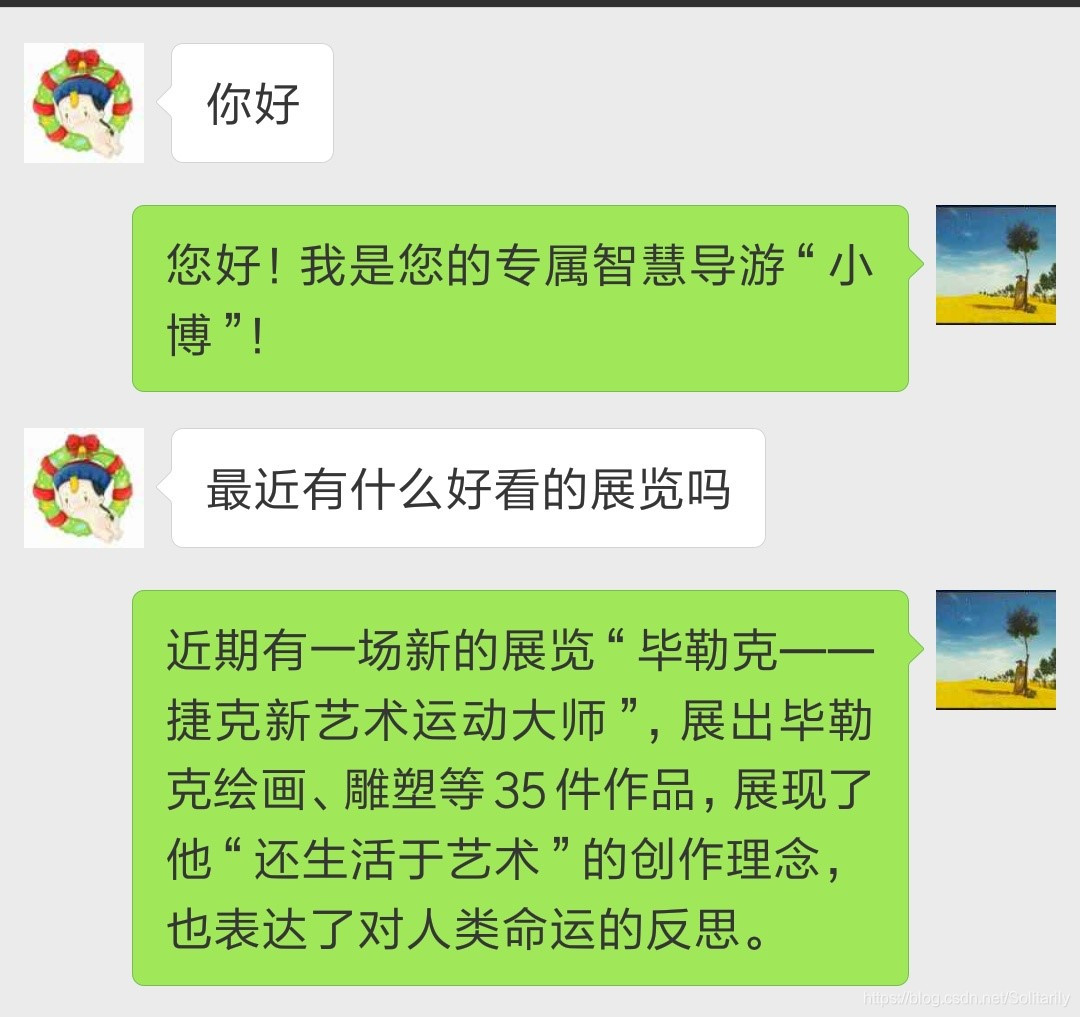
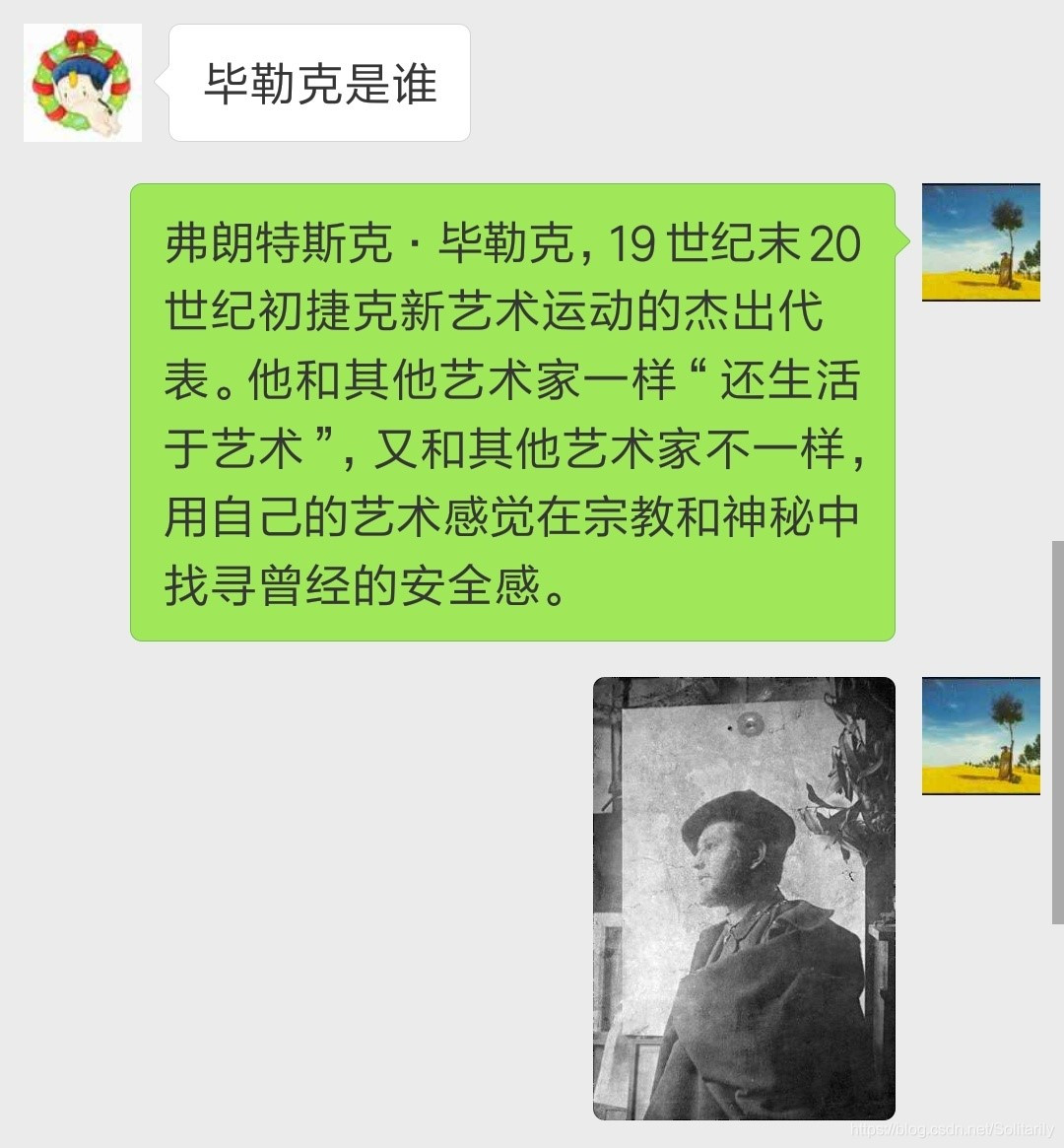
















 1817
1817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









