







常见面试题(一)~特征工程
特征工程
1 归一化
* 为什么需要对数值类型的特征做归一化?
答:消除数据特征之间的量纲影响,防止数据间悬殊过大。(数据间悬殊越大,收敛越慢)
- 对数值类型的特征如何做归一化:
(1)线性函数归一化(Min-Max Scaling)
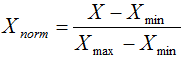
(2)零均值归一化(Z-Score)
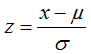
Z-score的结果是将原始数据映射到均值为0、标准差为1的分布上
适用性:
通过梯度下降求解的模型通常需要归一化,例如线性回归/逻辑回归/神经网络/SVM…
决策树等少数模型是通过信息增益来划分属性,不需要归一化
2 类别特征
* 在对数据进行预处理时,应该怎样处理类别特征?
(1)序号编码
处理具有大小关系,如对成绩分成低中高三段
(2)独热编码
处理不具有大小关系
若类别取值较多,注意:
①使用稀疏向量来节省空间
②配合特征选择来降维
- K近邻中,高维空间下两点之间的距离很难有效衡量
- 高维会过拟合
- 只有部分特征有贡献
(3)二进制编码
核心思想:利用二进制对ID进行哈希映射,最终得到0/1特征向量,且维数少于独热编码,节省了存储空间(如对A,B,AB,C型血中AB,独热(0,0,1,0),二进制(110))
3 组合特征
* 什么是组合特征?如何处理高维组合特征?
例如将一阶离散特征两两组合成高阶特征,若组合的特征维度太高,例如将用户ID与电影类型组合,可以将两种特征分别降成低维再组合
4 文本表示
* 有哪些文本表示模型?它们各有什么优缺点?
(1) 词袋模型和N-gram模型
词袋模型:相当于一袋子词,不考虑顺序
TF-IDF:

TF:单词t在文档d中出现频率
IDF:逆文档频率,衡量单词t的语义重要性
N-gram模型:将连续出现的n个词(n≤N)组成的词组也作为一个单独的特征放到向量表示中去
(2) 主题模型
用于从文本库中发现有代表性的主题(得到每个主题上面词的分布特性),并且能够计算出每篇文章的主题分布
(3) 词嵌入与深度学习模型
核心思想:将每个词都映射成低维空间上的稠密向量
深度学习模型通过多层神经网络提取文本不同特征,与全连接网络相比,抓住了文本特性;减少了待学习参数,提高训练速度;减少过拟合风险
5 Word2Vec(常用词嵌入模型)
Word2Vec是常见词嵌入模型之一,是浅层神经网络,有两种网络结构:CBOW和Skip-gram
* Word2Vec是如 何工作的?它和LDA有什么区别与联系?
CBOW是根据上下文出现的词语来预测当前词
Skip-gram是根据当前词来预测上下文中各词的生成概率
Word2Vec vs LDA
LDA利用文档中单词共现关系来对单词按主题聚类,也可以理解为对“文档-单词”进行矩阵分解,得到“文档-主题”和“主题-单词”两个概率分布
Word2Vec是对“上下文-单词”矩阵进行学习
联系:
主题模型通过一定的结构调整可以基于“上下文-单词”矩阵进行主题推理
词嵌入方法也可以根据“文档-单词”矩阵学习出词的隐含向量表示
主题模型 与词嵌入最大不同在于模型本身
主题模型是基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变量(即主题)
词嵌入模型的似然函数定义在网络的输出之上,需要通过学习网络的权重以得到单词的稠密向量表示
6 图像数据不足时的处理方法
* 图像分类时训练样本不足会有什么问题?如何缓解?
答:会导致泛化性能不佳
处理方法:
(1)基于模型的方法–降低过拟合
①简化模型(如将非线性转化为线性)
②正则化
③集成学习
④Dropout超参数…
(2)基于数据
根据一些先验知识,增大数据集(数据扩充或上采样<方法如SMOTE>)
这是读书笔记,后续看到同类面试题型的再整理更新把















 1535
1535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









