







文章目录
1 线程池
1.1 线程池的优点
- 降低资源开销。通过重复利用已创建的线程降低线程创建和销毁造成的开销。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性。
1.2 Executors工厂类
传统的线程池的创建方式是通过Executors工厂类的静态方法来创建的,根据方法的不同可以创建四种不同的线程池:
- newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程有新任务到来,会不断新建线程,导致线程最大并发数不可控制。
- newFixedThreadPool:创建一个固定大小的线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newSingleThreadExecutor:只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。
- ScheduledThreadPool:创建一个定时线程池,支持定时及周期性任务执行。
阿里巴巴开发手册中不允许使用Executors工厂类的静态方法去创建,而是用ThreadPoolExecutor的方式。因为Executors创建线程池对象存在弊端:
- FixedThreadPool和SingleThreadPool:允许阻塞队列的长度为Integer.MAX_VALUE,高并发的情况下可能会堆积大量的请求,导致OOM异常。
- CachedThreadPool和ScheduledThreadPool:允许创建线程数量为Integer.MAX_VALUE,高并发的情况下可能会创建大量的线程,导致OOM异常。
1.3 ThreadPoolExecutor类
由于存在上述缺点,所以禁止使用Executors工厂类创建线程。推荐使用ThreadPoolExecutor类来创建线程,ThreadPoolExecutor类构造函数有七大参数:
- int corePoolSize(线程池基本数量)
- int maximumPoolSize(线程池最大数量)
- long keepAliveTime(线程活动保持时间)
- TimeUnit unit(keepAliveTime的单位)
- BlockingQueue< Runnable > workQueue(阻塞队列),用于保存等待执行的任务的阻塞队列:
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO原则。
- LinkedBlockingQueue:基于链表结构的阻塞队列,FIFO原则,吞吐量较高。
- SynchronousQueue:不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue。
- PriorityBlockingQueue:具有优先级的无限阻塞队列。
- ThreadFactory threadFactory:用于设置创建线程的工厂,默认使用Executors.defaultThreadFactory()。
- RejectExecutionHandler handler(拒绝策略或饱和策略),队列满了且正在运行的线程数超过最大线程数,使用饱和拒绝策略来执行任务:
- AbortPolicy(默认):直接抛出异常。
- CallerRunsPolicy:由向线程池提交任务的线程来执行该任务
- DiscardOldestPolicy:抛弃最旧的任务(最先提交而没有得到执行的任务)
- DiscardPolicy:不处理,丢弃掉。
1.4 execute()和submit()
1.4.1 执行任务方式
线程池执行任务有两种方法:execute()和submit()。其中execute()方法只能传入Runnable任务,而submit()可以传入Runnable任务和Callable任务。由于Runnable任务无返回值而Callable任务可以有返回值,所以:
- execute()用于提交不需要返回值的任务,所以不会阻塞线程,并且无法判断任务是否被线程池执行成功与否。
- submit()用于提交需要返回值的任务。线程池会返回一个Future类型的对象,通过这个Future对象获得任务执行状态和返回值。当我们调用get()获得线程的执行结果时会阻塞当前线程,直到任务完成。
1.4.2 线程池执行出现异常
- execute()方法:如果有异常,线程终止,等待垃圾回收。
- submit()方法:如果有异常,在future对象中调用get()方法时抛出。此外,该线程仍可复用,不会被JVM回收。
1.5 线程池配置
线程池的配置需要考虑多种因素:
- 任务的性质:CPU密集型任务配置少线程,I/O密集型配置多线程。
- 任务的依赖性:即对下游系统的依赖,比如下游任务是去访问数据库,那么应该控制线程数量,防止压垮数据库。
- 内存使用率:线程数过多和队列的大小都会影响此项数据,合理配置线程数和队列,不让内存总居高不下。
因此,对于核心线程数,应当进行如下考虑:(N为CPU数量)
- CPU密集型:核心线程数= N+1
- I/O密集型:核心线程数=2N
- 混合型:核心线程数=(线程等待时间/线程CPU时间+1)* N
2 工作原理
2.1 线程池工作原理
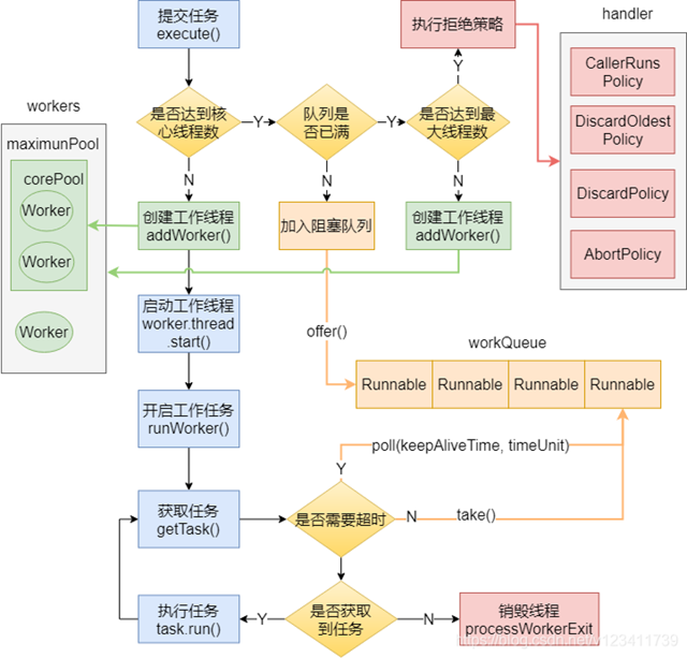
- 首先判断核心线程数corePoolSize:如果正在运行的线程数量小于核心线程数,那么会创建工作线程(通常也被称为核心线程)运行这个线程任务。
- 否则,就会判断阻塞队列workQueue:如果队列未满,能够放入该线程任务,那么就会将这个线程任务放入阻塞队列中。
- 否则,就会判断最大线程数maximumPoolSize:如果正在运行的线程数量小于最大线程数,那么会创建工作线程(通常也被称为非核心线程)运行这个线程任务。
- 否则,线程池会使用饱和拒绝策略来执行该线程任务。
工作流程核心代码如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 首先判断核心线程数corePoolSize
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 判断阻塞队列workQueue
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
// 在addWorker方法中会判断最大线程数maximumPoolSize
addWorker(null, false);
}
else if (!addWorker(command, false))
// 使用饱和拒绝策略
reject(command);
}
当一个线程完成任务时,它会从队列中取下一个任务来执行,当一个线程无事可做超过存活时间keepAliveTime时,线程池会判断:如果当前运行的线程数大于核心线程数,那么这个线程就会被停掉。所以,线程池的所有任务完成后它最终会收缩到核心线程数的大小。
因此,线程池其实是没有区分核心线程和非核心线程的,都是一个Worker对象(该对象实现了Runnable接口)。通过引入corePoolSize和maximumPoolSize的概念,仅仅是在数量逻辑上进行区分,并没有实际区分核心线程和非核心线程的数量,这样可以在资源复用性和内存占用率做一个平衡。
final void runWorker(ThreadPoolExecutor.Worker w) {
Thread wt = Thread.currentThread();
// 省略代码
try {
// getTask()是到阻塞队列中获取任务,会有两种结果,一是获取到了,二是超时返回null
while (task != null || (task = getTask()) != null) {
// 省略代码
}
} finally {
processWorkerExit(w, completedAbruptly);
}
}
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
// 省略代码
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 如果timedOut为true
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
// 如果取不到任务,会将timedOut置为true
try {
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
2.2 钩子函数
ThreadPoolExecutor为提供了三个钩子函数:
- beforeExecute:在执行任务之前回调
- afterExecute:在任务执行完后回调
- terminated:在线程池中的所有任务执行完毕后回调
因此,我们可以对ThreadPoolExecutor做定制化加强,如埋点、数据统计等等。















 1522
1522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









