









蒙特卡罗树搜索
AlphaGo火极一时,最近还出了新版本AlphaGo Zero,而我甚至对原版的AlphaGo v13还不甚了解。在查阅了一些博客、论文和代码之后,大致了解了AlphaGo的基本组成,蒙特卡罗树搜索MCST正是最核心的框架,它连接了AlphaGo的其他组件,构成了完整的系统。本篇是我对MCST的一些理解,当然包含部分搬运,旨在记录和总结备用。
蒙特卡罗树搜索
数据结构
首先,顾名思义MCST是一棵树,但并非二叉树,实际上MCST每个结点的度(最多能有多少个儿子)都不同。MCST每一层对应于博弈双方的其中一个,而且是交替的。
其次,MCST的结点代表着一种游戏状态(下称state),在围棋中一个结点对应于一个棋面,在OXO游戏中一个结点对应于一个板面。父结点的state在一次操作(下称action)之后,变成子结点的state,每一个子结点对应着对手操作的一种可能性。任意一个结点都有三种可能的情况:
- 结点没有可拓展操作
- 结点还有可拓展操作
- 结点对应着对决终结
什么叫做“有可拓展操作”?对于任何一个state,拓展即“假设对手会这么做”,“有可拓展操作”就表示“还没模拟过这么做”,“没有可拓展操作”表示“已经考虑过所有的可能性”。
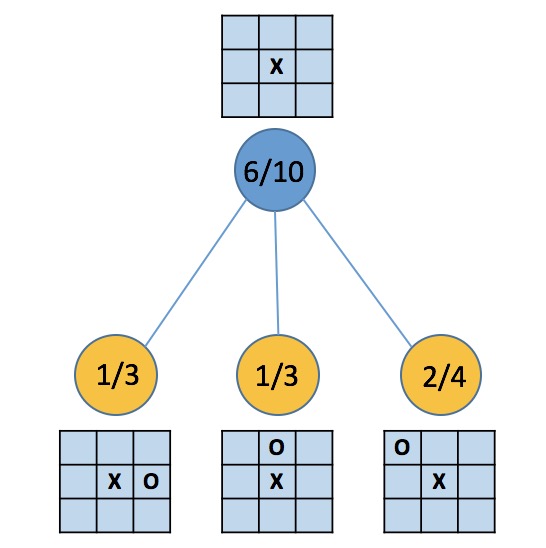
下面用图描述OXO游戏的MCST数据结构。第一幅图中,蓝和黄分别表示游戏双方,结点上显示了对应的state,以及两个数字W/V,其中W表示胜局次数,V表示模拟次数(他们怎么来的后面会说)。显然在蓝方落子之后,正中央已不可能落子,黄方仍有8种落子的可能性,图中只给出了三种,是因为10次模拟中只尝试了这三种(什么是模拟后面会说)。第一幅图的所有结点,都属于仍有可拓展操作的情况(情况二),蓝结点仍有9-1-3=5种操作未曾探索,三个黄结点各仍有9-2=7种操作未曾探索。
结点上的数字分别是W(赢的次数)和V(模拟次数),例如蓝结点被遍历了10次,或者说基于蓝结点的模拟进行了10次,蓝方胜利的次数为6,另一方面,黄结点1/3表明该结点被遍历3次,黄方胜利1次。注意所有黄色结点上W之和不等于蓝结点的W,这是因为各层结点都对应着对局其中一方的落子,胜利是站在当前落子方的角度而言的,图例从蓝方的角度出发,10次模拟中蓝方赢了6次,相对地,下一步黄方落子,三种落子方案下黄方分别赢了1次、1次、3次共4次,等价于蓝方赢了6次。
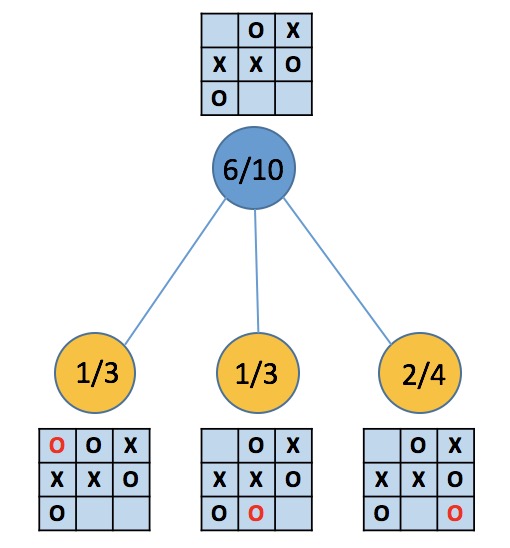
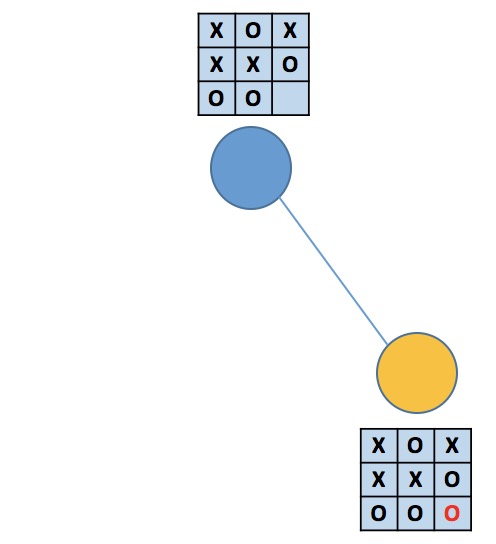
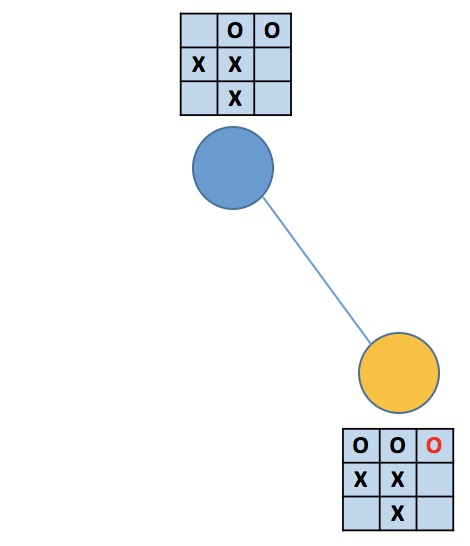
第二幅图中,蓝结点属于没有可拓展操作的情况(情况一),因为它的三个子结点分别模拟了剩余的三种落子情况。三个黄结点则各仍有2种操作未曾探索(情况二)。在第三幅图中,蓝结点属于情况一,因为它的儿子模拟了唯一可能的落子,而黄结点的state正好对应着游戏终局(情况三,当然也属于情况二),黄方赢了。第四幅图描述了没有到达无子可落的局面就分出胜负的情况,蓝结点属于情况二,黄结点属于情况二和情况三,黄方赢了(蓝方太蠢)。
基本步骤
首先对MCTS的四个步骤给出基本的描述:
- Selection 从根结点开始,选择评分最高的儿子,直到当前结点的下一可能性还没完全被探索,或已抵达对局结束。
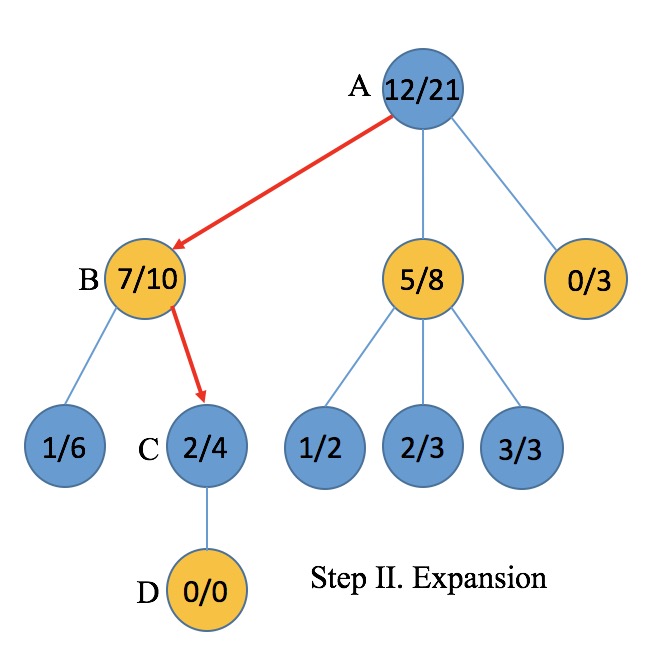
- Expansion 对于所选路径的叶结点,随机展开一个或多个操作action结点。
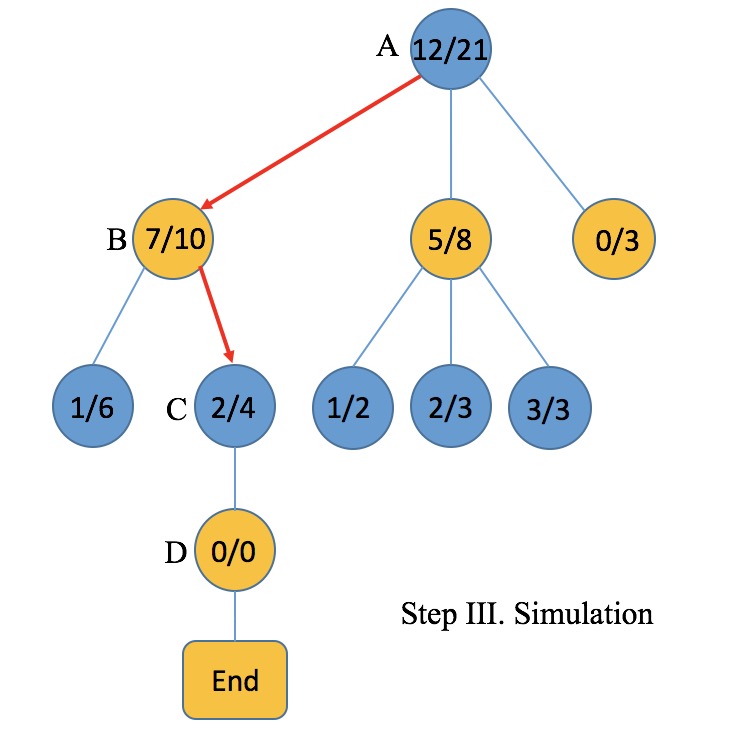
- Simulation 基于action进行快速对局模拟到对局结束。
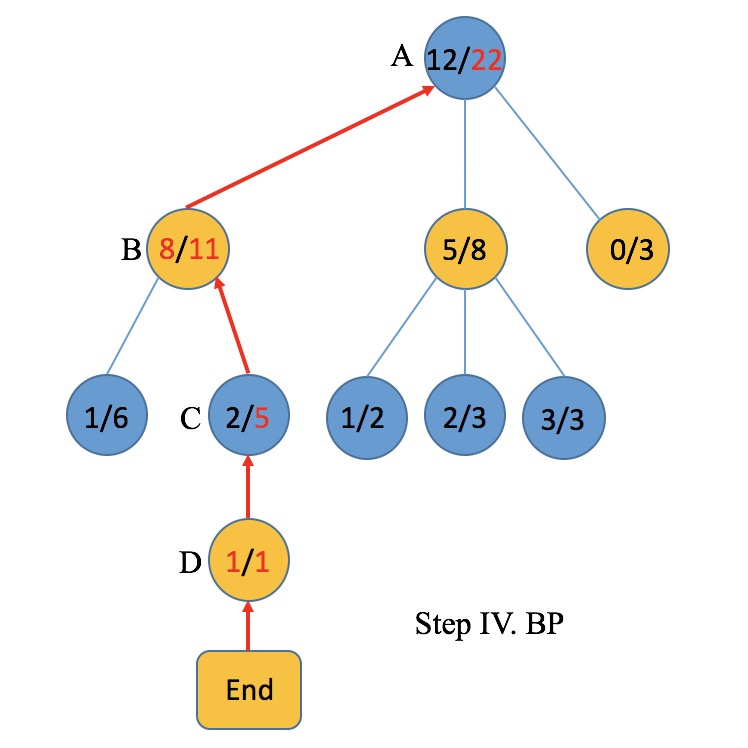
- BackPropagation 根据模拟胜负结果,自action结点至根结点,回溯更新路径上结点的信息。
对局举例
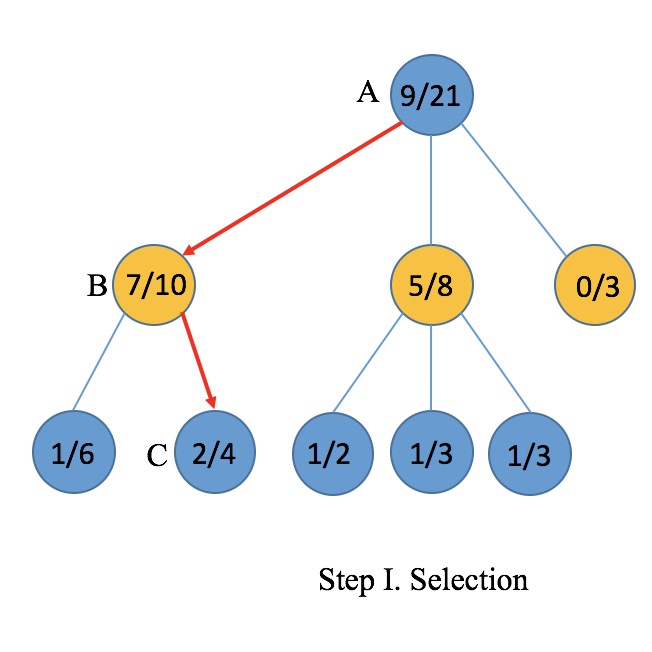
- Selection. Selection是一次从根到叶子遍历路径的过程,它有两个要点,第一,选择是有条件的,第二,选择是有规则的。首先,如果当前结点的不可继续拓展,且不对应于对决终局,才可继续选择。例如图中假设结点A、B的下一步操作都已被充分探索,C结点没有进行过拓展,所以最多到达C为止(见红色箭头)。其次,可以看出对决交替进行中,轮到任意一方时,它都会优先选择自己所有可行操作中赢面最高的一种。例如,在第二层轮到黄方行动,黄方经过之前的模拟已经尝试过了所有可能的操作,于是它根据之前模拟的胜率,选择了B对应的操作,接着轮到蓝方,按照相同的规则,蓝方选择了C对应的操作。可以看到,双方都在根据自己的模拟实验,确定并选择当前对自己最有利的做法。实际上“赢面”是由UCB公式决定:$$score=\frac{W_{child}}{V_{child}}+C\cdot \log \frac{V_{parent}}{1+V_{child}}$$
- Expansion. Expansion是在一个仍有探索空间的结点上随机进行一次操作选择的过程,对应到树结构中就是尝试添加一个叶子结点。例如在蓝方选择C操作之后,黄方还没有进行过任何模拟,于是随机选择一个位置落子(操作D),此时D上数字应标0/0,表示未曾遍历也没有胜局。
- Simulation. Simulation基于Expansion中选择的操作,进行快速走子模拟对局直到游戏结束。具体地,黄蓝交替完全随机落子,假设到对局结束时黄方获得了胜利。
- BackPropagation. BackPropagation是从Expansion的操作开始往根结点回溯的过程。在例子中,基于D的模拟结果是黄方取胜,因此按照路径D-C-B-A回溯,所有结点的遍历次数V加一,黄结点的胜局次数W加一。若模拟结果是蓝方取胜,则回溯中蓝结点胜局次数W加一。
任意一方落子时,都是一个决策的过程,有如下几个细节有助于理解整个过程:
- 一次决策(决定在何处落子)需要进行若干次(可能上百万次)迭代,每次迭代都以当前对局棋面为根结点,通过以上四个步骤进行一次模拟,多次迭代众多模拟提供了决策的参考,最终根据评分函数选择一个最有利的位置落子。
- 可以一边对决一边模拟,也可以预先进行过充分地模拟再进行对局。前者的开局可能对应于MCTS中一个完全没拓展探索过的根结点,于是在每次决策前都要进行相当充分的模拟,时间消耗大。后者的开局可能对应于一棵相当宽而深的数,极端情况下它在对决前模拟过所有对局情况。
- 一个预先进行充分训练(模拟)过的AI,可以从任意棋面开始对决,只需要以当前棋面为根结点进行搜索。
- 对决双方可以是同一个AI,但实际上真正使得AI进步的实际上是模拟次数,极端地,对于任意一种棋面state,AI都对未来的所有可能性进行过模拟(完全遍历),从而选出当前对自己最有利的操作。
- 简单的游戏由于操作的可能性少,因此可以通过遍历模拟所有对局情况,例如OXO的MCST最深能达到9层,对应于state满了的情况。围棋这样有19*19=361个落子点可能达到361层,短时间遍历所有对局显然是不可能的。
个人认为,MCTS提供了一种规避完全遍历而通过多次模拟获得次优解的方法。知乎某答案描述了一个黑箱子取苹果的问题,箱子中有n个苹果,要求取出最大的那个。于是我可以这样取苹果:先取出一个苹果,然后以后每次取苹果都比较一下,把小的那个放回去。于是经历m次之后我拿到了一个苹果,即使它可能不是最大的(最优解),但也比我之前拿到的都大(次优解)。这个比喻可能跟下棋的情况不太一样,但有助于理解。
AlphaGo
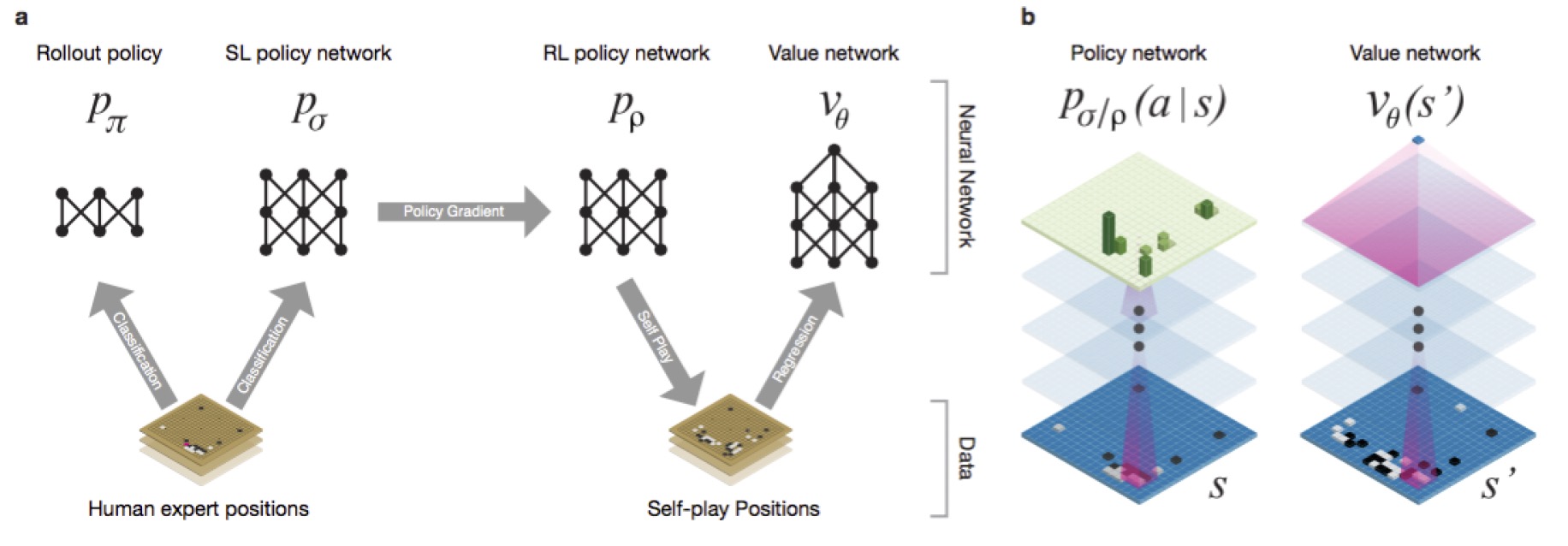
AlphaGo v13的基本原理不在这里过多叙述,只描述它是如何用MCTS将各个组件连接起来的。
AlphaGo的基本组件有四个,他们都是DCNN,包括一个基于SL(Supervised Learning)的策略网络 Policy Network,一个基于SL的快速走子网络 Rollout Network,一个基于RL(Reinforcement Learning)的策略网络,以及一个价值网络 Value Network。AlphaGo的MCTS的结点储存三个变量,评分Q值、遍历次数N和先验概率P。
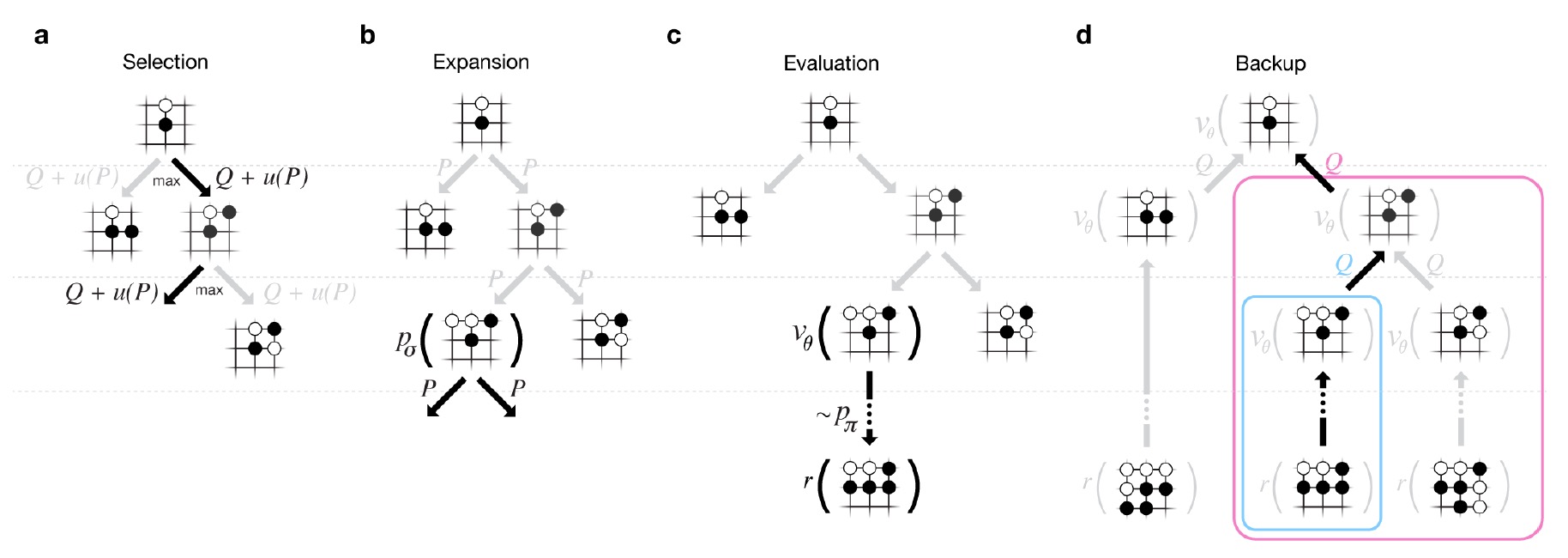
如图,MCTS的四步骤为:
- Selection。倾向于选择Q值大,赢面高(P大)和遍历次数较少的action。此处的P实际上是SL模型提供的概率$P_{\sigma}(a|s)$,而Q值正比于模拟评分。具体根据:$$a_t=arg\max_a (Q(s_t,a)+u(s_t,a))=arg\max_a (Q(s_t,a)+C\cdot \frac{P(s,a)}{1+N(s,a)})$$
- Expansion。随机选择一个落子位置,由SL决定结点上的先验概率P。
- Simulation&Evaluation。相比于普通的MCTS,此处增加了一个Evaluation,这是因为普通的MCTS直接以胜负(1或0)回溯更新。AlphaGo除了模拟胜负,还引入RL网络和价值网络进行评分,Value Network与RL有相似的网络结构和相同的参数,单值输出对决一方的胜率,s表示state,$V_{\theta}(s)$ 是价值网络输出,z是模拟的输赢(0或1)。最终评分公式为:$$V(s)=(1-\lambda)V_{\theta}(s)+\lambda z$$
- BackPropagation。从叶结点往根结点回溯,更新各结点上的Q值和N值。具体公式可见论文。
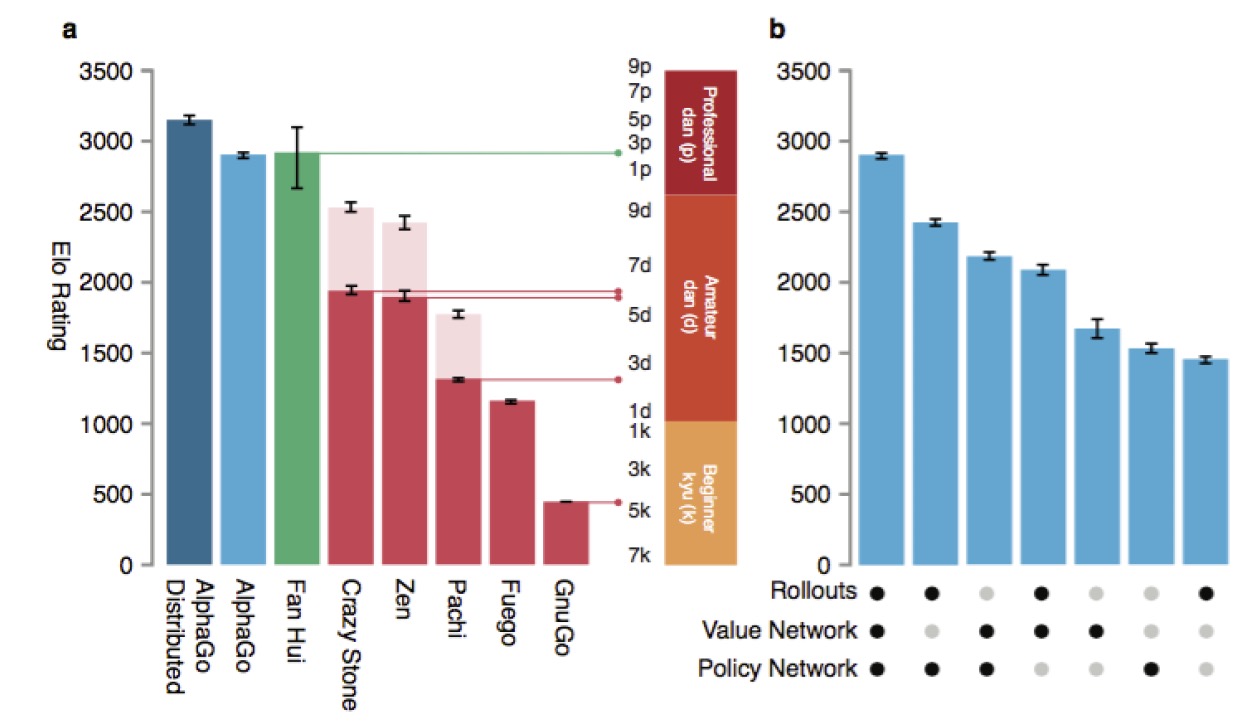
AlphaGo的训练不仅仅是对于对局的上百万次模拟从而统计胜率,还有针对MCTS的不同步骤设计了专门的DCNN并分别训练。各组件在Selection上帮助选路,在Simulation上帮助评估赢面,而AlphaGo跟自己进行模拟对局的过程中所产生的大量state,又可以进一步提供给网络进行训练(当然SL和rollout的训练核心还是去学习人类高手的下法,只有RL训练才是自己打自己)。AlphaGo的强大不仅仅依靠MCTS,更来自于各组件发挥的作用,如下图,虽然只有MCTS也可以实现,但当各组件逐个加入时,可以看到AlphaGo的棋力在不断提升。

















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









