






Learning materials
周彬:
官方文档就是最好的教程 docs.nvidia.com/cuda/ 文档很多,推荐前期重点读以下三份文档
CUDA C++ Programming Guide:介绍了CUDA C的编程模型,附录的内容也很丰富
CUDA C++ Best Practices Guide:介绍了怎样写CUDA会有更高的性能
Kernel Profiling Guide:介绍了如何profiling kernel,并透露了更多硬件实现上及kernel执行过程的细节
1. Philosophy
在进行CUDA编程之前,我们首先来看看什么样的程序是是何使用GPU进行加速的,
深蓝学院的老师是这样说的:
- 内存读写少
- 控制简单
- 计算简单
- 可并行度高
2. Basics
2.1 Official materials
CUDA Samples
GitHub repo: cuda-samples
2.2 nvidia-smi驱动显示信息
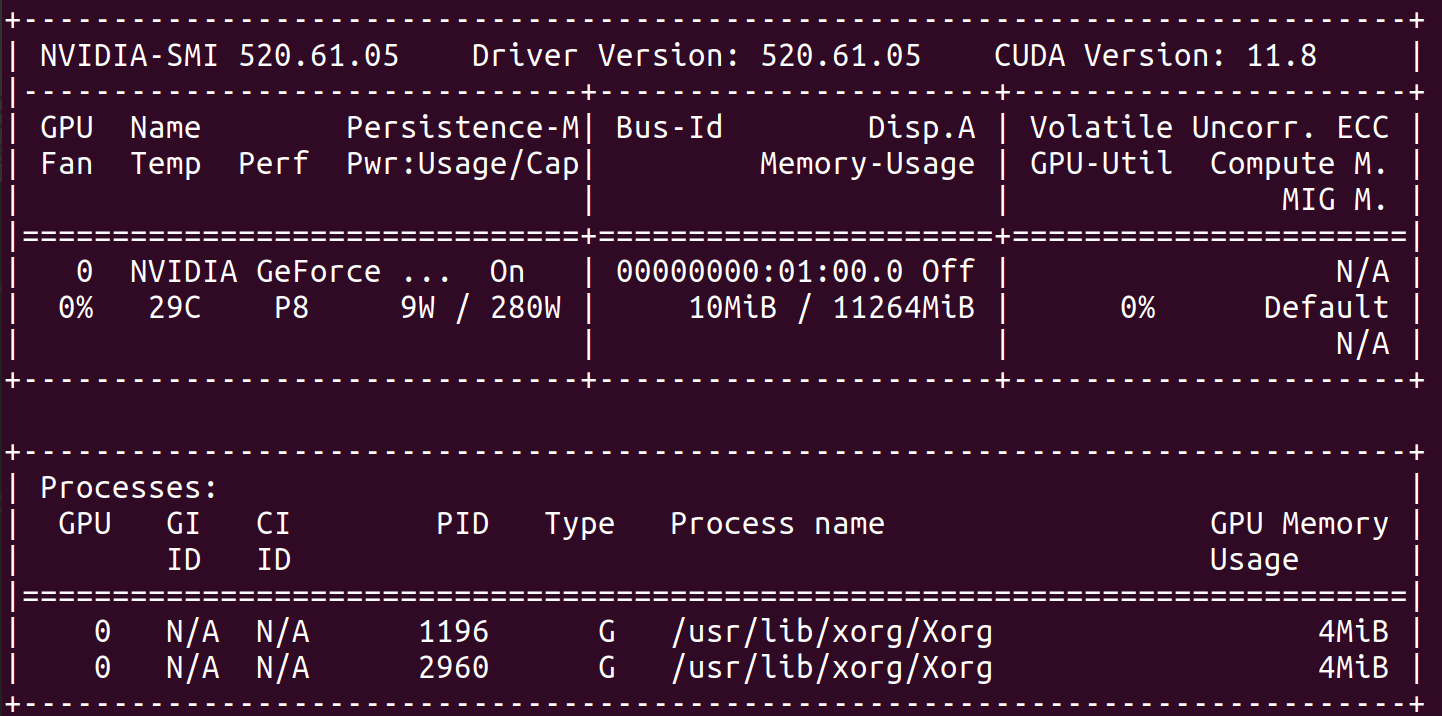
| Key | Value | Description |
|---|---|---|
CUDA Version | 11.8 | 即 DRIVER API COMPATIBILITY VERSION,表示当前驱动适配的最高CUDA版本,这里显示是11.8, 表示CUDA-11.8 以下的程序都是可以正常运行的。 |
2.3 GPUs specs
| GeForce RTX 2080 Ti | GeForce RTX 3070 Ti Laptop GPU | |
|---|---|---|
| GPU Engine Specs: | ||
| Processing Blocks (partitions) | 4 | 4 |
| NVIDIA CUDA® Cores | 4352 | 5888 |
| CUDA Cores / MP | 64 | |
| Maximum number of threads per block | 1024 | |
| Technology Support: | ||
| NVIDIA Architecture Name | Turing | Ampere |
Note:
CUDA没有提供查询显卡中 Tensor cores 数量的API,所以暂时无法通过API的方式确定 Tensor cores 的数量。
2.4 CUDA API hierarchy
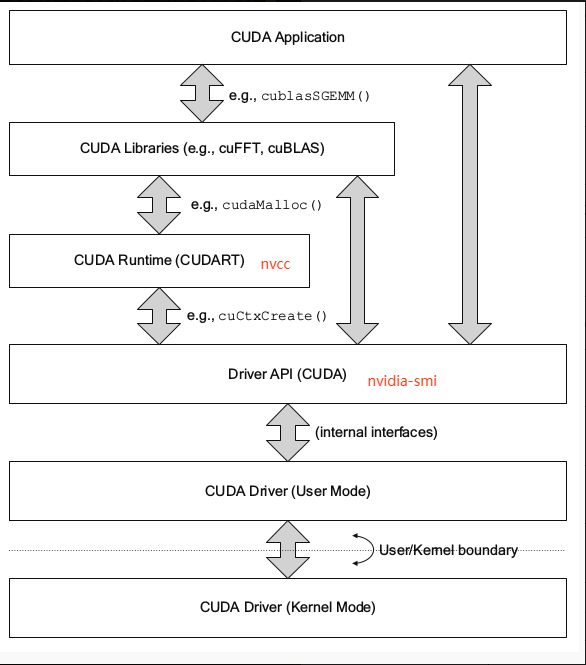
2.5 CUDA parallel model
| Abbreviation | Full name |
|---|---|
| SIMT | Single Instruction, Multiple Thread |
| SPMD | Single Program, Multiple Data |
| SP | Streaming Processor |
| SM | Streaming Multiprocessors |
| MP(=SM) | Multiprocessors |
2.5.1 Thread concepts correspondence
| Progam | Physical |
|---|---|
| thread | SP / core |
| (invisible) | warp (32 cores) |
| block | SM / multiprocessor |
2.5.2 Memory concepts correspondence
| Progam | Name | Affiliation | Max range |
|---|---|---|---|
__share__ | share memory (block) | block | sharedMemPerBlock(2080Ti: 48KB) |
| SM share memory | Total shared memory per multiprocessor | SM | sharedMemPerMultiprocessor(2080Ti: 64KB) |
Note:
在CUDA编程模型中,share memory是从属于block的概念;具体而言,sharedMemPerBlock表示在一个核函数中可以申请的共享内存的最大值,对于以下代码来说:// Matrix multiplication kernel called by MatMul() __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) { // Block row and column int blockRow = blockIdx.y; int blockCol = blockIdx.x; ... __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; ...}则是要求
As和Bs总共申请的内存大小不能超过sharedMemPerBlock返回的数值。
2.5.3 关于block池(block pool)的理解
这里援引杨老师关于 block pool 的解释(比较通俗易懂):
【关于block在CUDA中是如何被调度的】
杨老师:从硬件的角度给你们解释吧。
一个GPU是由多个SM组成的,SM之间共享L2 cache和显存,SM内私有 L1 cache(整个SM一个cache)和 shared memory。SM内有计算单元,控制单元,访存单元等等。
GPU内最小的执行单元是warp,最小的调度单元是block。一个block只能在一个SM上执行,一个SM上可以执行多个block。
我们以计算单元为假设,假设一个SM内有1024个计算单元,即同时最大可以执行1024个线程。
你写了一个kernel,有100个block,一个block里有256个线程。这么多block同时执行不了,所以就会有一个block池,等哪个SM的计算单元空闲了,调度单元就从池子里选一个ready状态的block发射给SM执行。
2.5.4 Block和warp的分配和调度由CUDA负责
关于“block到SM的分配”和warp的调度,杨老师在群里面说到:
杨老师:
block scheduler都不是透明的,warp scheduler就更别想了。
这说明“block到SM的分发”和warp的调度对开发者来说都是不透明的;
2.5.5 关于限制block并行数量的原因
- Shared memory limited case
- Register limited case
形象的示例如图所示:

Shared memory limited case
描述:在一个block中使用的共享内存的大小较大,是目前性能优化的瓶颈;
示例分析:例如,现在我们使用的显卡为2080Ti,使用deviceQuery.cu获得的硬件支持信息如下:
Maximum number of threads per block: 1024
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes (64KB)
设核函数kernel的代码为:
kernel<<<grid, 128>>> () {
…
# Shared memory申请大小为21KB
…
};
于是,我们分别从threads和 shared memory 的角度看看,单个SM中最多可以并行的block数量:
limit_threads: 1024/128 = 8
limit_shared_memory: 64//21 = 3
可以看到 limit_shared_memory的值为3,小于limit_threads,所以当前核函数中 shared memory 是主要的roofline。
2.5.6 SM同时最多计算64个数据点(2 warps)
因为每个SM包含64个 CUDA Cores。
2.6 GPU Memory
2.6.1 Shared memory
同一个线程块(Block)中的线程可以通过共享内存进行通信,这是线程协作中一种比较快的方式。
__syncthreads():线程同步
文档:CUDA Programming Guide :: __syncthreads()
在读写状态转换的时候,要进行线程同步;
2.6.2 Relationship
L1 cache & Shared memory
关于这两者的关系,深蓝学院的老师是这样说的:
LitLeo:
大部分显卡 L1 cache 和 shared memory 都是使用同一块存储(物理存储器),并且可以通过函数配置各自的大小;在默认情况下,两者是预设的固定大小,(并不会动态变化)。
表格展示了一般情况和使用 Shared memory 情况下的数据传输路径:
| Transference | Path |
|---|---|
| default | Global memory ⇒ L2 cache ⇒ Register |
__shared__ | Global memory ⇒ Shared memory ⇒ Register |
2.6.3 Array storage is column-major
在CUDA中,二维数组是以行优先形式存储的;
Note
关于数组(C-array)在CUDA的存储方式,我们在 CUDA-doc 中并没有找到明确的说明;对此,我们在 NVIDIA Forums 上进行了提问,CUDA工程师回复了我们,Robert_Crovella:
There is no 2D-array or multidimensional array in CUDA C++ that is any different than C++. The storage behavior of C-style arrays in CUDA follows the C++ specification. And, for what it is worth, that is not a column-major storage format/specification.CUDA中数组的内存排列方式和C++(“C++ specification”,C++规范)相同。
CUDA编程中为什么一般会把高维张量转换为一维数组再进行计算呢?
这是因为一维数组的访存效率要高于多维数组;
这里我们引用一些开发者的解释:
未雨:
一维数组相较多维数组的好处:
- 存储开销少,一维数组只需要一个指针,多维数组除了最后一维外都需要存指针,需要 D 1 ∗ D 2 ∗ . . . ∗ D N − 1 D_1 * D_2 * ... * D_{N-1} D1∗D2∗...∗DN−1个指针
- 访问效率高,一维数组算出index后只需要一次访存就能拿到对应元素,多维数组需要N次
2.7 Error checking
| A | B |
|---|---|
| cudaError_t |
关于在CUDA编程中进行 error checking 的意义,请参考《tensorRT从零起步高性能部署:初始化和检查的理解,CUDA错误检查习惯》
编写方式:
- 使用
inline说明符;
3. Device information
| A | B |
|---|---|
| cudaGetDeviceCount |
Get device properties
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop,0));
printf("prop.sharedMemPerBlock = %.2f KB\n", prop.sharedMemPerBlock/1024.0f);
4. C++ environment
NVCC支持的C++标准:Select a particular C++ dialect | NVCC :: CUDA Toolkit Documentation
CPP_STANDARD ≤ C++17
Gcc版本要求:1.1. System Requirements | Native Linux Distribution Support in CUDA 11.7
4.2 Windows配置
MSVC编译器路径示例:
"C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.34.31933\bin\Hostx64\x64\cl.exe"
5. File
5.1 Format
头文件:.cuh
CUDA-CPP文件:.cu
5.2 Header
CUDA header:
#include <cuda_runtime.h>
Cublus header:
#include <cublas_v2.h>
Note:
对于为什么#include <cublas_v2.h>有一个v2,这是因为v2表示新版的API;而不加v2,则使用的是旧版的API;具体的说明,可以查看cublas的关于API引入的说明文档。
6. Context (CUDA Driver API)
cuContext使用起来有一点像一个任务队列;
7. Stream:异步的任务队列
CUDA-stream有点类似于CPU中的thread,可以并行执行多个串行任务;
8. Data copying
CudaMemcpyAsync():异步数据拷贝
文档:CUDA Runtime API :: cudaMemcpyAsync()
cudaMemcpyAsync()在使用时,需要传入 cuda_stream对象;
9. Function
SM包含的最大warp数量:32
Block中包含thread的最大数量:1024
(
=
32
×
32
)
(= 32\times 32)
(=32×32)
9.1 __global__: kernel function
文档:CUDA Programming Guide :: __global__ function
__global__修饰的函数是核函数,这些函数在GPU上执行 ,但是需要在CPU端调用;
《CUDA并行程序设计 - GPU编程指南》:
所谓的内核函数就是一个只能在GPU上执行而不能直接在CPU上执行的函数。
并行块大小Db:不能超过maxThreadsPerBlock。
返回值:必须为void。
异步性:核函数是异步的,会立即返回。
__global__函数支持CPP-style的多维数组索引
经过查看 CUDA Forum 中的帖子,我们知道CUDA是不支持CPP-style的多维数组,也就是说,无法在__global__函数中以“d_array[i][j]”的形式索引二维数组;
示例代码:CUDA_2d_array
GridID & blockID 的计算
int blockId = blockIdx.z * gridDim.x * gridDim.y +
blockIdx.y * gridDim.x +
blockIdx.x;
int threadId = blockId * (blockDim.z * blockDim.y * blockDim.x) +
(threadIdx.z * (blockDim.y * blockDim.x)) +
(threadIdx.y * blockDim.x) +
threadIdx.x;
【南溪笔记】关于block与SM关系的理解
一个block会被分配到一个SM上,而一个SM可能会有多个block同时存在;
“block分配给SM”这个过程是由CUDA自身进行协调的,而不是由编程人员自己定义的,也就是说对编程人员是不透明的。
std::cout不能在__global__函数中使用
std::cout不能在__global__函数中使用,会报错:

需要使用printf();
10. Array
CUDA核函数中是可以使用二维数组的,请参考“CUDA 2D-array by an array of pointers to 1D arrays”
11. CUDA event
| A | B |
|---|---|
| cudaStream_t | |
| cudaEventRecord() |
cudaEventRecord
文档:CUDA Programming Guide :: cudaEventRecord()
12. Matrix-matrix operations
12.1 CuBLAS:NVIDIA官方提供的线性代数计算库
| CuBLAS API Level | Operations |
|---|---|
| Level-1 | perform scalar and vector-based operations |
| Level-2 | perform matrix-vector operations |
| Level-3 | perform matrix-matrix operations |
11.1.1 Basics
函数命名解析:以cublasSgemm为例
cublasSgemm ⇒cublas·S·gemm
cublas:函数库名称;
S:单精度浮点数(Single Precision Floating Point);
gemm:表示 general Matrix Multiply ,即一般矩阵乘法。
| 常见缩写 | 全称 | 含义 |
|---|---|---|
| gemv | general matrix-vector multiply | 一般矩阵&向量乘法 |
| gemm | general matrix multiply | 一般矩阵乘法 |
transa & transb:矩阵变换参数
transa | transb是cublas库中指定矩阵变换的参数,它可以设置三种不同的值:
- 如果transa设置为
CUBLAS_OP_N,表示对矩阵A进行原样计算,即不做任何变换。 - 如果transa设置为
CUBLAS_OP_T,表示对矩阵A进行转置,即将矩阵A中的行和列进行交换。 - 如果transa设置为
CUBLAS_OP_C,表示对矩阵A进行共轭转置,即将矩阵A中的实部和虚部进行交换。
这个参数主要用于调整矩阵A的结构,以满足矩阵乘法运算的要求。
cublasSetStream():cublas默认使用同步流
Cublas在默认情况下使用同步流,为了实现GPU的异步运算,需要显式地设置cublas的任务流;
11.1.2 Matrix-to-matrix Multiply:矩阵乘法
12. CMake configuration for CUDA
CMakeLists.txt模板下载:
wget https://raw.githubusercontent.com/songyuc/Cuda_notes/master/CMakeLists.txt
CMakeLists.txt模板代码:
cmake_minimum_required(VERSION 3.23)
set(CMAKE_CUDA_COMPILER "/usr/local/cuda/bin/nvcc")
# NECESSARY: because we need to specify the CUDA_COMPILER explicitly.
if(NOT DEFINED CMAKE_CUDA_ARCHITECTURES)
set(CMAKE_CUDA_ARCHITECTURES "75;80;86")
endif()
# Note: This variable is used to initialize the CUDA_ARCHITECTURES property on all targets.
project(Cuda_notes LANGUAGES CUDA CXX C)
set(CMAKE_CXX_STANDARD 23)
set(CMAKE_CUDA_STANDARD 14)
set(CMAKE_CUDA_STANDARD_REQUIRED ON)
include_directories(SYSTEM "${CMAKE_CUDA_TOOLKIT_INCLUDE_DIRECTORIES}")
include_directories("${CMAKE_SOURCE_DIR}/cuda-samples/Common")
include_directories(.)
add_executable(Cuda_notes deviceQuery.cu)
target_link_libraries(Cuda_notes cudart)
包含CUDA代码的文件一定要以.cu结尾才能触发nvcc的编译;
5.1 CMAKE_CUDA_ARCHITECTURES
CMAKE_CUDA_ARCHITECTURES用来指定目标显卡的架构算力,内部是用来设置CUDA_ARCHITECTURES变量的值,关于CUDA_ARCHITECTURES变量的具体含义,请参考文档 CUDA_ARCHITECTURES — CMake Doc
13. CUDA debugging: NVIDIA Nsight
13.1 VSCode: NVIDIA Nsight Visual Studio Code Edition
视频教程:CUDA Support in Visual Studio Code with Julia Reid
14. Profiling
| Abbreviation | Full Name |
|---|---|
| NVVP | NVIDIA Visual Profiler |
14.1 C++代码测试CUDA代码的运行时间
文档:CUDA Programming Guide :: Using CUDA GPU Timers
官方模板:
cudaEvent_t start, stop;
float time;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord( start, 0 );
kernel<<<grid,threads>>> ( d_odata, d_idata, size_x, size_y,
NUM_REPS);
cudaEventRecord( stop, 0 );
cudaEventSynchronize( stop );
cudaEventElapsedTime( &time, start, stop );
cudaEventDestroy( start );
cudaEventDestroy( stop );
使用lambda表达式封装核函数调用
auto launch_kernel = [=]() { // 使用值捕获传递显存数组
traverseArray<<<gridSize, blockSize>>>(d_array, width, height);
};
14.2 Nsight: NVIDIA Nsight Systems
Nsight是NVVP和nvprof的继任者,(NVVP和nvprof在之后的CUDA版本中会被淘汰掉);
Legacy: NVVP
关于NVVP的使用教程,请参考《深蓝学院 - 深度神经网络加速:cuDNN 与 TensorRT - 第3章:CUDA Stream 和 Event - 第6节:NVVP工具演示》
15. CUDA optimization
15.1 CUDA编程优化目标
- 性能优化
- 读取优化:数据的重复读取越少越好
- 显存优化:显存占用越少越好
15.2 起始的问题:判断当前的算子是存储密集型还是计算密集型?
引用 Fedor Pikus 在《CppCon 2018: Fedor Pikus “Design for Performance”》上讲到的问题:
Fedor Pikus: Is it memory-bound or compute-bound?
15.3 数组下标优化:int64 -> int32
请参考博文《3. 尽量使用int32表示下标 | 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化?》
15.4 条件判断优化:[[likely]] / [[unlikely]] [Doc]
15.5 Kernel合并
理论依据:
Kernel合并可以减少访存的次数,如图所示,
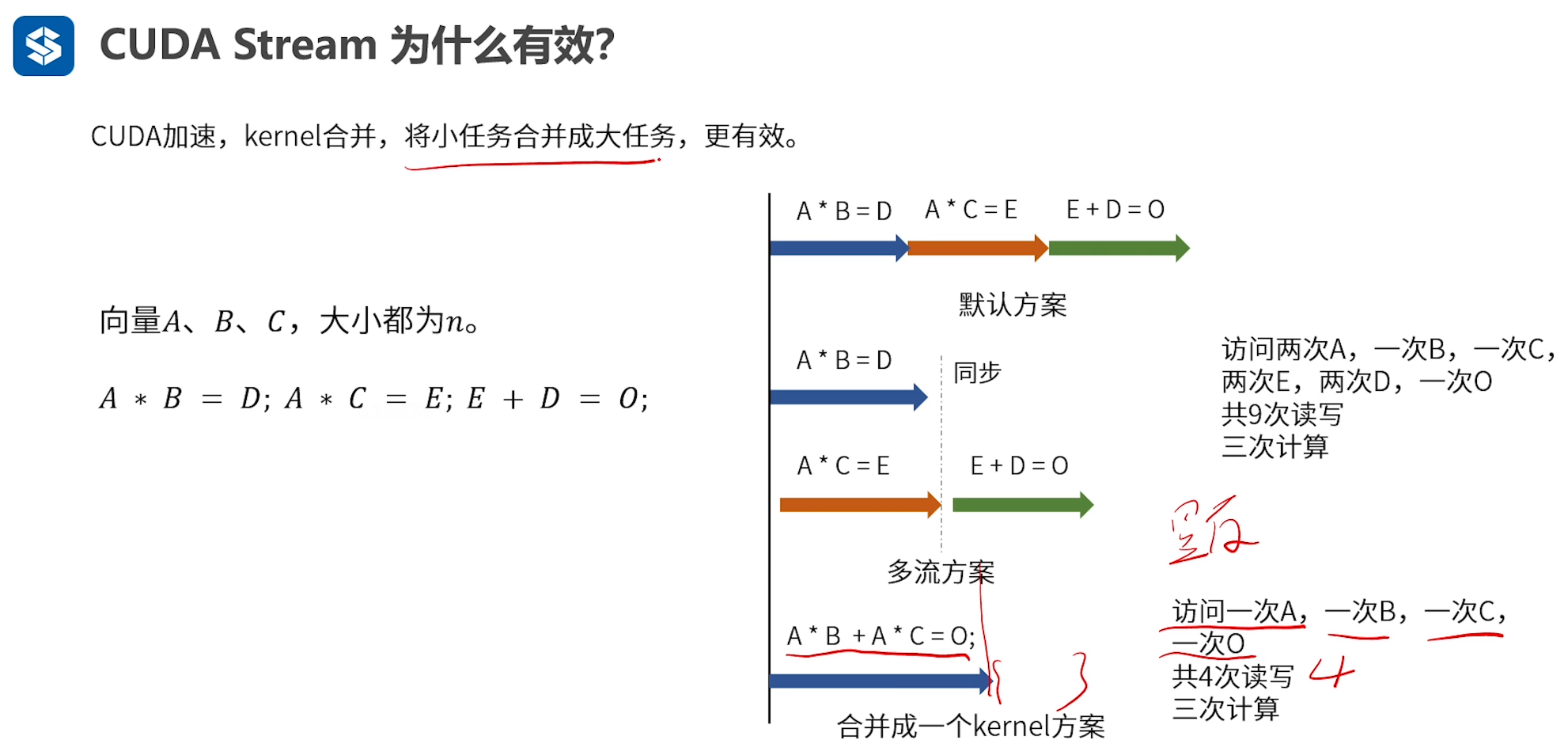
15.6 多Stream并行优化
多Stream并行优化的案例也是存在的,OneFlow中就使用过多个Stream来优化MLP的梯度计算:
oneflow/user/kernels/cublas_fused_mlp_grad_kernel.cu
15.7 NVCC也有优化标志
常用的优化标志包括-O || -O2 || -O3。
15. Precision alignment
对于float,精度对齐在1e-5左右;
16. 常见编程范式
16.1 使用宏定义函数进行 cudaError_t 检查
示例代码(rbgirshick/py-faster-rcnn):
#define CUDA_CHECK(condition) \
/* Code block avoids redefinition of cudaError_t error */ \
do { \
cudaError_t error = condition; \
if (error != cudaSuccess) { \
std::cout << cudaGetErrorString(error) << std::endl; \
} \
} while (0)
17. 图像处理:npp
NPP: Nvidia 2D image and signal Performance Primitives
NVIDIA NPP is a library of functions for performing CUDA accelerated 2D image and signal processing.














 1882
1882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









