






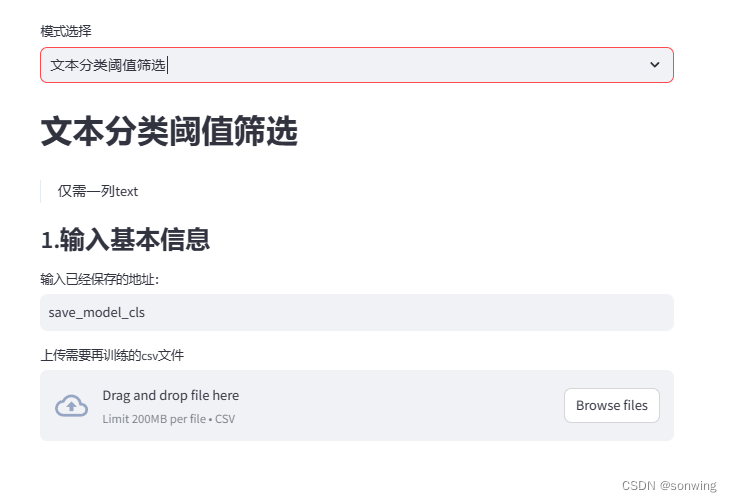
文本分类的训练、推理
基于transformers包,huggingface的社区,streamlit的界面。简单记录当前的内容。
文本分类训练的说明
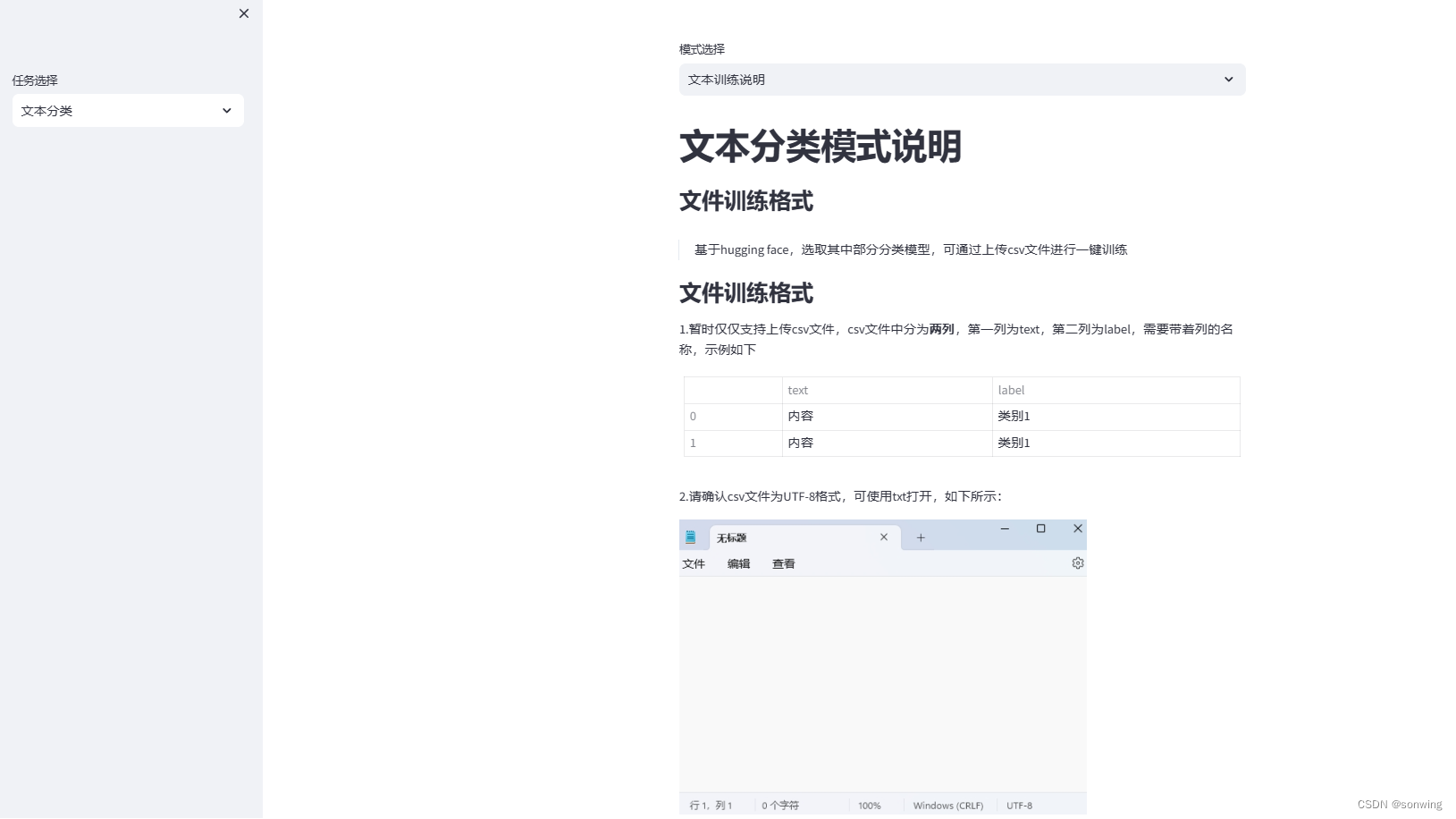
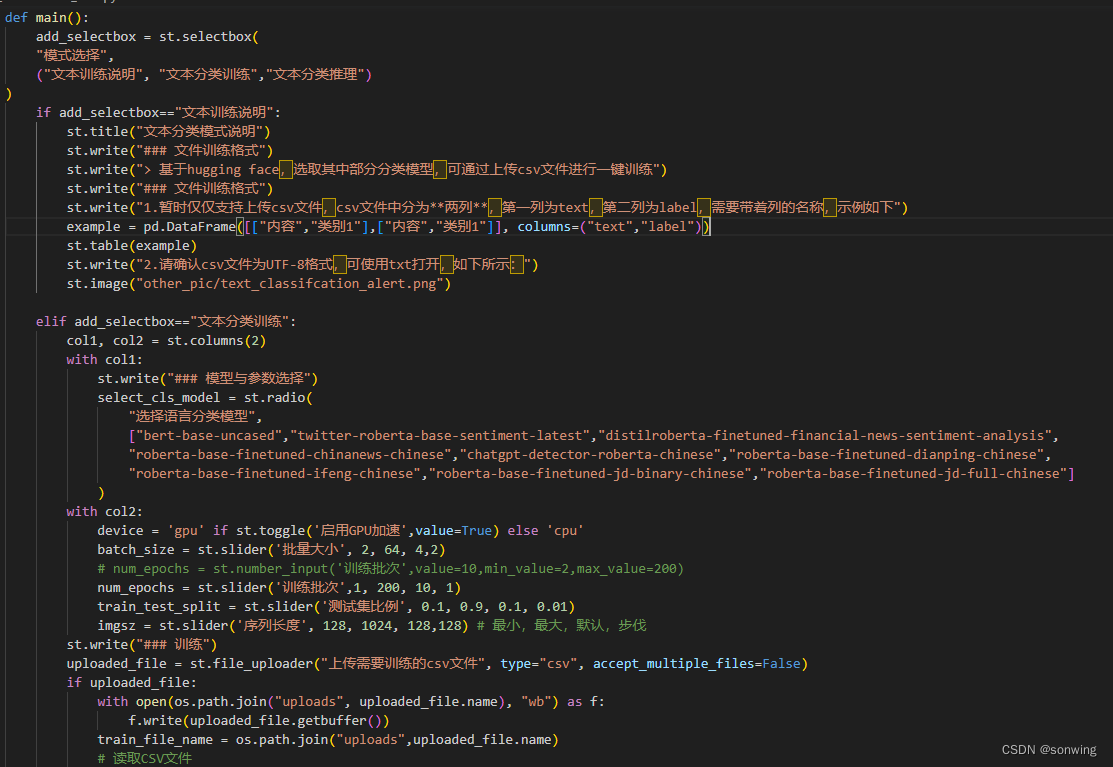
文本分类训练
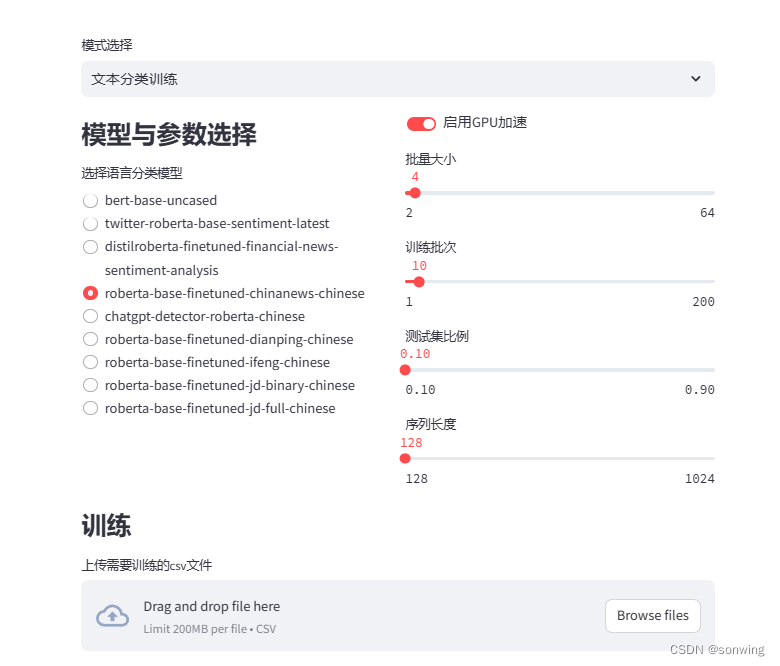
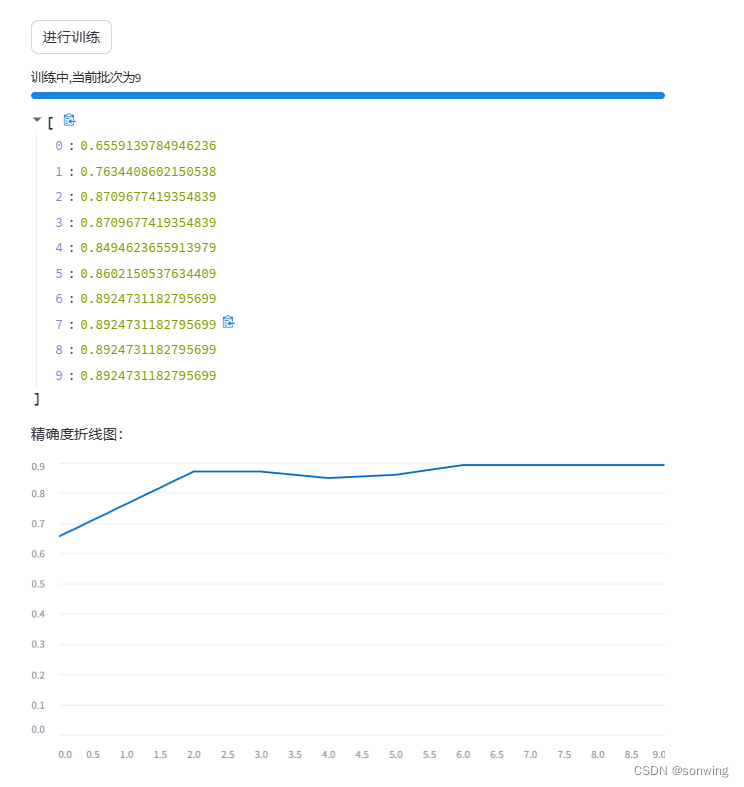
训练标签与ID的对应关系和训练进度条的展示,保存最佳模型,用于后续的推理。
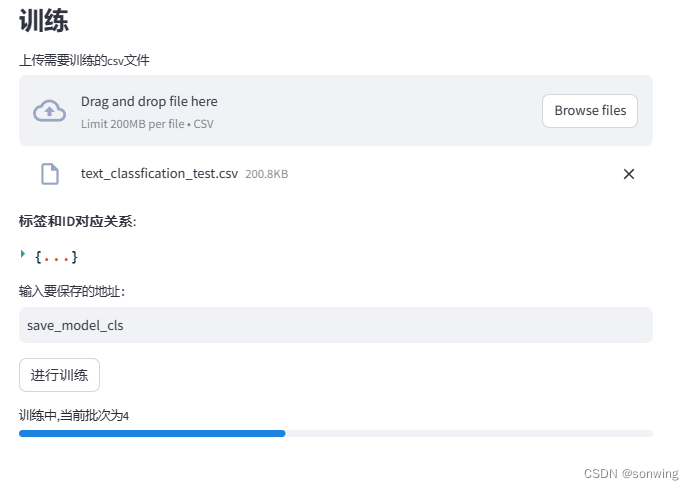
精度折线图和精度
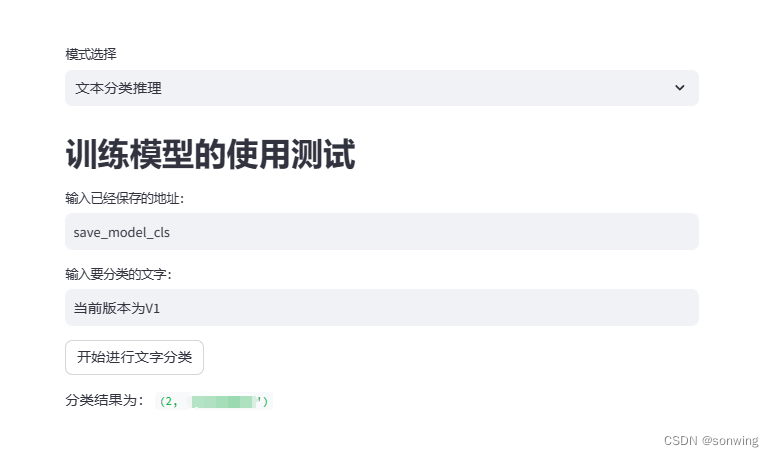
文本分类推理
输出分类结果类别以及名称
PLAN迭代训练
- 使用小量数据训练模型,得到初始模型A
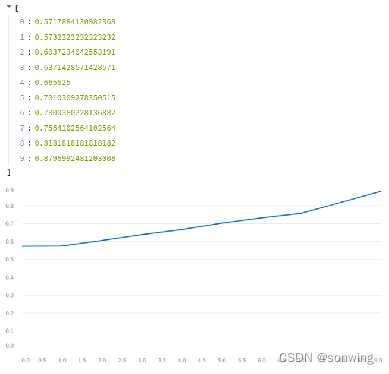
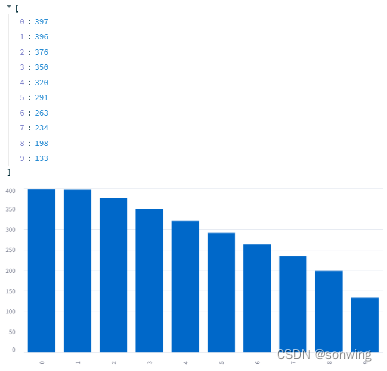
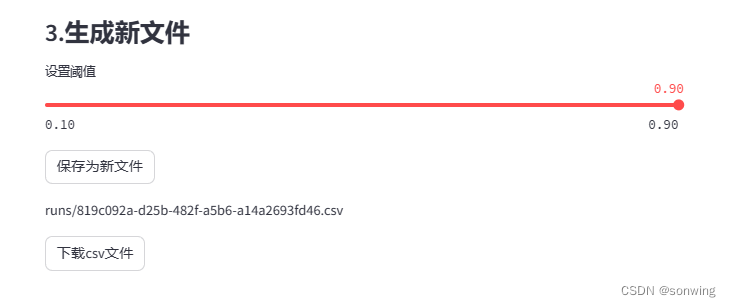
- 使用模型A,对数据进行标注,标注时使用阈值筛选分数较大的部分,这部分简单做了个实验,简单证明了一下可行性。阈值从0到0.9的效果,一个是分数一个是数量。
- 对新数据进行筛选与数据标注,使用模型A,设置阈值进行标注,整体基于前面保存的模型地址。
- 重新对模型A训练,方式待定(得学一下半监督学习了),得到模型B。
- 使用模型B再反复进行以上的操作















 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









