







对于《Attention is all you need》这篇文章中提到的transformer模型,自己最初阅读的时候并不是很理解,于是决定从头开始,一点一点梳理transformer模型的由来。整个文章计划分成三个部分,第一部分,也就是本文,将重点介绍一下NLP方面对于seq2seq的基本发展。第二部分,将讲解attention机制的各个细节。最后一部分,将介绍transformer模型的具体结构。
1.基本RNN结构
对于自然语言处理中的问题,相比较传统的词袋模型和普通的前馈神经网络结构,RNN结构可以更好的考虑到句子中词的先后顺序所带来的不同影响。
RNN的基本结构如下图所示。
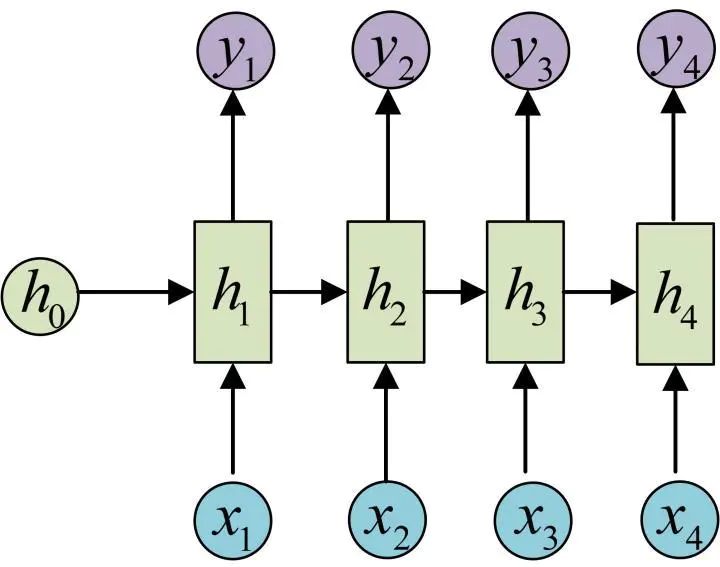
整个RNN分成3个部分,输入,输出,和中间的隐状态(hidden state)。隐状态与传统神经网络最大的不同是会接受上一时刻的隐状态。
对于h1而言,![]()
这里的U,W,b分别是对应的参数。f是激活函数。
h2的计算公式和h1相同,只不过对应的h和x要做改变。
可以看出,要计算当前时刻的隐状态ht,需要2个输入。一个是当前的输入xt,另外一个就是上一时刻的隐状态
这里有一个地方需要注意,在RNN中,U,W,b这三个参数在不同的隐状态中也是相同的。也就是说参数是共享的。
计算得到隐状态后,要计算当前时刻的输出。![]()
注意这里的参数V和c也是共享的。
以上就是最基本的RNN模型,这个模型中,输入的个数严格的等于输出。是标准的N对N。下面将介绍几种RNN的常见变种。
2.RNN变种
(1) N vs 1
相比于以前每一个输入对应一个输出,当前模型只在最后的一个时刻输出。
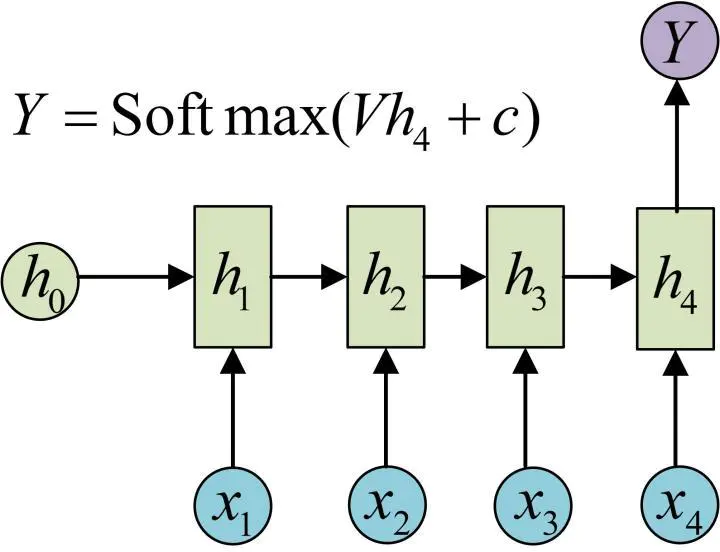
最常见的使用场景就是做文本分类,将最后一个时刻的输出作为类别的判断。
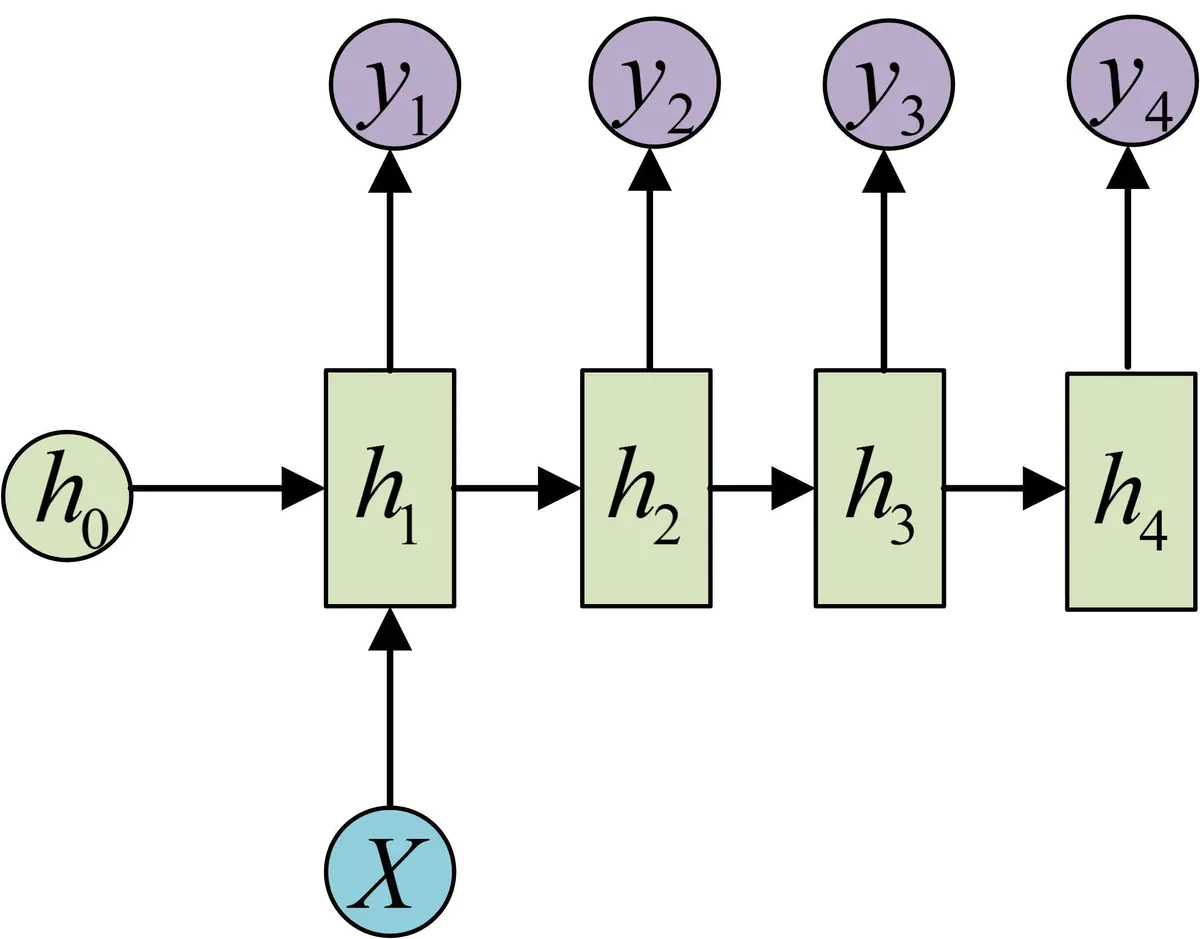
(2) 1 vs N
与上一个模型相反,这次是输入只有一个。
一种情况是把输入作为最初阶段的输入:
另一种情况是在每个阶段,都把X作为输入:
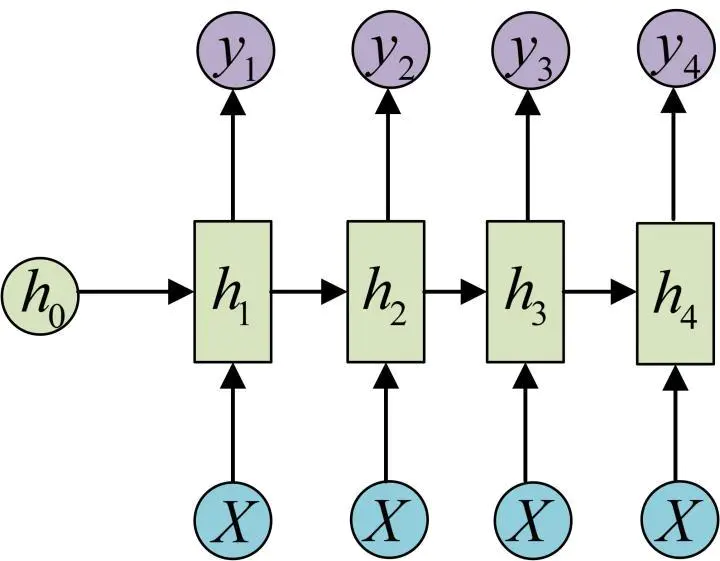
这种结构可以应用的场景有: 图像生成文字等
(3) N vs M
接下来就要引出本文的核心结构了,当RNN的输入和输出是N vs M这种结构时,这种结构也被称作Encoder-Decoder 模型,也可以被称作 seq2seq模型。
Encoder-Decoder 模型
对于Encoder-decoder 模型,最抽象的一种表示如下图所示
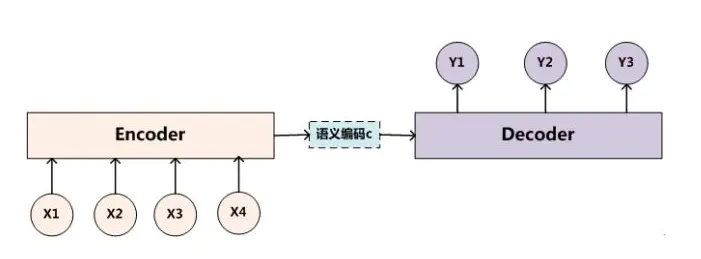
Encoder网络负责将输入进行编码,得到语义的编码C。 Decoder网络负责根据得到的编码C,进行解码,解码后输出结果。一个很常见的encoder-decoder的例子就是机器翻译,例如中译英,讲中文作为输入放进encode网络,再将其解码后输出英文。
对于作为输入的中文,我们把它看成给定的输入句子,Source。经过解码后输出的英文,就是目标句子Target。整个流程可以总结为
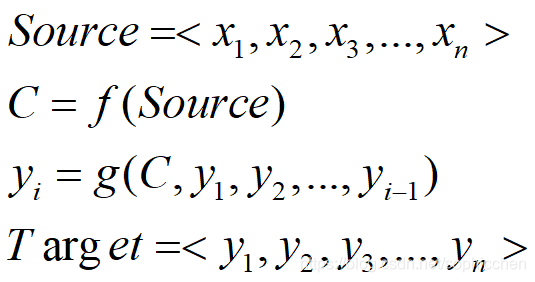
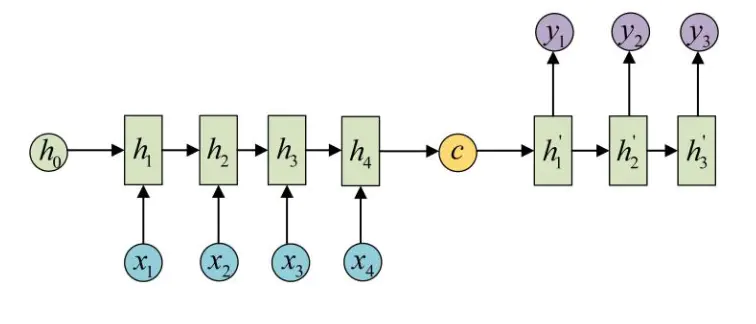
以上的流程就是基本的encoder-decoder模型的流程,把编码后的C作为最初的输入给decoder网络。decoder网络会根据C和上一个时间点的输出,获得当前时间点的输出。直到最后输出终止符的时候,停止输出。
对于编码后的C,有时也会把C作为输入,输入给每一个y。对于C的不同使用,见下图示例,但是通常都是把C当做初始状态h0。
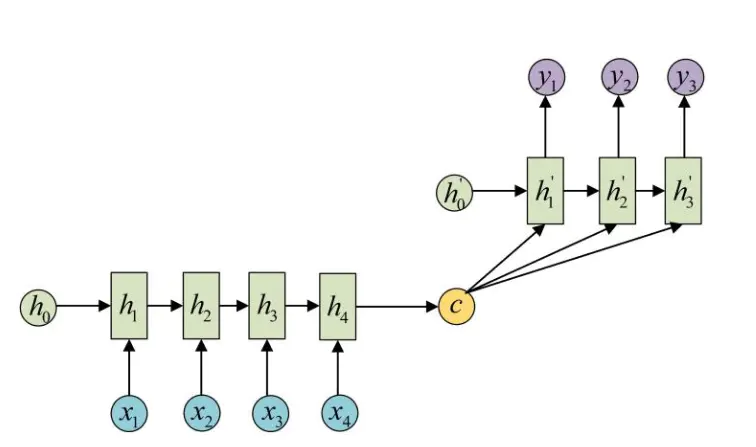
当然,对于C的计算,也有很多种方法。最简单的方法就是把最后一个时刻的隐状态赋值给C。也就是![]()
,也可以对最后一步的隐状态变化后再赋值,或者可以对全部的隐状态都做一个变换。
以上就是最常见的Encoder-Decode网络的结构,那么缺点也很明显。首先,对于输入的句子没有区分,在decoder输出时,会把整个输入的句子平等看待。而以人翻译句子的习惯来看,这是不正常的。 第二个问题,如果仅仅把C作为初始状态进行输入,随着RNN网络的推进,传到后面时前面的信息已经非常少了。对于以上情况的改进,就是下一篇文章要提出的attention机制。
参考文献
[1]完全图解RNN、RNN变体、Seq2Seq、Attention机制
[2]深度学习中的注意力模型(2017版)
[3]从Encoder到Decoder实现Seq2Seq模型

















 3199
3199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









