







目录
三. Depthwise Separable Convolution
2. Model Shrinking Hyperparameters
4.2 Large Scale Geolocalizaton
一. 引言
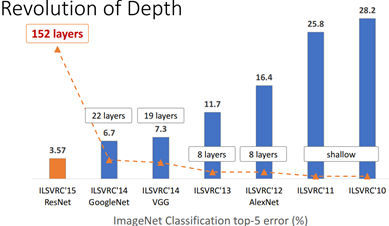
卷积神经网络(CNN)已经普遍应用在计算机视觉领域,并且已经取得了不错的效果。图1为近几年来CNN在ImageNet竞赛的表现,可以看到为了追求分类准确度,模型深度越来越深,模型复杂度也越来越高,如深度残差网络(ResNet)其层数已经多达152层。
然而,在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型是难以被应用的。首先是模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,或者说响应速度要快,想象一下自动驾驶汽车的行人检测系统如果速度很慢会发生什么可怕的事情。所以,研究小而高效的CNN模型在这些场景至关重要,至少目前是这样,尽管未来硬件也会越来越快。目前的研究总结来看分为两个方向:一是对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。本文的主角MobileNet属于后者,其是Google最近提出的一种小巧而高效的CNN模型,介绍了两个简单的全局超参数,其在accuracy和latency之间做了折中。这些超参数允许我们依据约束条件选择合适大小的模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。论文测试在多个参数量下做了广泛的实验,并在ImageNet分类任务上与其他先进模型做了对比,显示了强大的性能。论文验证了模型在其他领域(对象检测,人脸识别,大规模地理定位等)使用的有效性。

二. 相关研究
现阶段,在建立小型高效的神经网络工作中,通常可分为两类工作:
1.压缩预训练模型。获得小型网络的一个办法是减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;还有一种训练小型网络的方法叫蒸馏(distillation ),使用大型网络指导小型网络,这是对论文的方法做了一个补充,后续有介绍补充。
2.直接训练小型模型。 例如Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到Inception V3 networks;Squeezenet 使用一个bottleneck用于构建小型网络。
本文提出的MobileNet网络架构属于上述第二种,允许模型开发人员专门选择与其资源限制(延迟、大小)匹配的小型模型,MobileNets主要注重于优化延迟同时考虑小型网络,从深度可分离卷积的角度重新构建模型。
三. Depthwise Separable Convolution
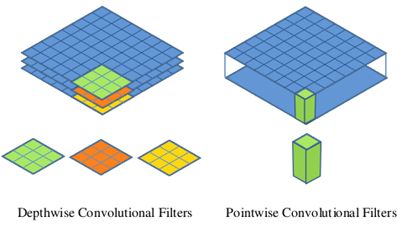
MobileNet的基本单元是深度可分离卷积(depthwise separable convolution),其实这种结构之前已经被使用在Inception模型中。深度可分离卷积其实是一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution和pointwise convolution,如图2所示。Depthwise Convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。图3中更清晰地展示了两种操作。对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。

这里简单分析一下depthwise separable convolution在计算量上与标准卷积的差别。假定输入特征图F大小是,采用标准的卷积K为
(如图2(a)所示),输出特征图G大小是
,其中
是特征图的width和height,而M和N指的是通道数(channels or depth)。
标准卷积的卷积计算公式为:
输入的通道数为M,输出的通道数为N。其计算量将是:
可将标准卷积拆分为深度卷积和逐点卷积:
- 深度卷积负责滤波作用,尺寸为
如图2(b)所示。输出特征为
- 逐点卷积负责转换通道,尺寸为
如图2(c)所示。得到最终输出为
深度卷积的卷积公式为
其中,是深度卷积,卷积核为
,
个卷积核应用在F中第
个通道上,产生
上第
个通道输出。
对于depthwise convolution其计算量为: ,pointwise convolution计算量是:
,所以depthwise separable convolution总计算量是:
可以比较depthwise separable convolution和标准卷积如下:
一般情况下N比较大,那么如果采用3x3卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。其实,后面会有对比,参数量也会减少很多。
1. 深度分类卷积示例
输入图片的大小为(6,6,3),原卷积操作是用(4,4,3,5)的卷积(4 × 4是卷积核大小,3是卷积核通道数,5个卷积核数量),stride=1,无padding。输出的特征尺寸为 ,即输出的特征映射为(3,3,5)
将标准卷积中选取序号为n的卷积核,大小为(4,4,3),标准卷积过程示意图如下(注意省略了偏置单元):
黑色的输入为(6,6,3)与第n个卷积核对应,每个通道对应每个卷积核通道卷积得到输出,最终输出为2+0+1=3。(这是常见的卷积操作,注意这里卷积核要和输入的通道数相同,即图中表示的3个通道~)
对于深度分离卷积,把标准卷积(4,4,3,5)分解为:
- 深度卷积部分:大小为(4,4,1,3),作用在输入的每个通道上,输出特征映射为(3,3,3)(3,3,3)
- 逐点卷积部分:大小为(1,1,3,5),作用在深度卷积的输出特征映射上,得到最终输出为(3,3,5)
例中深度卷积卷积过程示意图如下:
输入有3个通道,对应着有3个大小为(4,4,1)的深度卷积核,卷积结果共有3个大小为(3,3,1),我们按顺序将这卷积按通道排列得到输出卷积结果(3,3,3)。
相比之下计算量减少了:
4×4×3×5转为了4×4×1×3+1×1×3×5,即参数量减少了
,即
MobileNet使用可分离卷积减少了8到9倍的计算量,只损失了一点准确度。
四. MobileNet网络结构
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如图4右边所示。标准卷积和MobileNet中使用的深度分离卷积结构对比如下:

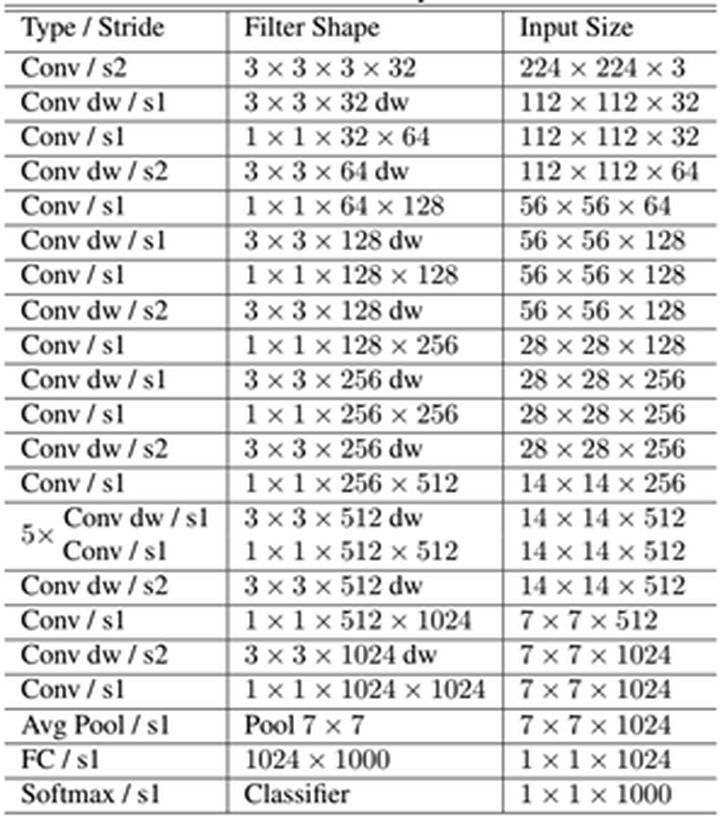
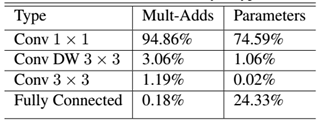
MobileNet的具体网络结构如表1所示(dw表示深度分离卷积)。首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。如果单独计算depthwiseconvolution和pointwise convolution,整个网络有28层(这里Avg Pool和Softmax不计算在内)。我们还可以分析整个网络的参数和计算量分布,如表2所示。可以看到整个计算量基本集中在1x1卷积上。如果你熟悉卷积底层实现的话,你应该知道卷积一般通过一种im2col方式实现,其需要内存重组,但是当卷积核为1x1时,其实就不需要这种操作了,底层可以有更快的实现。对于参数也主要集中在1x1卷积,除此之外还有就是全连接层占了一部分参数。我们的模型几乎将所有的密集运算放到1 × 1 1×11×1卷积上,这可以使用general matrix multiply (GEMM) functions优化。在MobileNet中有95%的时间花费在1 × 1 1×11×1卷积上,这部分也占了75%的参数。
在TensorFlow中使用RMSprop对MobileNet做训练,使用类似InceptionV3 的异步梯度下降。与训练大型模型不同的是,我们较少使用正则和数据增强技术,因为小模型不易陷入过拟合;没有使用side heads or label smoothing,我们发现在深度卷积核上放入很少的L2正则或不设置权重衰减的很重要,因为这部分参数很少。
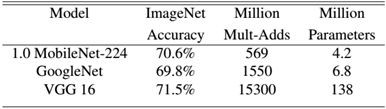
MobileNet到底效果如何,这里与GoogleNet和VGG16做了对比,如表3所示。相比VGG16,MobileNet的准确度稍微下降,但是优于GoogleNet。然而,从计算量和参数量上MobileNet具有绝对的优势。
五. MobileNet瘦身
前面说的MobileNet的基准模型,但是有时候你需要更小的模型,那么就要对MobileNet瘦身了。这里引入了两个超参数:width multiplier(宽度因子,用于控制输入和输出的通道数)和resolution multiplier。第一个参数width multiplier主要是按比例减少通道数,该参数记为
,其取值范围为(0,1],通常取1,0.75,0.5和0.25,那么输入与输出通道数将变成
和
,对于depthwise separable convolution,其计算量变为:
计算量减少了:
宽度因子将计算量和参数降低了约倍,可很方便的控制模型大小.
因为主要计算量在后一项,所以width multiplier可以按照比例降低计算量,其是参数量也会下降。
第二个参数resolution multiplier(分辨率因子)主要是按比例降低特征图的大小,即用分辨率因子控制输入的分辨率,记为。比如原来输入特征图是224x224,可以减少为192x192,加上resolution multiplier,depthwise separable convolution的计算量为:
可设置ρ ∈ ( 0 , 1 ],通常设置输入分辨率为224,192,160和128。
计算量减少了:
分辨率因子将计算量和参数降低了约倍,可很方便的控制模型大小.
要说明的是,resolution multiplier仅仅影响计算量,但是不改变参数量。引入两个参数肯定会降低MobileNet的性能,具体实验分析可以见paper,总结来看是在accuracy和computation,以及accuracy和model size之间做折中。
下面的示例展现了宽度因子和分辨率因子对模型的影响:

第一行是使用标准卷积的参数量和Mult-Adds;第二行将标准卷积改为深度分类卷积,参数量降低到约为原本的1/10,Mult-Adds降低约为原本的1/9。使用α 和 ρ 参数可以再将参数降低一半,Mult-Adds再成倍下降。
六. 实验
实验部分主要研究以下部分: 深度卷积的影响;宽度因子的影响;两个超参数的权衡;与其他模型对比。
1. 模型选择
使用深度分类卷积的MobileNet与使用标准卷积的MobileNet之间对比:

在精度上损失了1%,但是的计算量和参数量上降低了一个数量级。
为了进一步缩小模型,可将MobileNet中(见表1)的5层14 × 14 × 512 14×14×51214×14×512的深度可分离卷积去除。
实验结果对比:
可以看到在类似的参数量和计算量下,精度衰减了3%。(中间的深度卷积用于过滤作用,参数量少,冗余度相比于大量的逐点卷积应该是少很多的~)
2. Model Shrinking Hyperparameters
2.1 单参数验证
表6显示宽度因子对模型参数量、计算量精度的影响,表7显示分辨率因子对模型参数量、计算量精度的影响:

使用过程要权衡参数对模型性能和大小的影响。
2.2 交叉验证计算量对精度影响
下面图4显示了16个交叉的模型在ImageNet上的表现,宽度因子取值为α∈{1,0.75,0.5,0.25},分辨率取值为{224,192,160,128}。

当模型越来越小时,精度可近似看成对数跳跃形式的。
2.3 交叉验证参数量对精度影响
图5显示了16个交叉的模型在ImageNet上的表现,宽度因子取值为α∈{1,0.75,0.5,0.25},分辨率取值为{224,192,160,128}。

3. 与其他先进模型相比
表8将完整的MobileNet与原始的GoogleNet和VGG16对比,MobileNet与VGG16有相似的精度,参数量和计算量减少了2个数量级。

表9是MobileNet的宽度因子α=0.5和分辨率设置为160×160的缩小模型与其他模型对比结果,相比于老大哥AlexNet在计算量和参数量上都降低一个数量级,对比同为小型网络的Squeezenet,计算量少了2个数量级,在参数量类似的情况下,精度高了3%。
4.其他应用场景性能
4.1 Fine Grained Recognition
在Stanford Dogs dataset的表现如下:

MobileNet在计算量和参数量降低一个数量级的同时几乎保持相同的精度。
4.2 Large Scale Geolocalizaton
PlaNet是做大规模地理分类任务,我们使用MobileNet的框架重新设计了PlaNet,对比如下:

基于Inception V3架构的PlaNet有5200万参数和574亿的mult-adds,而基于MobileNet的PlaNet只有1300万参数(300个是主体参数,1000万是最后分类层参数)和58万的mult-adds,相比之下,只是性能稍微受损,但还是比原Im2GPS效果好多了。
4.3 Face Attributes
MobileNet的框架技术可用于压缩大型模型,在Face Attributes任务中,我们验证了MobileNet的蒸馏(distillation )技术的关系,蒸馏的核心是让小模型去模拟大模型,而不是直接逼近Ground Label:

将蒸馏技术的可扩展性和MobileNet技术的精简性结合到一起,最终系统不仅不需要正则技术(例如权重衰减和退火等),而且表现出更强的性能。
4.4 Object Detection
基于MobileNet改进的检测模型对比如下:

可视化结果:

4.5 Face Embeddings
FaceNet是现阶段最先进的人脸识别模型,基于MobileNet和蒸馏技术训练出结果如下:

七. MobileNet的TensorFlow实现
TensorFlow的nn库有depthwise convolution算子tf.nn.depthwise_conv2d,所以MobileNet很容易在TensorFlow上实现:
class MobileNet(object):
def __init__(self, inputs, num_classes=1000, is_training=True,
width_multiplier=1, scope="MobileNet"):
"""
The implement of MobileNet(ref:https://arxiv.org/abs/1704.04861)
:param inputs: 4-D Tensor of [batch_size, height, width, channels]
:param num_classes: number of classes
:param is_training: Boolean, whether or not the model is training
:param width_multiplier: float, controls the size of model
:param scope: Optional scope for variables
"""
self.inputs = inputs
self.num_classes = num_classes
self.is_training = is_training
self.width_multiplier = width_multiplier
# construct model
with tf.variable_scope(scope):
# conv1
net = conv2d(inputs, "conv_1", round(32 * width_multiplier), filter_size=3,
strides=2) # ->[N, 112, 112, 32]
net = tf.nn.relu(bacthnorm(net, "conv_1/bn", is_training=self.is_training))
net = self._depthwise_separable_conv2d(net, 64, self.width_multiplier,
"ds_conv_2") # ->[N, 112, 112, 64]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_3", downsample=True) # ->[N, 56, 56, 128]
net = self._depthwise_separable_conv2d(net, 128, self.width_multiplier,
"ds_conv_4") # ->[N, 56, 56, 128]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_5", downsample=True) # ->[N, 28, 28, 256]
net = self._depthwise_separable_conv2d(net, 256, self.width_multiplier,
"ds_conv_6") # ->[N, 28, 28, 256]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_7", downsample=True) # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_8") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_9") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_10") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_11") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 512, self.width_multiplier,
"ds_conv_12") # ->[N, 14, 14, 512]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_13", downsample=True) # ->[N, 7, 7, 1024]
net = self._depthwise_separable_conv2d(net, 1024, self.width_multiplier,
"ds_conv_14") # ->[N, 7, 7, 1024]
net = avg_pool(net, 7, "avg_pool_15")
net = tf.squeeze(net, [1, 2], name="SpatialSqueeze")
self.logits = fc(net, self.num_classes, "fc_16")
self.predictions = tf.nn.softmax(self.logits)
def _depthwise_separable_conv2d(self, inputs, num_filters, width_multiplier,
scope, downsample=False):
"""depthwise separable convolution 2D function"""
num_filters = round(num_filters * width_multiplier)
strides = 2 if downsample else 1
with tf.variable_scope(scope):
# depthwise conv2d
dw_conv = depthwise_conv2d(inputs, "depthwise_conv", strides=strides)
# batchnorm
bn = bacthnorm(dw_conv, "dw_bn", is_training=self.is_training)
# relu
relu = tf.nn.relu(bn)
# pointwise conv2d (1x1)
pw_conv = conv2d(relu, "pointwise_conv", num_filters)
# bn
bn = bacthnorm(pw_conv, "pw_bn", is_training=self.is_training)
return tf.nn.relu(bn)完整实现可以参见GitHub。
八. 总结
本文简单介绍了Google提出的一种基于深度可分离卷积的移动端模型MobileNet,其核心是采用了可分解的depthwise separable convolution,包含两个超参数用于快速调节模型适配到特定环境。其不仅可以降低模型计算复杂度,而且可以大大降低模型大小。实验部分将MobileNet与许多先进模型做对比,展现出MobileNet的在尺寸、计算量、速度上的优越性。在真实的移动端应用场景,像MobileNet这样类似的网络将是持续研究的重点。后面我们会介绍其他的移动端CNN模型。















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









