







GraphMAE: Self-Supervised Masked Graph Autoencoders
前言
当前的自监督学习领域主要分为对比式自监督学习以及生成式自监督学习,这篇文章主要聚焦于生成式对比学习。事实上后者在图领域的进展是远远不如前者的,但是在cv,nlp领域却是以生成式自监督学习为主,所以作者想要重振生成式学习的荣光。
生成式自监督学习又主要分为:自回归以及自动编码,目前是后者用的比较多。自动编码技术的主要目的就是在给定上下文的基础上重建输入的特征,图领域的自动编码器就叫做GAE。之前的一些操作:
- 利用均方误差来作为损失函数
- 大部分还是会对图的结构/特征做扰动,或者结合两者
- 预测节点的度数以及邻居特征分布
作者认为之前的GAE都存在如下问题:
- 结构信息被过分强调,而不是特征信息
- 缺少对特征信息的干扰,这一点在cv,nlp领域已经得到了应用
- 用均方误差来作为损失函数可能并不是很好,因为当节点维度比较高但是大部分维度差距基本没有的时候,其余维度的差距会被拉小,导致整体的loss是偏小的(这可能也是之前以特征重建为目标的模型效果不好的原因之一)
- 之前的GAE的decoder大部分采用mlp,但是作者认为这种模型的表现力不强,不如gnn
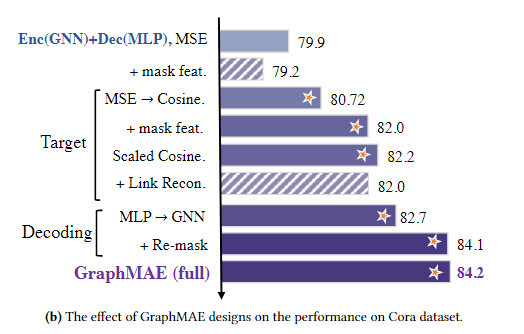
以上几点可以在图中看出来
不难看出加了Link reconstruction之后,性能反而还有了一定的下降,而重建特征之后反而会有一定的上升,所以作者决定采用特征重建。
模型结构
以下是GraphMAE的结构
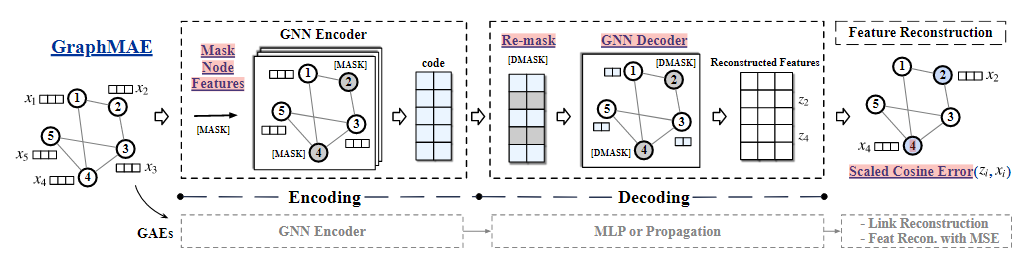
首先是encoding结构,在autoencoder的基础上,主要的改动有:
是基于特征而非结构的重建,然后引入了mask操作。mask之后用gnn来进行特征聚合,得到节点的embedding。作者认为对输入进行破坏是必要的,否则有可能会学习到一个恒等映射,相当于什么都没有学习。所以需要对特征进行mask操作,具体表现为将某些节点的特征用一个无意义的向量进行替代。
然后是decoding结构:
加入了remask操作,对之前的mask集合内的点再做一次mask操作。因为这个模型是建立在局部同质性前提上的,所以信息其实冗余度会比较大。冗余度大的话,其实对特征重建来说难度会低一点,那么所能学习到的参数就会少一点,这里rmask,其实就是提高了重建的难度,进而提高学习质量。这样做可以进一步压缩信息,提高表现力。
decoder模型没有采用之前所说的mlp,而是采用了gnn
最后是特征重建过程
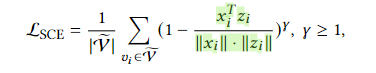
这里的改进主要是采用了新的误差函数。原本的MSE的缺点已经讲过了,那么采用cos来衡量向量的夹角的话会是一个比较合理的方法。这里作者在余弦函数的基础上又加了一点改进。相比于那些本身夹角就已经比较小的向量来说,其实我们跟应该去关注那些夹角比较大的向量的修正,所以这里加了一个参数 γ \gamma γ用来进行缩放。其实不难发现,当夹角大于90度的时候,1-cos>1,此时随着 γ \gamma γ变大,整体的值会变大,权重也会变大,那么这种hard样本就会受到更多的关注。
实验
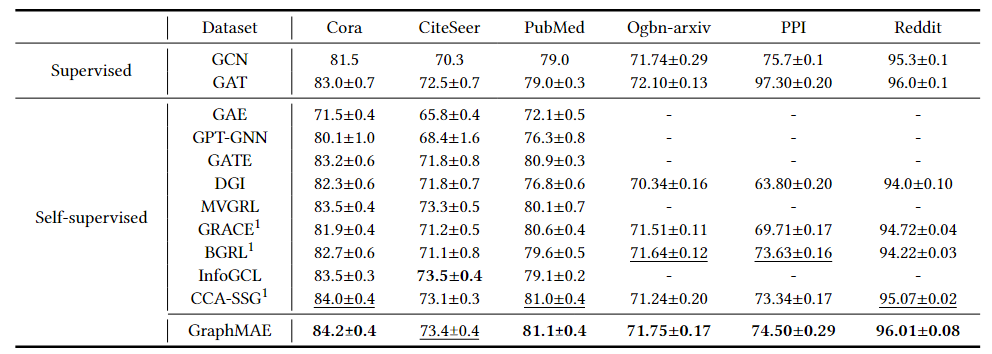
节点分类
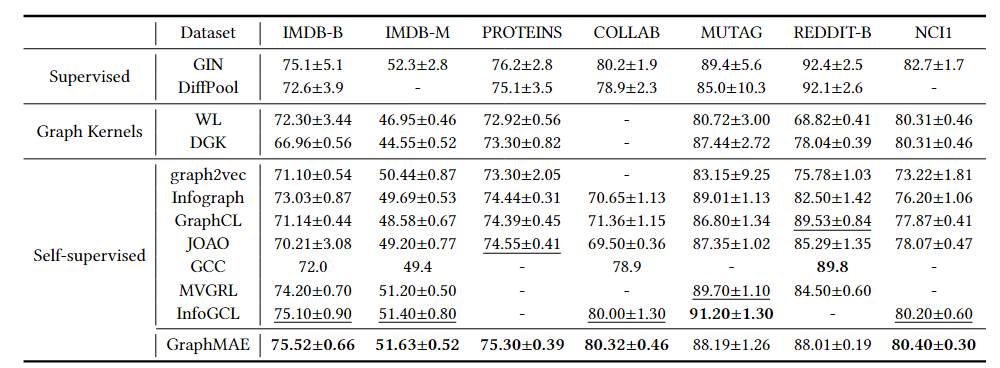
图分类
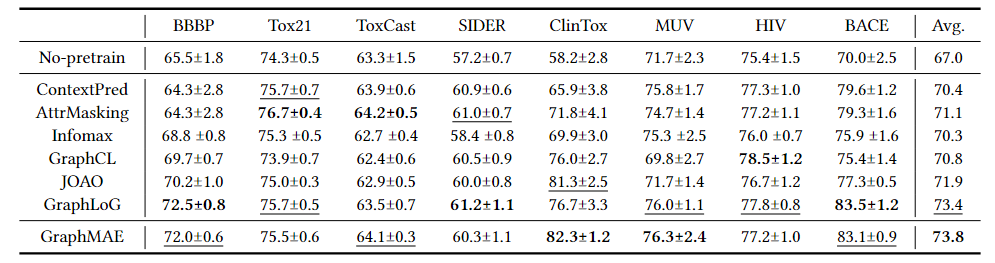
迁移学习
消融实验
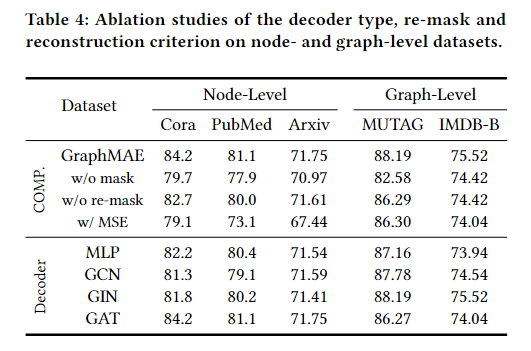
其实可以看出来,缩放余弦误差的改进是比较大的,然后是mask,再是remask
作者说gnn的表现力比mlp要好,但其实gnn里面只有gat是明显优于mlp的,所以说gnn好,不如直接说gat好,这里说mlp表现力较差其实也是立不住脚的,也缺乏足够的理论依据。















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









