







最佳阅读体验
之前就对sgd的看似无脑的贪心策略感到十分新奇,为什么每次随机用一个子集的梯度来更新就可以近似整体的梯度? 正好最近重新实现了一遍sgd,就顺便补一下它的理论证明。
准备工作
不妨假设我们模型的损失函数为
L
(
x
,
θ
)
L(x,\theta)
L(x,θ),其中
x
x
x是训练数据,
θ
∈
R
d
\theta\in R^d
θ∈Rd是模型参数,一般来说我们优化的目标是找到最优的
θ
∗
\theta^*
θ∗使得
L
(
x
,
θ
∗
)
L(x,\theta^*)
L(x,θ∗)最小,也就是
θ
∗
=
a
r
g
m
i
n
θ
∈
R
d
L
(
x
,
θ
)
\theta^* = argmin_{\theta\in R^d} L(x,\theta)
θ∗=argminθ∈RdL(x,θ)
随机梯度下降(SGD)的策略是每次随机取数据
x
x
x的一个子集,我们不妨将第
t
t
t次取出的子集记为
x
t
x^t
xt,那么更新方式为
θ
t
+
1
=
θ
t
−
η
t
g
(
x
t
,
θ
t
)
\theta^{t+1} = \theta^t - \eta^tg(x^t,\theta^t)
θt+1=θt−ηtg(xt,θt)
其中
η
t
\eta^t
ηt表示第
t
t
t次更新的学习率,
g
(
x
t
,
θ
t
)
=
∇
θ
L
(
x
t
,
θ
)
g(x^t,\theta^t) = \nabla_\theta L(x^t,\theta)
g(xt,θt)=∇θL(xt,θ)表示损失函数关于参数
θ
\theta
θ的梯度。
我们当然可以直接写出
θ
t
\theta^t
θt的通项为
θ
t
=
θ
1
−
∑
s
=
1
t
−
1
η
s
g
(
x
s
,
θ
s
)
\theta^t = \theta^1-\sum_{s=1}^{t-1} \eta^sg(x^s,\theta^s)
θt=θ1−s=1∑t−1ηsg(xs,θs)
当然这么看的话似乎很难说明参数
θ
\theta
θ会收敛,更别说收敛到
θ
∗
\theta^*
θ∗了。所以我们尝试制定一个评价指标。
那么我们要如何评价这个策略?一个比较合理的目标是最小化
L
(
T
)
=
1
T
∑
t
=
1
T
L
(
x
t
,
θ
t
)
L(T) = \frac{1}{T}\sum_{t=1}^{T}L(x^t,\theta^t)
L(T)=T1t=1∑TL(xt,θt)
其中
T
T
T表示我们的迭代总轮数
又注意到
L
(
T
)
L(T)
L(T)的最小值我们可以表示为
L
(
T
)
′
=
1
T
∑
t
=
1
T
L
(
x
t
,
θ
∗
)
L(T)' = \frac{1}{T}\sum_{t=1}^{T}L(x^t,\theta^*)
L(T)′=T1∑t=1TL(xt,θ∗)
那么我们的评价指标可以选择为
1
T
∑
t
=
1
T
L
(
x
t
,
θ
t
)
−
1
T
∑
t
=
1
T
L
(
x
t
,
θ
∗
)
=
1
T
R
(
T
)
(
1
)
\frac{1}{T}\sum_{t=1}^{T}L(x^t,\theta^t)-\frac{1}{T}\sum_{t=1}^{T}L(x^t,\theta^*)=\frac{1}{T}R(T)\ \ \ \ \ \ (1)
T1t=1∑TL(xt,θt)−T1t=1∑TL(xt,θ∗)=T1R(T) (1)
其中
R
(
T
)
=
∑
t
=
1
T
L
(
x
t
,
θ
t
)
−
∑
t
=
1
T
L
(
x
t
,
θ
∗
)
R(T)=\sum_{t=1}^{T}L(x^t,\theta^t)-\sum_{t=1}^{T}L(x^t,\theta^*)
R(T)=t=1∑TL(xt,θt)−t=1∑TL(xt,θ∗)
被称为"regret"
当
lim
T
→
∞
1
T
R
(
T
)
=
0
\lim_{T\rightarrow \infty}\frac{1}{T}R(T)=0
T→∞limT1R(T)=0
时,我们就可以说这个策略确实是收敛的,参数
θ
→
θ
∗
\theta\rightarrow \theta^*
θ→θ∗,也就是说,它不仅收敛,而且收敛于最优参数
θ
∗
\theta^*
θ∗
证明过程
现在我们考虑对
(
1
)
(1)
(1)式的收敛性进行证明。不过在此之前,我们需要假设对于任意的
t
,
x
t
t,x^t
t,xt,损失函数
L
(
x
t
,
θ
)
L(x^t,\theta)
L(xt,θ)都是关于
θ
\theta
θ的convex函数,也就是说,
∀
θ
i
,
θ
j
\forall \theta^i,\theta^j
∀θi,θj,都有
L
(
x
t
,
θ
i
)
−
L
(
x
t
,
θ
j
)
≥
(
θ
i
−
θ
j
)
⋅
g
(
x
t
,
θ
j
)
(
2
)
L(x^t,\theta^i)-L(x^t,\theta^j)\geq (\theta^i-\theta^j)\cdot g(x^t,\theta^j)\ \ \ \ \ (2)
L(xt,θi)−L(xt,θj)≥(θi−θj)⋅g(xt,θj) (2)
其中
⋅
\cdot
⋅表示向量内积
现在我们就可以正式开始证明了!
想要证明 ( 1 ) (1) (1)式收敛于0,一个常见的办法就是为其找一个关于 T T T的上界 f ( T ) f(T) f(T),如果 f ( T ) → 0 , T → ∞ f(T)\rightarrow 0,T\rightarrow \infty f(T)→0,T→∞的话,结论就得证了。
利用
(
2
)
(2)
(2)式,我们现在就能为
R
(
T
)
R(T)
R(T)找一个上界
R
(
T
)
=
∑
t
=
1
T
L
(
x
t
,
θ
t
)
−
∑
t
=
1
T
L
(
x
t
,
θ
∗
)
=
∑
t
=
1
T
(
L
(
x
t
,
θ
t
)
−
L
(
x
t
,
θ
∗
)
)
≤
∑
t
=
1
T
(
θ
t
−
θ
∗
)
⋅
g
(
x
t
,
θ
t
)
R(T)=\sum_{t=1}^{T}L(x^t,\theta^t)-\sum_{t=1}^{T}L(x^t,\theta^*)\\ =\sum_{t=1}^{T}(L(x^t,\theta^t)-L(x^t,\theta^*))\\ \leq \sum_{t=1}^{T}(\theta^t-\theta^*)\cdot g(x^t,\theta^t)
R(T)=t=1∑TL(xt,θt)−t=1∑TL(xt,θ∗)=t=1∑T(L(xt,θt)−L(xt,θ∗))≤t=1∑T(θt−θ∗)⋅g(xt,θt)
最后一个不等号由
(
2
)
(2)
(2)式变形之后即得
为了后面方便区分内积与数乘,我们将上式重新表述如下
R
(
T
)
≤
∑
t
=
1
T
⟨
θ
t
−
θ
∗
,
g
(
x
t
,
θ
t
)
⟩
(
3
)
R(T)\leq \sum_{t=1}^{T}\left \langle \theta^t-\theta^*,g(x^t,\theta^t) \right \rangle \ \ \ \ \ (3)
R(T)≤t=1∑T⟨θt−θ∗,g(xt,θt)⟩ (3)
接下来尝试为不等式右端找到替代,这一点可以从SGD的迭代公式出发
θ
t
+
1
=
θ
t
−
η
t
g
(
x
t
,
θ
t
)
θ
t
+
1
−
θ
∗
=
θ
t
−
θ
∗
−
η
t
g
(
x
t
,
θ
t
)
∥
θ
t
+
1
−
θ
∗
∥
2
=
∥
θ
t
−
θ
∗
−
η
t
g
(
x
t
,
θ
t
)
∥
2
∥
θ
t
+
1
−
θ
∗
∥
2
=
∥
θ
t
−
θ
∗
∥
2
+
(
η
t
)
2
∥
g
(
x
t
,
θ
t
)
∥
2
−
2
η
t
⟨
θ
t
−
θ
∗
,
η
t
g
(
x
t
,
θ
t
)
⟩
\theta^{t+1} = \theta^t - \eta^tg(x^t,\theta^t)\\ \theta^{t+1}-\theta^* = \theta^t-\theta^*-\eta^tg(x^t,\theta^t)\\ \left \| \theta^{t+1}-\theta^* \right \|^2 = \left \| \theta^t-\theta^*-\eta^tg(x^t,\theta^t) \right \|^2 \\ \left \| \theta^{t+1}-\theta^* \right \|^2 = \left \| \theta^{t}-\theta^* \right \|^2 +(\eta^t)^2 \left \| g(x^t,\theta^t) \right \|^2 -2\eta^t \left \langle \theta^t-\theta^*,\eta^tg(x^t,\theta^t) \right \rangle\\
θt+1=θt−ηtg(xt,θt)θt+1−θ∗=θt−θ∗−ηtg(xt,θt)
θt+1−θ∗
2=
θt−θ∗−ηtg(xt,θt)
2
θt+1−θ∗
2=
θt−θ∗
2+(ηt)2
g(xt,θt)
2−2ηt⟨θt−θ∗,ηtg(xt,θt)⟩
从而
⟨
θ
t
−
θ
∗
,
η
t
g
(
x
t
,
θ
t
)
⟩
=
1
2
η
t
[
∥
θ
t
−
θ
∗
∥
2
−
∥
θ
t
+
1
−
θ
∗
∥
2
]
+
η
t
2
∥
g
(
x
t
,
θ
t
)
∥
2
\left \langle \theta^t-\theta^*,\eta^tg(x^t,\theta^t) \right \rangle = \frac{1}{2\eta^t} \left [ \left \| \theta^{t}-\theta^* \right \|^2 -\left \| \theta^{t+1}-\theta^* \right \|^2 \right ] + \frac{\eta^t}{2} \left \| g(x^t,\theta^t) \right \|^2
⟨θt−θ∗,ηtg(xt,θt)⟩=2ηt1[
θt−θ∗
2−
θt+1−θ∗
2]+2ηt
g(xt,θt)
2
代入
(
3
)
(3)
(3)式,我们就有
R
(
T
)
≤
∑
t
=
1
T
1
2
η
t
[
∥
θ
t
−
θ
∗
∥
2
−
∥
θ
t
+
1
−
θ
∗
∥
2
]
⏟
(
a
)
+
∑
t
=
1
T
η
t
2
∥
g
(
x
t
,
θ
t
)
∥
2
⏟
(
b
)
R(T)\leq \underbrace{\sum_{t=1}^{T} \frac{1}{2\eta^t} \left [ \left \| \theta^{t}-\theta^* \right \|^2 -\left \| \theta^{t+1}-\theta^* \right \|^2 \right ] }_{(a)}+ \underbrace{\sum_{t=1}^{T} \frac{\eta^t}{2} \left \| g(x^t,\theta^t) \right \|^2}_{(b)}
R(T)≤(a)
t=1∑T2ηt1[
θt−θ∗
2−
θt+1−θ∗
2]+(b)
t=1∑T2ηt
g(xt,θt)
2
我们先来看第一部分
(
a
)
(a)
(a)
(
a
)
=
∑
t
=
1
T
1
2
η
t
[
∥
θ
t
−
θ
∗
∥
2
−
∥
θ
t
+
1
−
θ
∗
∥
2
]
=
1
2
η
1
[
∥
θ
1
−
θ
∗
∥
2
−
∥
θ
2
−
θ
∗
∥
2
]
+
.
.
.
+
1
2
η
T
[
∥
θ
T
−
θ
∗
∥
2
−
∥
θ
T
+
1
−
θ
∗
∥
2
]
=
1
2
η
1
∥
θ
1
−
θ
∗
∥
2
−
1
2
η
T
∥
θ
T
+
1
−
θ
∗
∥
2
+
∑
t
=
2
T
∥
θ
t
−
θ
∗
∥
2
(
1
2
η
t
−
1
2
η
t
−
1
)
(a) = \sum_{t=1}^{T} \frac{1}{2\eta^t} \left [ \left \| \theta^{t}-\theta^* \right \|^2 -\left \| \theta^{t+1}-\theta^* \right \|^2 \right ]\\ = \frac{1}{2\eta^1} \left [ \left \| \theta^{1}-\theta^* \right \|^2 -\left \| \theta^{2}-\theta^* \right \|^2 \right ] + ... + \frac{1}{2\eta^T} \left [ \left \| \theta^{T}-\theta^* \right \|^2 -\left \| \theta^{T+1}-\theta^* \right \|^2 \right ]\\ = \frac{1}{2\eta^1}\left \| \theta^{1}-\theta^* \right \|^2-\frac{1}{2\eta^T}\left \| \theta^{T+1}-\theta^* \right \|^2 + \sum_{t=2}^{T} \left \| \theta^{t}-\theta^* \right \|^2(\frac{1}{2\eta^t}-\frac{1}{2\eta^{t-1}})
(a)=t=1∑T2ηt1[
θt−θ∗
2−
θt+1−θ∗
2]=2η11[
θ1−θ∗
2−
θ2−θ∗
2]+...+2ηT1[
θT−θ∗
2−
θT+1−θ∗
2]=2η11
θ1−θ∗
2−2ηT1
θT+1−θ∗
2+t=2∑T
θt−θ∗
2(2ηt1−2ηt−11)
这里我们还需要添加几个假设
- η t \eta_t ηt序列是单调不递增的,即 η t + 1 ≥ η t , ∀ t ≥ 1 \eta^{t+1}\geq \eta^t,\forall t\geq 1 ηt+1≥ηt,∀t≥1
- D = m a x { ∥ θ t − θ ∗ ∥ } < ∞ D = max\{\left \| \theta^{t}-\theta^* \right \|\}<\infty D=max{∥θt−θ∗∥}<∞
第一点其实比较好理解,因为我们在实际训练的过程中也是保证学习率逐渐变小的,第二点在大部分情况下其实也是成立的。
从而
(
a
)
≤
1
2
η
1
D
2
+
∑
t
=
2
T
D
2
(
1
2
η
t
−
1
2
η
t
−
1
)
=
1
2
η
1
D
2
+
D
2
(
1
2
η
T
−
1
2
η
1
)
=
D
2
2
η
T
(a)\leq \frac{1}{2\eta^1}D^2 + \sum_{t=2}^{T} D^2(\frac{1}{2\eta^t}-\frac{1}{2\eta^{t-1}})\\ =\frac{1}{2\eta^1}D^2 + D^2(\frac{1}{2\eta^T}-\frac{1}{2\eta^{1}})\\ = \frac{D^2}{2\eta^T}
(a)≤2η11D2+t=2∑TD2(2ηt1−2ηt−11)=2η11D2+D2(2ηT1−2η11)=2ηTD2
再来看看第二部分
(
b
)
=
∑
t
=
1
T
η
t
2
∥
g
(
x
t
,
θ
t
)
∥
2
(b) = \sum_{t=1}^{T} \frac{\eta^t}{2} \left \| g(x^t,\theta^t) \right \|^2
(b)=t=1∑T2ηt
g(xt,θt)
2
我们做与上一部分类似的假设
G
=
m
a
x
∥
g
(
x
t
,
θ
t
)
∥
2
<
∞
G = max{\left \| g(x^t,\theta^t) \right \|^2}<\infty
G=max
g(xt,θt)
2<∞
从而
(
b
)
≤
∑
t
=
1
T
G
2
2
η
t
=
G
2
2
∑
t
=
1
T
η
t
(b)\leq \sum_{t=1}^{T}\frac{G^2}{2}\eta^t = \frac{G^2}{2}\sum_{t=1}^{T}\eta^t
(b)≤t=1∑T2G2ηt=2G2t=1∑Tηt
最终我们得到下式
R
(
T
)
=
∑
t
=
1
T
L
(
x
t
,
θ
t
)
−
∑
t
=
1
T
L
(
x
t
,
θ
∗
)
≤
D
2
2
η
T
+
G
2
2
∑
t
=
1
T
η
t
(
4
)
R(T)=\sum_{t=1}^{T}L(x^t,\theta^t)-\sum_{t=1}^{T}L(x^t,\theta^*)\leq \frac{D^2}{2\eta^T} + \frac{G^2}{2}\sum_{t=1}^{T}\eta^t\ \ \ \ \ (4)
R(T)=t=1∑TL(xt,θt)−t=1∑TL(xt,θ∗)≤2ηTD2+2G2t=1∑Tηt (4)
如果我们将上界取高的话,
D
,
G
D,G
D,G完全可以视作常数,从而右式就是一个只跟学习率
η
t
\eta^t
ηt有关的式子了
我们没能做到一开始期望的将右式处理成只跟T有关,事实上这也不太现实。不过只跟 η t \eta^t ηt有关的话,这也意味着只要我们的学习率策略取的足够好,使得右式关于T的最高阶小于1,那么SGD的收敛性就还是存在的。
例如,如果我们取学习率为
C
⋅
t
−
1
/
2
C\cdot t^{-1/2}
C⋅t−1/2,其中
C
>
0
C>0
C>0为常数,那么
R
(
T
)
≤
D
2
T
2
C
+
C
G
2
2
∑
t
=
1
T
1
t
≤
D
2
T
2
C
+
C
G
2
2
∑
t
=
1
T
2
t
−
1
+
t
≤
D
2
T
2
C
+
C
G
2
2
∑
t
=
1
T
2
(
t
−
t
−
1
)
≤
D
2
T
2
C
+
C
G
2
T
R(T)\leq \frac{D^2\sqrt{T}}{2C} + \frac{CG^2}{2}\sum_{t=1}^{T}\frac{1}{\sqrt{t}}\\ \leq \frac{D^2\sqrt{T}}{2C} + \frac{CG^2}{2}\sum_{t=1}^{T}\frac{2}{\sqrt{t-1}+\sqrt{t}}\\ \leq \frac{D^2\sqrt{T}}{2C} + \frac{CG^2}{2}\sum_{t=1}^{T}2(\sqrt{t}-\sqrt{t-1})\\ \leq \frac{D^2\sqrt{T}}{2C} + CG^2\sqrt{T}
R(T)≤2CD2T+2CG2t=1∑Tt1≤2CD2T+2CG2t=1∑Tt−1+t2≤2CD2T+2CG2t=1∑T2(t−t−1)≤2CD2T+CG2T
从而
1
T
R
(
T
)
≤
D
2
2
C
T
+
C
G
2
T
\frac{1}{T}R(T) \leq \frac{D^2}{2C\sqrt{T}} + \frac{CG^2}{\sqrt{T}}
T1R(T)≤2CTD2+TCG2
而如果将学习率取为常数
η
\eta
η的话,
(
4
)
(4)
(4)式右端为
D
2
2
η
T
+
G
2
2
∑
t
=
1
T
η
t
=
D
2
2
η
+
G
2
2
T
η
≥
D
G
T
2
\frac{D^2}{2\eta^T} + \frac{G^2}{2}\sum_{t=1}^{T}\eta^t = \frac{D^2}{2\eta} + \frac{G^2}{2}T\eta\geq \frac{DG\sqrt{T}}{2}
2ηTD2+2G2t=1∑Tηt=2ηD2+2G2Tη≥2DGT
从而当学习率
η
\eta
η取为
D
D
T
\frac{D}{D\sqrt{T}}
DTD时,有
1
T
R
(
T
)
≤
D
G
2
T
\frac{1}{T}R(T)\leq \frac{DG}{2\sqrt{T}}
T1R(T)≤2TDG
可以看到两者都是
O
(
1
T
)
O(\frac{1}{\sqrt{T}})
O(T1)级别的,当
T
→
∞
T\rightarrow \infty
T→∞时,都是能收敛的。
当然我们也能看出来,当学习率取的不好的时候, R ( T ) R(T) R(T)的上界可能会非常松,那么所谓收敛性也就无从谈起了。
实验
( 4 ) (4) (4)式与学习率的关系如此紧密,这也难怪SGD这种方法会对超参数如此敏感。本人简单做了一个不同学习率下的对比实验,学习率都设置为常数,可以看到不同情况下loss的下降曲线差异也是很大的。
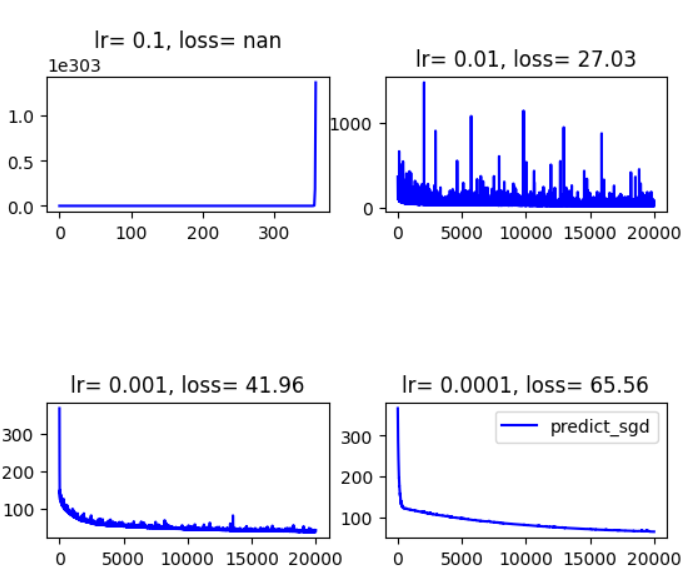
同时做了另一组,学习率取为 C t − 1 / 2 Ct^{-1/2} Ct−1/2,结果为
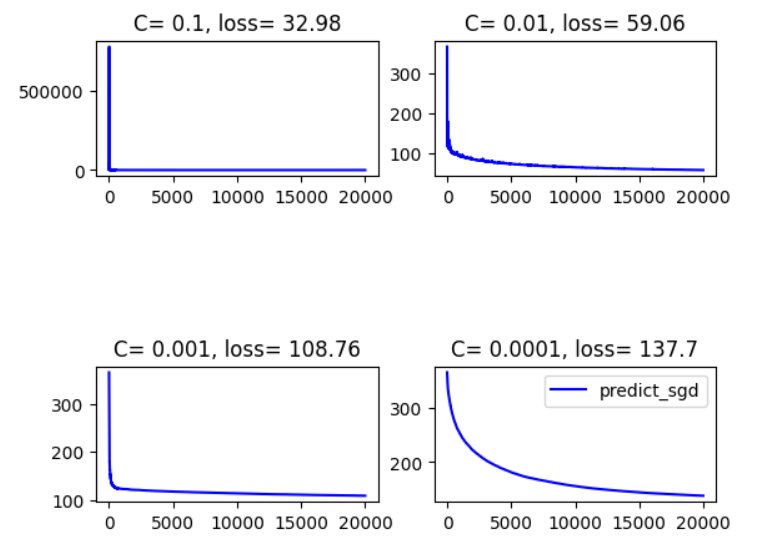
可以看到学习率取常数的话,最终的loss普遍是要比取 C t − 1 / 2 Ct^{-1/2} Ct−1/2要好的,这一点从上面的分析中也许可以解释一下:前者的理论上界为 D G 2 T \frac{DG}{2\sqrt{T}} 2TDG,而后者的理论上界为 D 2 2 C T + C G 2 T \frac{D^2}{2C\sqrt{T}} + \frac{CG^2}{\sqrt{T}} 2CTD2+TCG2,是要更大的
但是取常数貌似受随机性的影响会更大
以及学习率如果过小的话,loss下降速度也会受到影响,对应的最终的loss仿佛也会偏高。
以上是笔者作为初学者的一些探究,或许在之后的学习过程中能找到更加合理的解释。如果文章有错误的话也欢迎指教。
总结
我们证明了SGD在一定的假设下确实可以收敛,这些假设为:
- 损失函数 L ( x t , θ t ) , ∀ t ≥ 1 L(x^t,\theta^t),\forall t\geq 1 L(xt,θt),∀t≥1关于 θ \theta θ是convex函数
- 学习率 η t \eta_t ηt序列是单调不递增的,即 η t + 1 ≥ η t , ∀ t ≥ 1 \eta^{t+1}\geq \eta^t,\forall t\geq 1 ηt+1≥ηt,∀t≥1,非常合理
- D = m a x { ∥ θ t − θ ∗ ∥ } < ∞ D = max\{\left \| \theta^{t}-\theta^* \right \|\}<\infty D=max{∥θt−θ∗∥}<∞,实际上它要求参数位于线性空间的一个有界集合内
- G = m a x ∥ g ( x t , θ t ) ∥ 2 < ∞ G = max{\left \| g(x^t,\theta^t) \right \|^2}<\infty G=max∥g(xt,θt)∥2<∞,也就是梯度有界
其余诸如损失函数可导等条件略过。
证明的重要一环便是
(
1
)
(1)
(1)式
1
T
∑
t
=
1
T
L
(
x
t
,
θ
t
)
−
1
T
∑
t
=
1
T
L
(
x
t
,
θ
∗
)
=
1
T
R
(
T
)
\frac{1}{T}\sum_{t=1}^{T}L(x^t,\theta^t)-\frac{1}{T}\sum_{t=1}^{T}L(x^t,\theta^*)=\frac{1}{T}R(T)
T1t=1∑TL(xt,θt)−T1t=1∑TL(xt,θ∗)=T1R(T)
它衡量了实际迭代过程与理论最优过程的差距,在学习率的选择上我们或许也可以以最小化这个式子的理论上界为目标。当然这只是加了很多假设的理论分析,实操不见得有效。
最终得到在给定假设下上式的理论上界为
1
T
R
(
T
)
=
∑
t
=
1
T
1
T
L
(
x
t
,
θ
t
)
−
1
T
∑
t
=
1
T
L
(
x
t
,
θ
∗
)
≤
D
2
2
T
η
T
+
G
2
2
T
∑
t
=
1
T
η
t
\frac{1}{T}R(T)=\sum_{t=1}^{T}\frac{1}{T}L(x^t,\theta^t)-\frac{1}{T}\sum_{t=1}^{T}L(x^t,\theta^*)\leq \frac{D^2}{2T\eta^T} + \frac{G^2}{2T}\sum_{t=1}^{T}\eta^t
T1R(T)=t=1∑TT1L(xt,θt)−T1t=1∑TL(xt,θ∗)≤2TηTD2+2TG2t=1∑Tηt
感觉还是很有收获的!
参考文献
[1] M. Zinkevich, “Online convex programming and generalized infinitesimal gradient ascent,” in Proceedings of the 20th international conference on machine learning (ICML-03), 2003, pp. 928– 936.















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









