







狭义的self attention
self attention这个说法来自于attention is all you need这篇论文,它也是构成transformer的基础。提出的原因是因为基于rnn做attention的话,是无法做并行化且rnn的结构在长距离的依赖的时候效果并不好。
self attention是针对key,value,query三个变量来计算的。这三个变量都来自于自己的本身乘以一个矩阵变换而来。因此叫做self attention。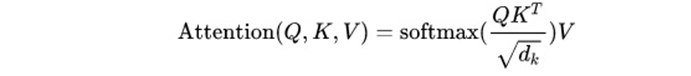
计算attention的公式就是q和k之间计算点乘,然后为了防止尺度过大,会除以维度开更。之后做softmax乘以v。可以从动图中更加好地来理解这个过程。
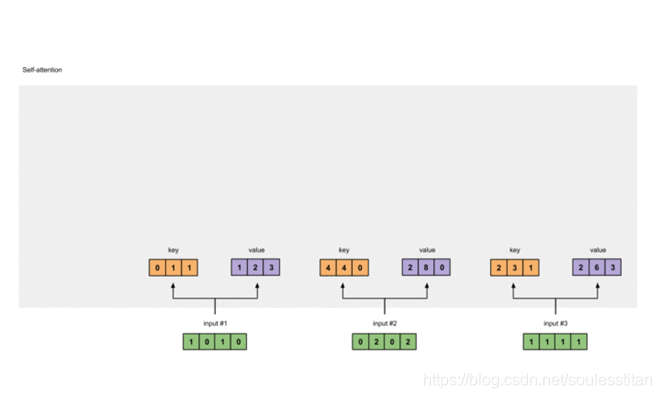
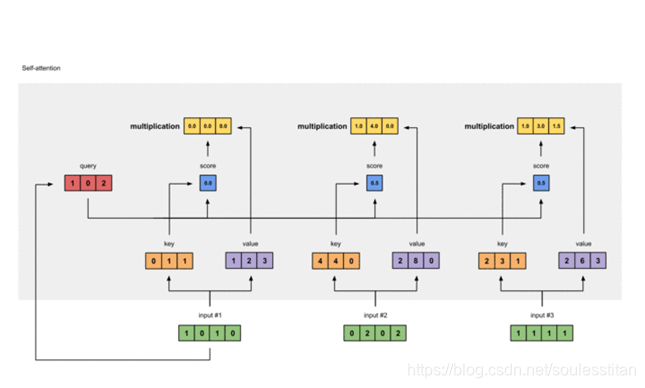
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1458
1458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









