






一、申请Milvus试用版
快速创建Milvus实例_向量检索服务 Milvus 版(Milvus)-阿里云帮助中心
二、配置
pip3 install pymilvus tqdm dashscope由于在下文使用的时候需要用到Milvus的公网地址,而公网地址需要我们手动开启,参考下面这篇文章开启公网地址,以及将自己的ip地址放到白名单中。
网络访问与安全设置_向量检索服务 Milvus 版(Milvus)-阿里云帮助中心
三、接入Milvus向量数据库
将CEC-corpus这个文件下载到项目中,然后配置访问milvus的参数,记得修改API Key和自己设置的密码。
import os
import dashscope
from dashscope import Generation
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection
from dashscope import TextEmbedding
def getEmbedding(news):
model = TextEmbedding.call(
model=TextEmbedding.Models.text_embedding_v1,
input=news
)
embeddings = [record['embedding'] for record in model.output['embeddings']]
return embeddings if isinstance(news, list) else embeddings[0]
def getAnswer(query, context):
prompt = f'''请基于```内的报道内容,回答我的问题。
```
{context}
```
我的问题是:{query}。
'''
rsp = Generation.call(model='qwen-turbo', prompt=prompt)
return rsp.output.text
def search(text):
# Search parameters for the index
search_params = {
"metric_type": "L2"
}
results = collection.search(
data=[getEmbedding(text)], # Embeded search value
anns_field="embedding", # Search across embeddings
param=search_params,
limit=1, # Limit to five results per search
output_fields=['text'] # Include title field in result
)
ret = []
for hit in results[0]:
ret.append(hit.entity.get('text'))
return ret
if __name__ == '__main__':
current_path = os.path.abspath(os.path.dirname(__file__)) # 当前目录
root_path = os.path.abspath(os.path.join(current_path, '..')) # 上级目录
data_path = './CEC-Corpus/raw corpus/allSourceText'
# 配置Dashscope API KEY
dashscope.api_key = 'your API KEY'
# 配置Milvus参数
COLLECTION_NAME = 'CEC_Corpus'
DIMENSION = 1536
MILVUS_HOST = 'c-2ed2541447ff3729.milvus.aliyuncs.com'
MILVUS_PORT = '19530'
USER = 'root'
PASSWORD = 'your password'
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT, user=USER, password=PASSWORD)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='Ids', is_primary=True, auto_id=False),
FieldSchema(name='text', dtype=DataType.VARCHAR, description='Text', max_length=4096),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='Embedding vectors', dim=DIMENSION)
]
schema = CollectionSchema(fields=fields, description='CEC Corpus Collection')
collection = Collection(name=COLLECTION_NAME, schema=schema)
# Load the collection into memory for searching
collection.load()
question = '北京中央电视台工地发生大火,发生在哪里?出动了多少辆消防车?人员伤亡情况如何?'
context = search(question)
answer = getAnswer(question, context)
print(answer)回答如下: 可以发现这个回答是基于刚刚的新闻数据集进行回答的

四、往数据库中插入信息
创建一个insert.py
import os
import requests
import dashscope
from dashscope import Generation
import json
from pymilvus import connections, utility, FieldSchema, CollectionSchema, DataType, Collection
def main():
# 配置参数
OLLAMA_API_URL = "http://localhost:11434/api/embeddings"
COLLECTION_NAME = "milvus_example"
DIMENSION = 768 # Ollama nomic-embed-text 模型的维度
# 配置Dashscope API KEY
dashscope.api_key = 'your API KEY'
# Milvus 连接配置
MILVUS_HOST = 'c-2ed2541447ff3729.milvus.aliyuncs.com'
MILVUS_PORT = '19530'
USER = 'root'
PASSWORD = 'your password'
# 1. 连接到Milvus
connections.connect(
host=MILVUS_HOST,
port=MILVUS_PORT,
user=USER,
password=PASSWORD
)
# 2. 检查并获取集合
if not utility.has_collection(COLLECTION_NAME):
# 创建新集合(建议将id字段改为auto_id=True避免手动管理)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields, description="Example collection")
collection = Collection(name=COLLECTION_NAME, schema=schema)
# 创建索引
index_params = {
"index_type": "AUTOINDEX",
"metric_type": "COSINE",
"params": {}
}
collection.create_index("vector", index_params)
print("New collection created with index")
else:
# 获取现有集合
collection = Collection(name=COLLECTION_NAME)
print("Using existing collection")
# 修复点:检查集合加载状态的新方法
try:
# 新版本加载方式(无需检查状态,重复加载安全)
collection.load()
print("Collection loaded into memory")
except Exception as e:
print(f"Error loading collection: {e}")
return
# 6. 准备数据(建议使用auto_id=True避免手动管理ID)
text_array = [
"Hello, this is a test.",
"Milvus is great for vector search.",
"Ollama helps in text embedding."
]
# 获取向量并准备插入数据
ids = []
texts = []
vectors = []
for idx, text in enumerate(text_array):
vector = get_text_embedding(OLLAMA_API_URL, text)
if vector:
# 更安全的ID生成方式(示例中使用当前实体数+idx,实际建议用auto_id)
new_id = collection.num_entities + idx
ids.append(new_id)
texts.append(text)
vectors.append(vector)
if ids:
try:
collection.insert([ids, texts, vectors])
collection.flush()
print(f"Successfully inserted {len(ids)} records")
except Exception as e:
print(f"Insert failed: {e}")
else:
print("No valid data to insert")
# 8. 执行向量搜索
query_text = "ollama有什么作用?"
query_vector = get_text_embedding(OLLAMA_API_URL, query_text)
if not query_vector:
print("Failed to get query vector")
return
search_params = {
"metric_type": "COSINE",
"params": {}
}
results = collection.search(
data=[query_vector],
anns_field="vector",
param=search_params,
limit=1,
output_fields=["text"]
)
# 9. 处理搜索结果
if results:
for hits in results:
for hit in hits:
print(f"Matched text: {hit.entity.text}")
print(f"Similarity score: {hit.score}")
else:
print("No results found")
# 10. 清理资源
connections.disconnect("milvus_example")
def get_text_embedding(api_url, text):
"""调用Ollama Embedding API获取文本向量"""
try:
headers = {"Content-Type": "application/json"}
payload = {
"model": "nomic-embed-text",
"prompt": text
}
response = requests.post(api_url, headers=headers, json=payload)
if response.status_code == 200:
result = response.json()
return result.get("embedding")
else:
print(f"API request failed: {response.status_code} - {response.text}")
return None
except Exception as e:
print(f"Error getting embedding: {e}")
return None
if __name__ == "__main__":
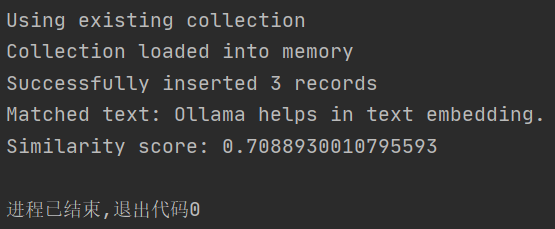
main()运行结果如下: 我们成功的插入了3条数据,并且返回了和ollama相关的回答。
五、构建具有长期记忆的对话机器人
创建一个chatbot.py
import os
import dashscope
import requests
from dashscope import Generation, TextEmbedding
from pymilvus import connections, utility, FieldSchema, CollectionSchema, DataType, Collection
# 配置参数
DASH_SCOPE_API_KEY = 'your API_KEY'
MILVUS_HOST = 'c-2ed2541447ff3729.milvus.aliyuncs.com'
MILVUS_PORT = '19530'
MILVUS_USER = 'root'
MILVUS_PASSWORD = 'your password'
OLLAMA_API_URL = "http://localhost:11434/api/embeddings"
# 全局配置
dashscope.api_key = DASH_SCOPE_API_KEY
NEWS_EMBEDDING_DIM = 1536 # Dashscope文本嵌入维度
CHAT_EMBEDDING_DIM = 768 # Ollama nomic-embed-text的维度
class ChatBot:
def __init__(self):
# 初始化Milvus连接
connections.connect(
host=MILVUS_HOST,
port=MILVUS_PORT,
user=MILVUS_USER,
password=MILVUS_PASSWORD
)
# 初始化对话历史集合(强制更新schema)
self.chat_collection = self.init_chat_collection()
def init_chat_collection(self):
"""初始化对话历史集合(保留现有数据)"""
name = "chathistory8"
desc = "对话历史记录(id, text, vector)"
# 如果集合不存在则创建
if not utility.has_collection(name):
print(f"创建新对话集合:{name}")
# 创建字段结构
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=1024),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=CHAT_EMBEDDING_DIM)
]
schema = CollectionSchema(fields, description=desc)
collection = Collection(name, schema)
# 创建索引
index_params = {
"index_type": "AUTOINDEX",
"metric_type": "COSINE",
"params": {}
}
collection.create_index("vector", index_params)
# 插入初始数据(仅在新创建时插入)
initial_texts = [
"Hello, this is a test.",
"Milvus is great for vector search.",
"Ollama helps in text embedding."
]
ids = list(range(len(initial_texts)))
vectors = [self.get_chat_embedding(text) for text in initial_texts]
# 过滤掉嵌入失败的条目
valid_data = [(i, t, v) for i, t, v in zip(ids, initial_texts, vectors) if v is not None]
if valid_data:
try:
# 解包有效数据
ids, texts, vectors = zip(*valid_data)
collection.insert([list(ids), list(texts), list(vectors)])
collection.flush()
print(f"插入初始数据 {len(valid_data)} 条")
except Exception as e:
print(f"初始数据插入失败:{str(e)}")
collection.load()
return collection
else:
# 直接加载现有集合
collection = Collection(name)
collection.load()
print(f"使用现有对话集合:{name}(包含 {collection.num_entities} 条记录)")
return collection
def save_conversation(self, question):
"""保存用户提问到对话历史"""
vector = self.get_chat_embedding(question)
if not vector:
return
# 生成新ID(当前实体数量)
new_id = self.chat_collection.num_entities
try:
self.chat_collection.insert([
[new_id], # id字段
[question], # text字段
[vector] # vector字段
])
self.chat_collection.flush()
print(f"保存成功,ID:{new_id}")
except Exception as e:
print(f"保存失败:{str(e)}")
def get_chat_embedding(self, text):
"""使用Ollama获取对话嵌入"""
try:
headers = {"Content-Type": "application/json"}
payload = {
"model": "nomic-embed-text",
"prompt": text
}
response = requests.post(OLLAMA_API_URL, headers=headers, json=payload)
if response.status_code == 200:
return response.json().get("embedding")
print(f"Ollama API错误:{response.status_code} - {response.text}")
except Exception as e:
print(f"对话嵌入失败:{str(e)}")
return None
def semantic_search(self, collection, query, limit=3):
"""语义搜索(自动适配不同集合)"""
vector = self.get_chat_embedding(query)
anns_field = "vector"
metric = "COSINE"
if not vector:
return []
# 执行搜索
results = collection.search(
data=[vector],
anns_field=anns_field,
param={"metric_type": metric},
limit=limit,
output_fields=['text']
)
return [hit.entity.text for hit in results[0]]
def generate_answer(self, query, chat_context):
"""生成回答(增强提示词)"""
prompt = f"""你是一个聊天机器人小A,请你基于以下与用户的聊天记录,用中文与用户进行对话:
[相关历史对话]
{chat_context}
问题:{query}
要求:
1. 必要的时候结合聊天记录进行回答,其他时候正常回答
2. 保持回答温柔且耐心
请直接给出答案,不要包含来源标记。"""
try:
resp = Generation.call(model='qwen-turbo', prompt=prompt)
return resp.output.text
except Exception as e:
return f"回答生成失败:{str(e)}"
def chat_loop(self):
"""修正后的对话主循环"""
print("欢迎使用问答系统(输入exit退出)")
while True:
try:
query = input("\n用户:").strip()
if query.lower() in ['exit', 'quit']:
break
chat_results = self.semantic_search(self.chat_collection, query, limit=20)
# 构建上下文
chat_context = "\n".join([f"- 历史提问:{text}" for text in chat_results])
# 生成回答
answer = self.generate_answer(query, chat_context)
print(f"\n助手:{answer}")
# 保存对话
self.save_conversation(query)
except Exception as e:
print(f"系统错误:{str(e)}")
if __name__ == "__main__":
bot = ChatBot()
bot.chat_loop()
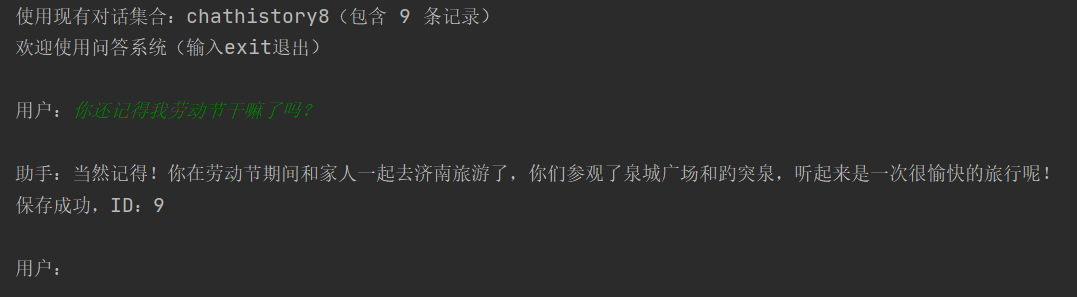
connections.disconnect()效果如下:

















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









