






 本文探讨了在互联网快速发展的背景下,如何利用深度学习技术改进传统的微博数据分析方法,以提取有价值的信息和趋势预测。研究涉及从数据采集、清洗、到利用Hive和Spark进行离线和实时分析,以及使用深度学习算法进行个性化推荐和流量预测。项目还涵盖了数据可视化和前后端系统的开发,旨在为企业和学术研究提供新的工具和洞察力。
本文探讨了在互联网快速发展的背景下,如何利用深度学习技术改进传统的微博数据分析方法,以提取有价值的信息和趋势预测。研究涉及从数据采集、清洗、到利用Hive和Spark进行离线和实时分析,以及使用深度学习算法进行个性化推荐和流量预测。项目还涵盖了数据可视化和前后端系统的开发,旨在为企业和学术研究提供新的工具和洞察力。
| 研究背景 随着互联网的快速发展,社交媒体平台如微博等逐渐成为人们表达观点、分享信息、交流互动的主要渠道。每天有大量的用户生成内容(UGC)被发布到微博上,这其中蕴含了丰富的信息和社会动态。如何有效地对这些数据进行处理和分析,提取出有价值的信息和趋势预测,成为了一个重要的问题。 传统的微博数据分析方法往往基于人工统计和简单的文本分析,难以处理大规模、复杂的数据,也无法实现精准的趋势预测。近年来,深度学习技术在自然语言处理(NLP)、图像识别、语音识别等领域取得了显著的成果,为处理微博这种富含文本信息的数据提供了新的解决方案。 意义
|
| 二、论文(设计)的主要内容 |
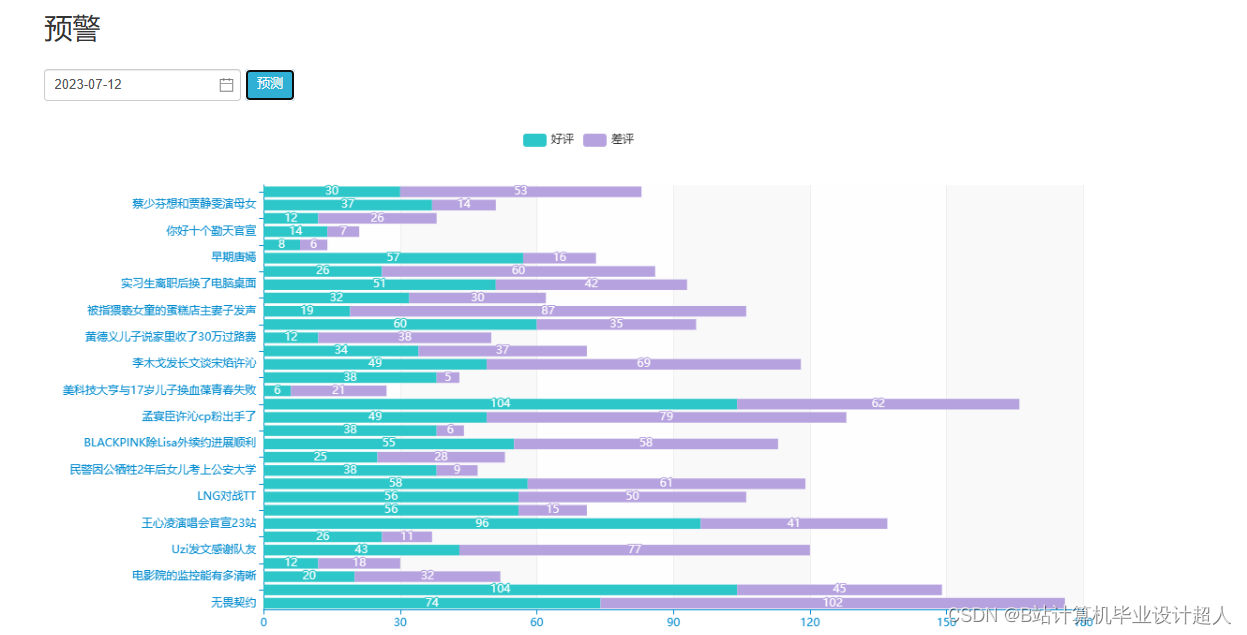
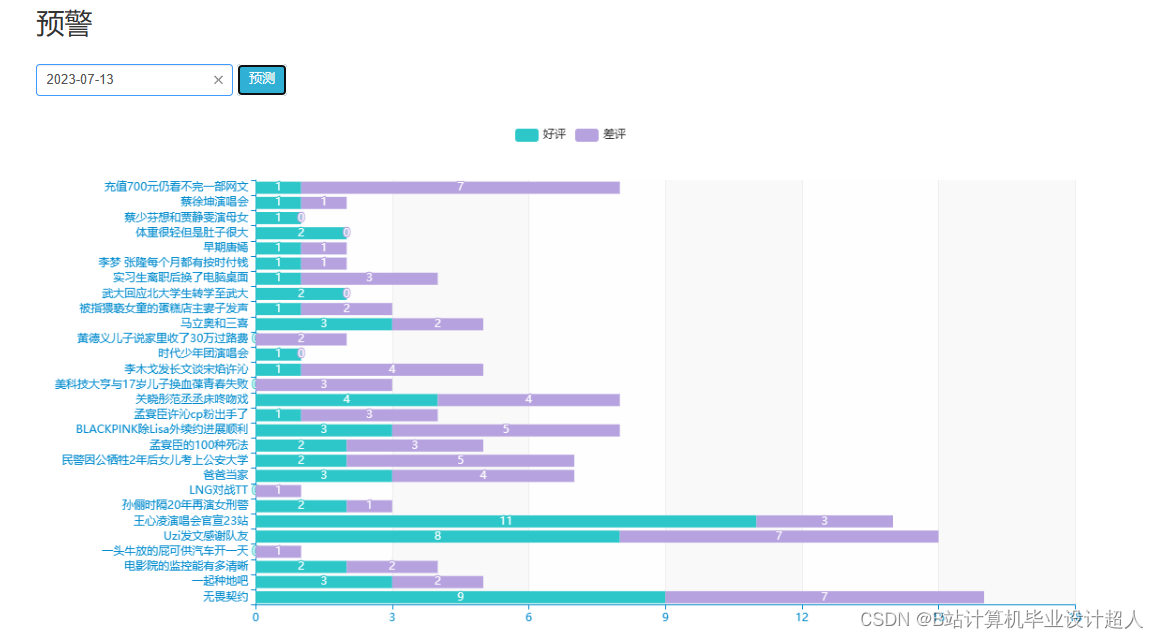
| (一)Selenium自动化Python爬虫工具采集新浪微博评论、热搜、文章等约10万条存入.csv文件作为数据集; (二)使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs; (三)使用hive数仓技术建表建库,导入.csv数据集; (四)离线分析采用hive_sql完成,实时分析利用Spark之Scala完成; (五)统计指标使用sqoop导入mysql数据库; (六)使用Flask+echarts进行可视化大屏开发; (七)使用机器学习、深度学习的算法进行个性化微博推荐; (八)使用卷积神经网络KNN、CNN实现热搜话题流量预测; (九)搭建springboot+vue.js前后端分离web系统进行个性化推荐界面、话题流量预测界面、知识图谱等实现; |
| 三、论文(设计)进度安排 |
7、2024.05.01—2024.05.10:完成毕业答辩,提交所有毕业论文的数据源、图表、论文; |

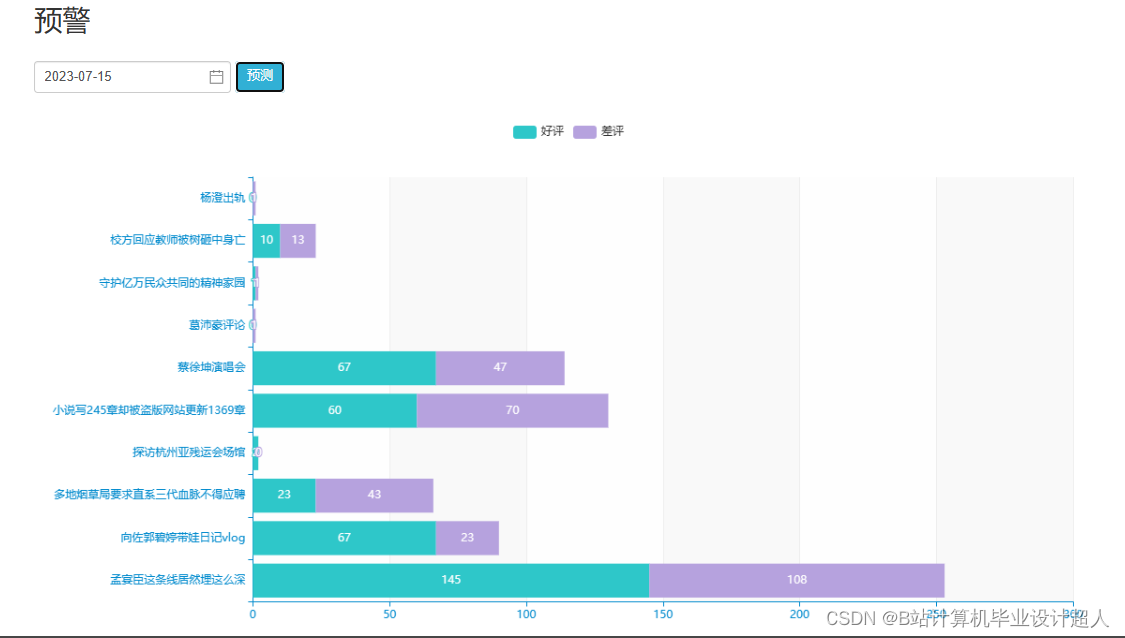
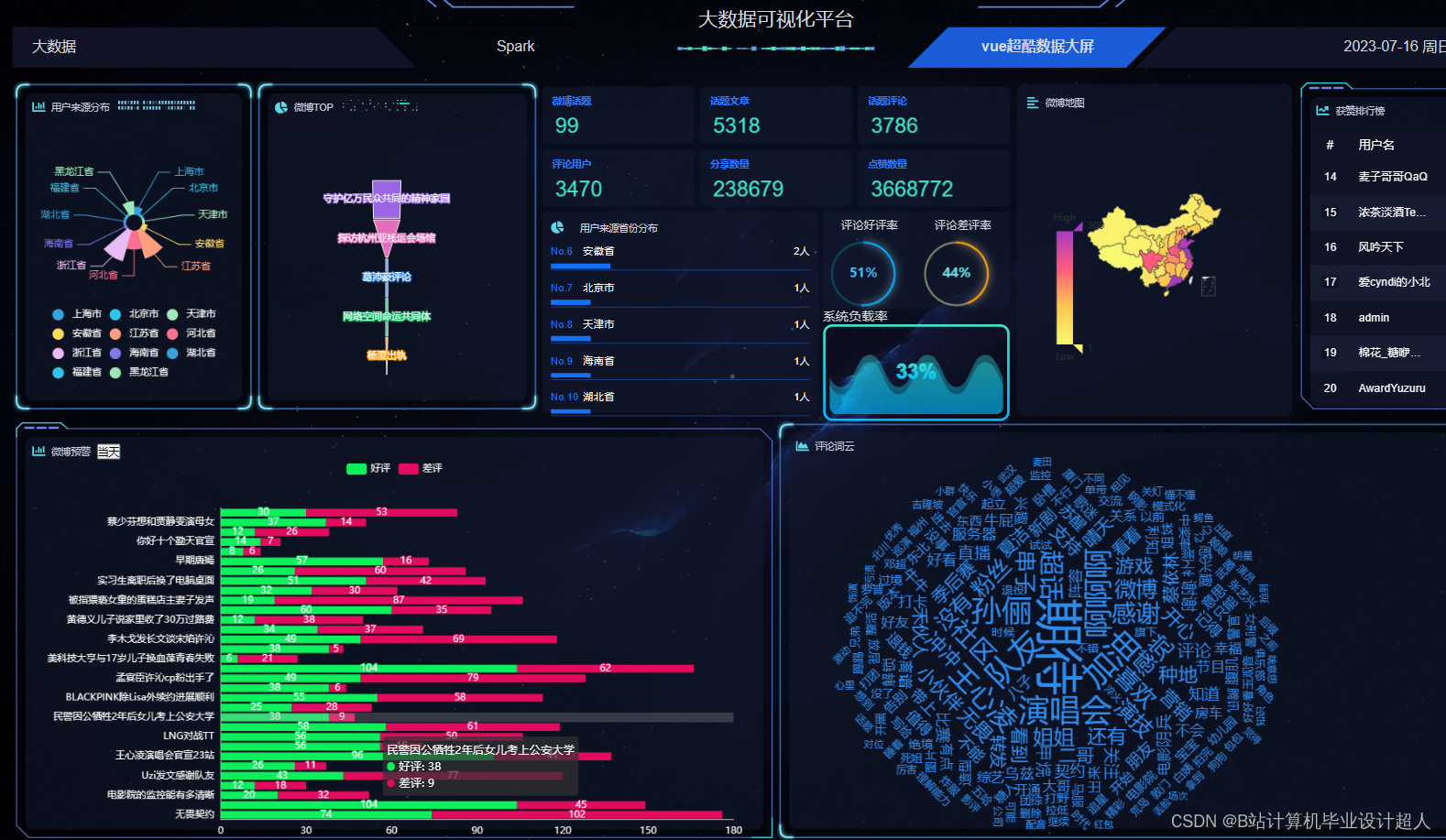
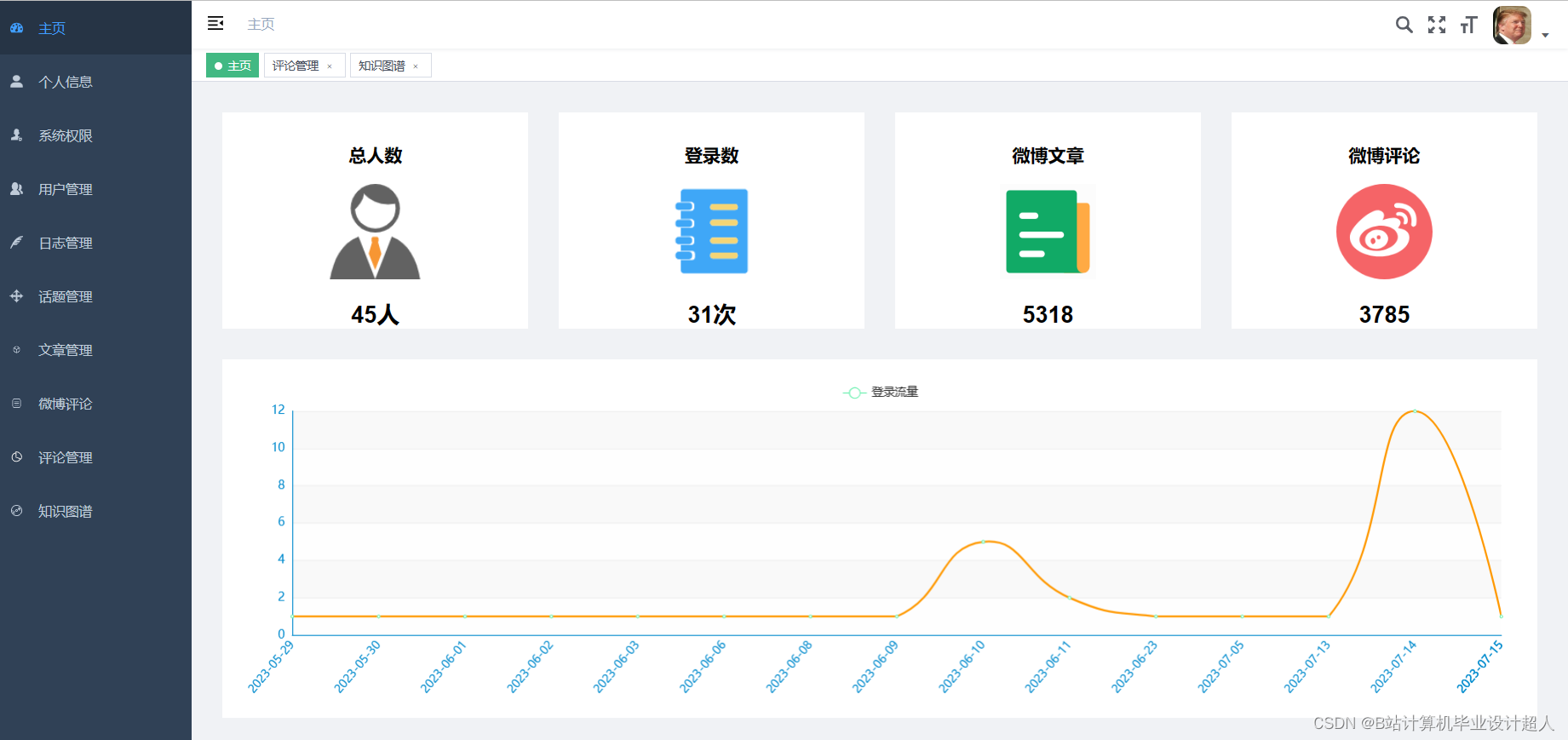
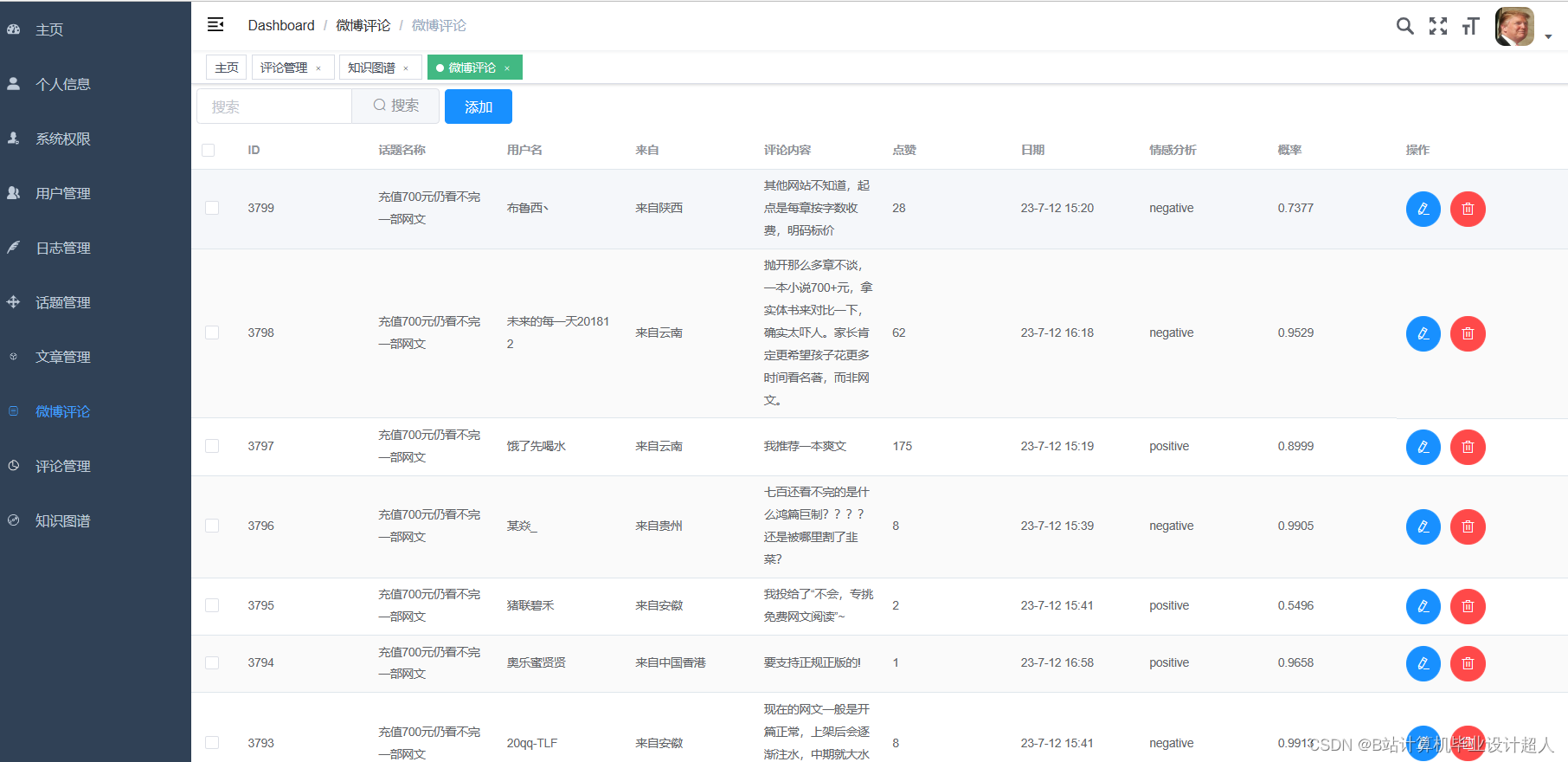
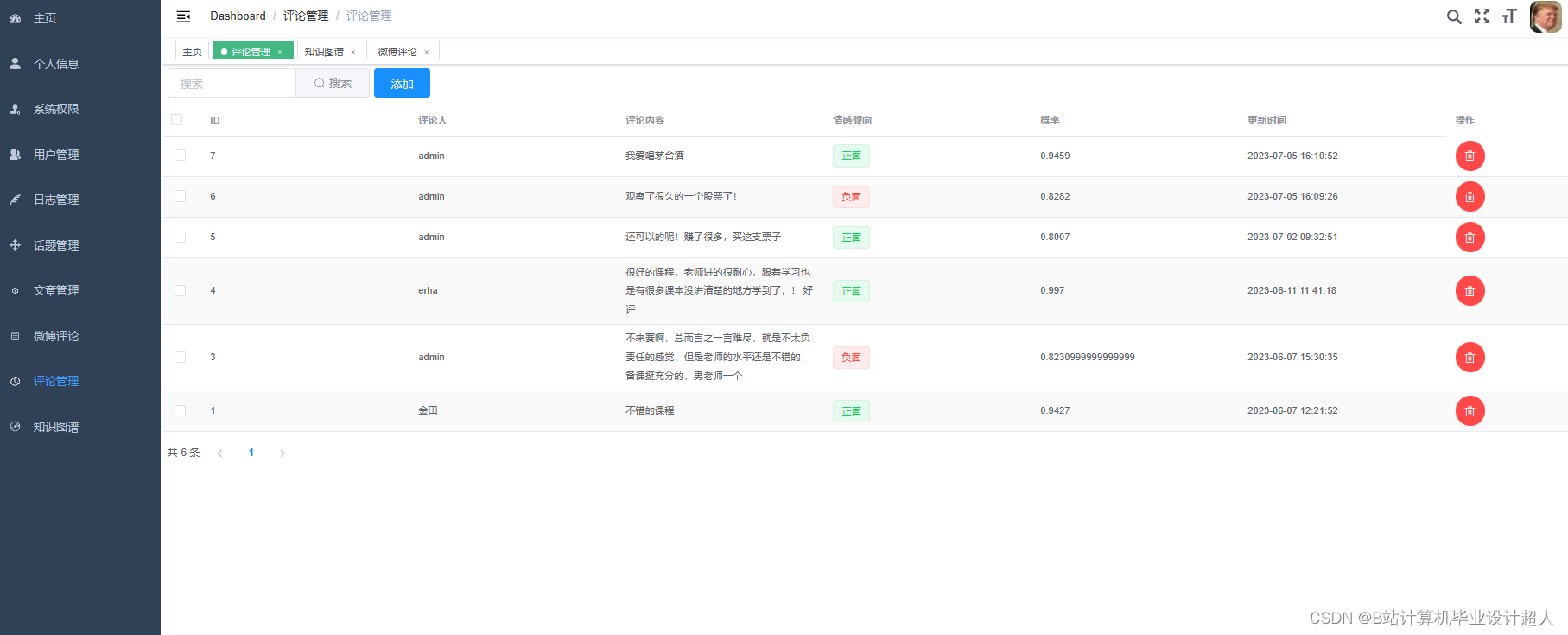
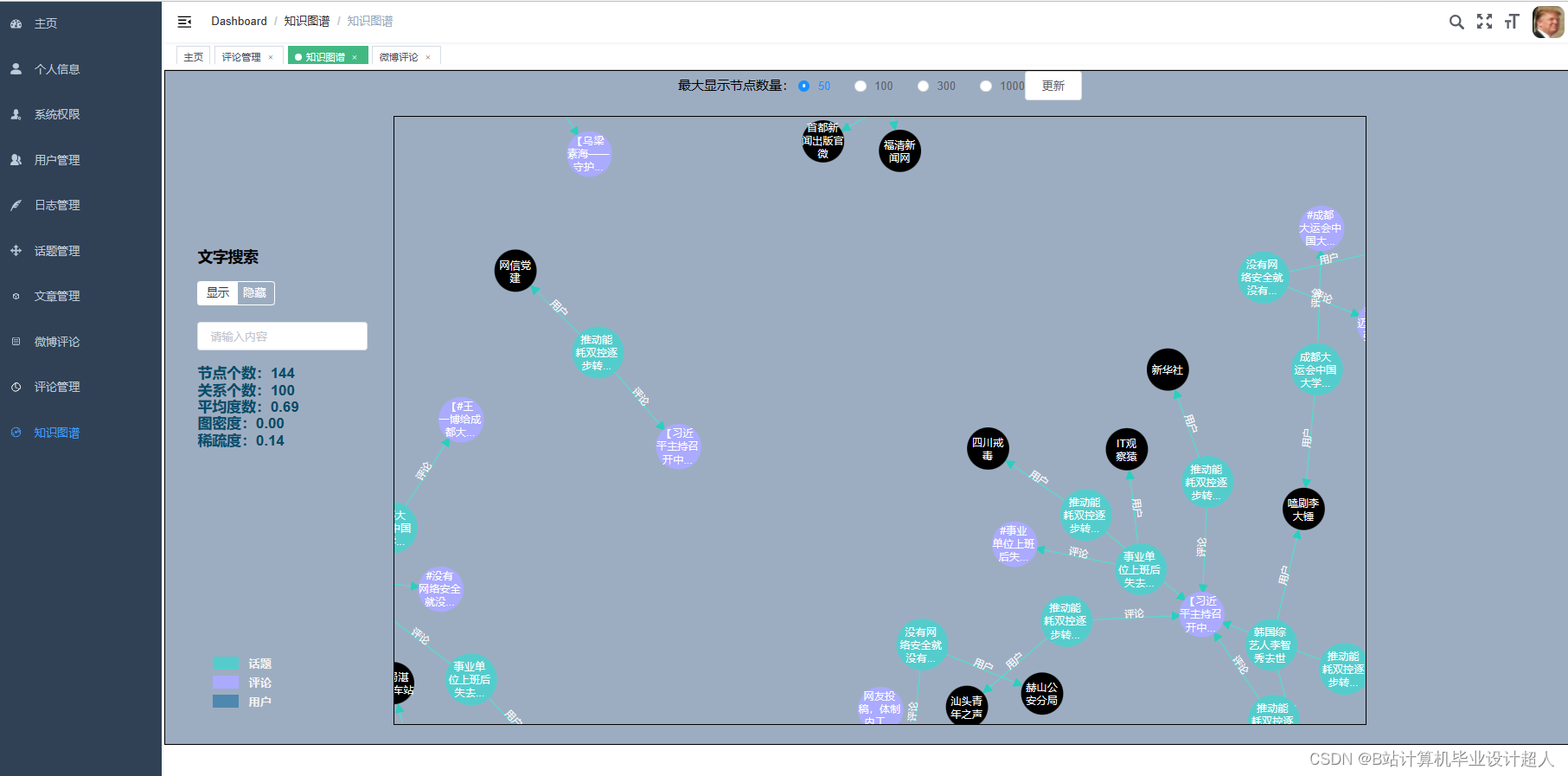
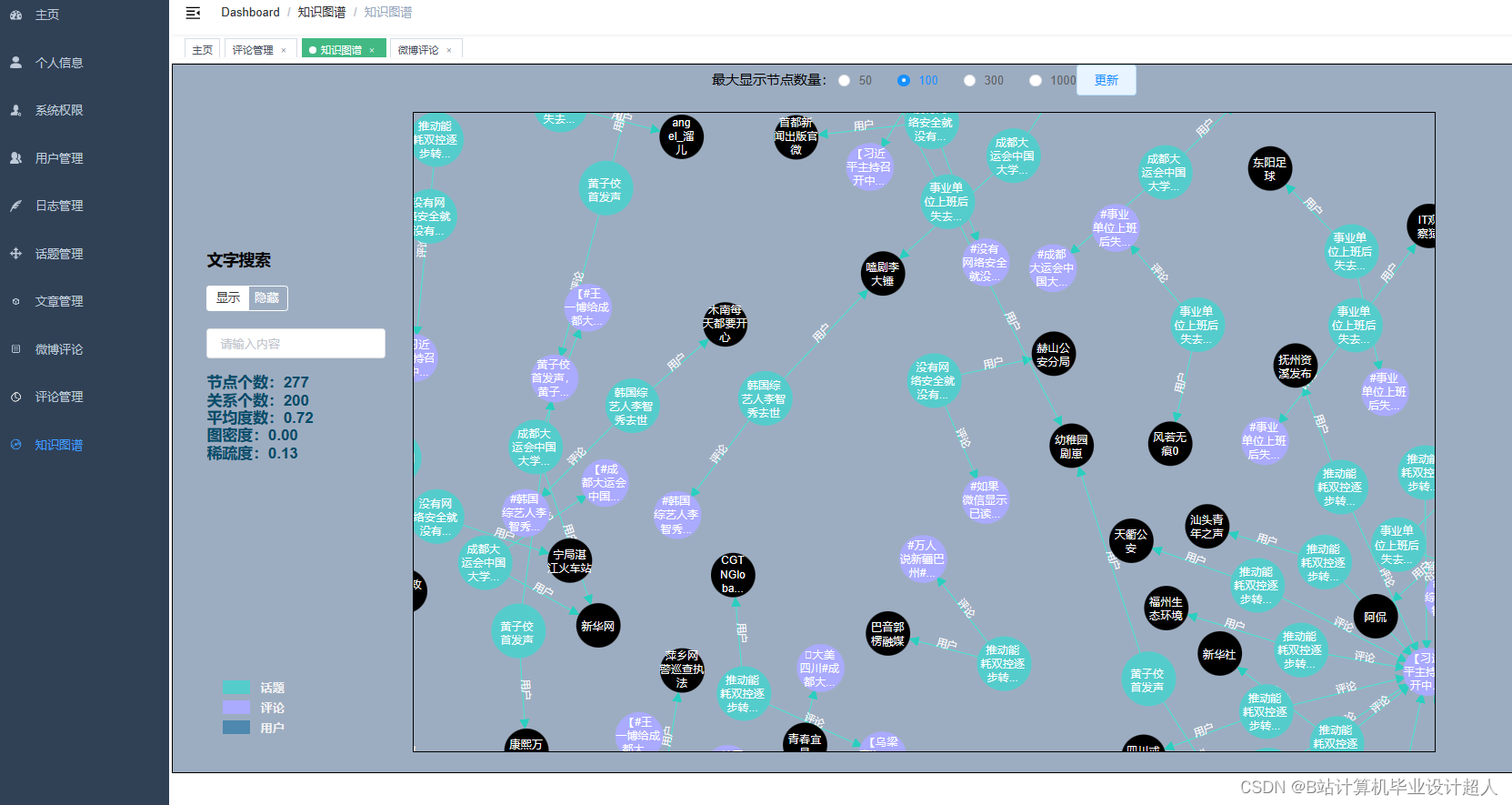
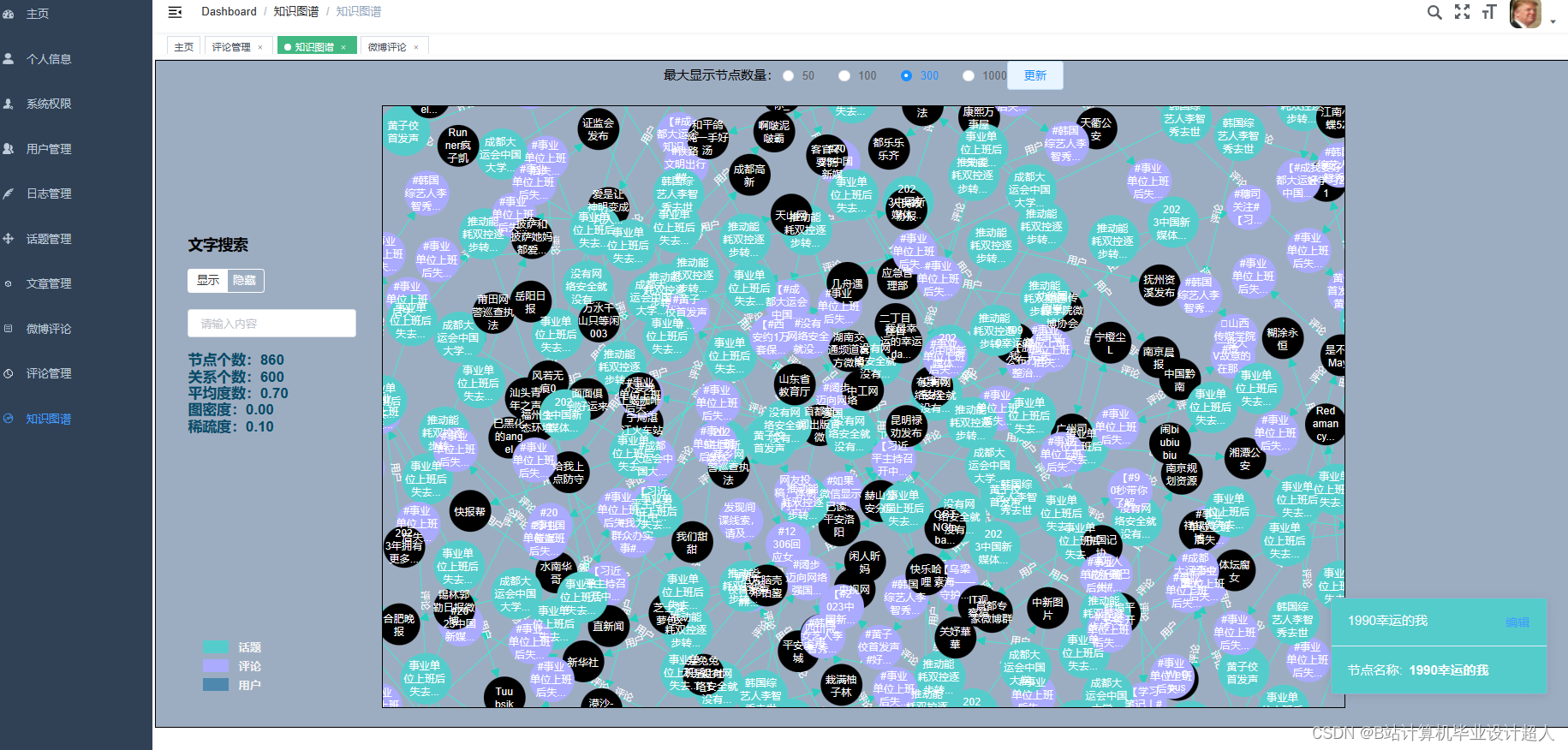
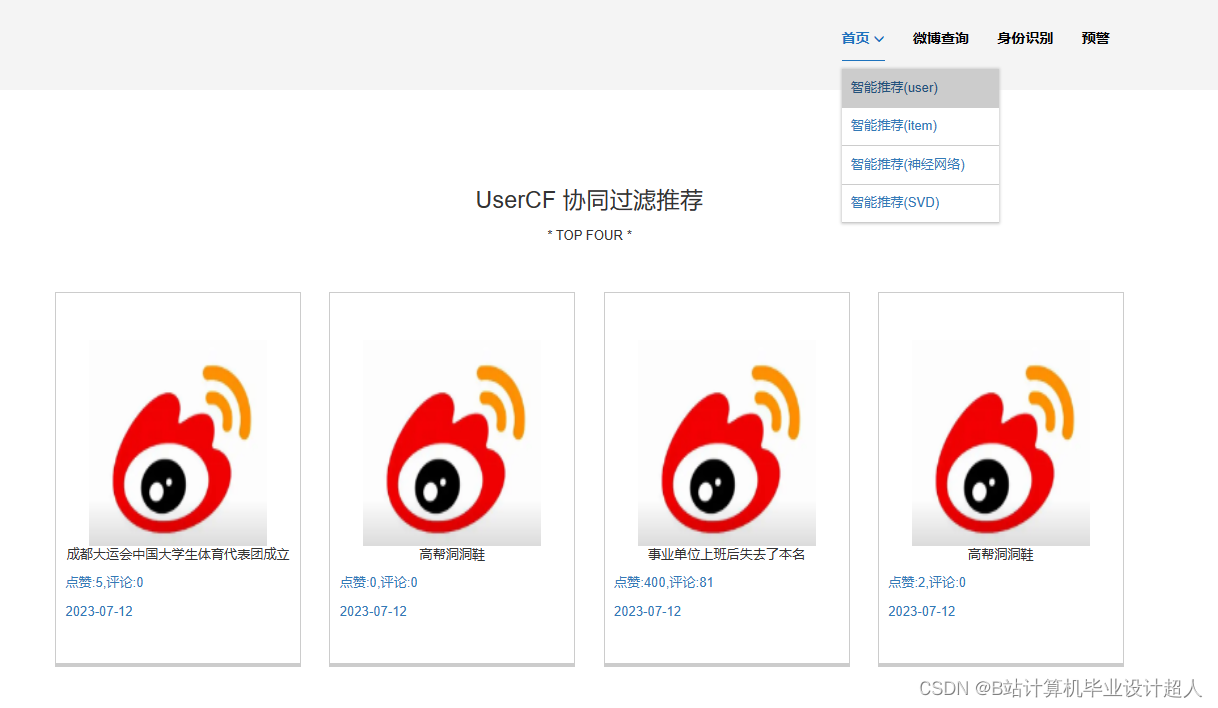
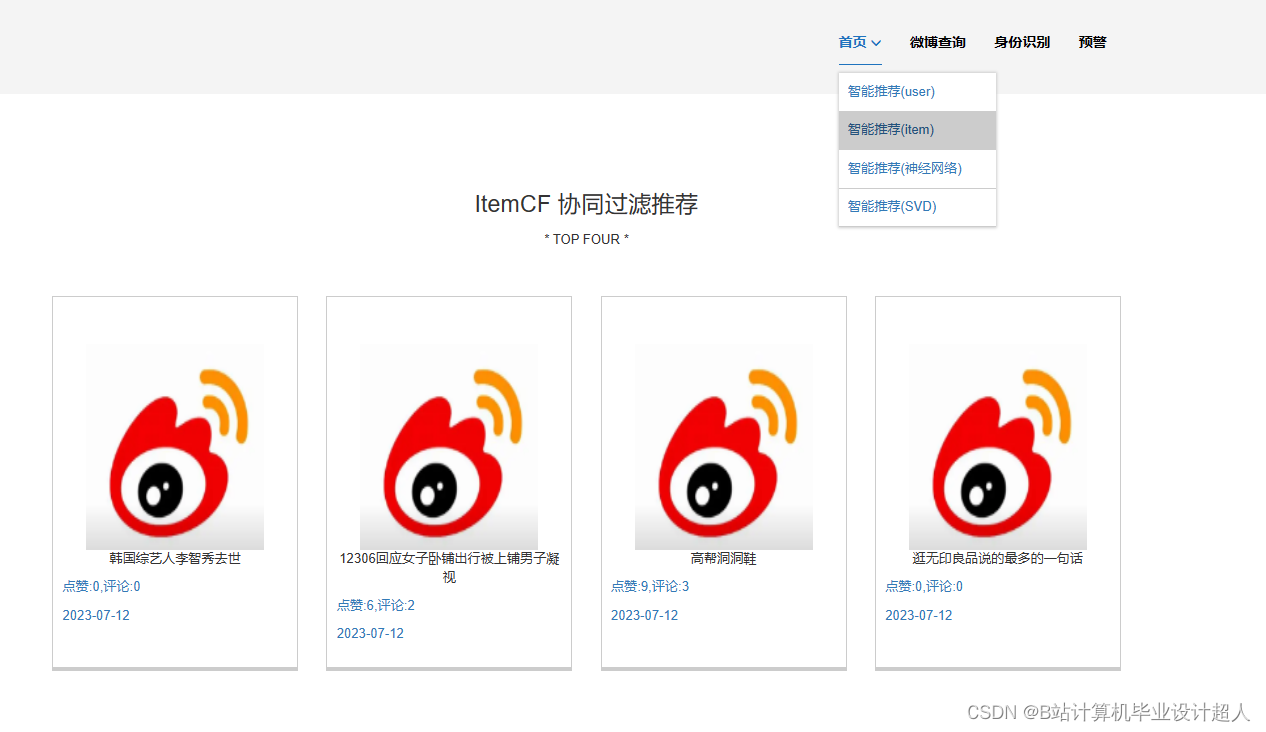
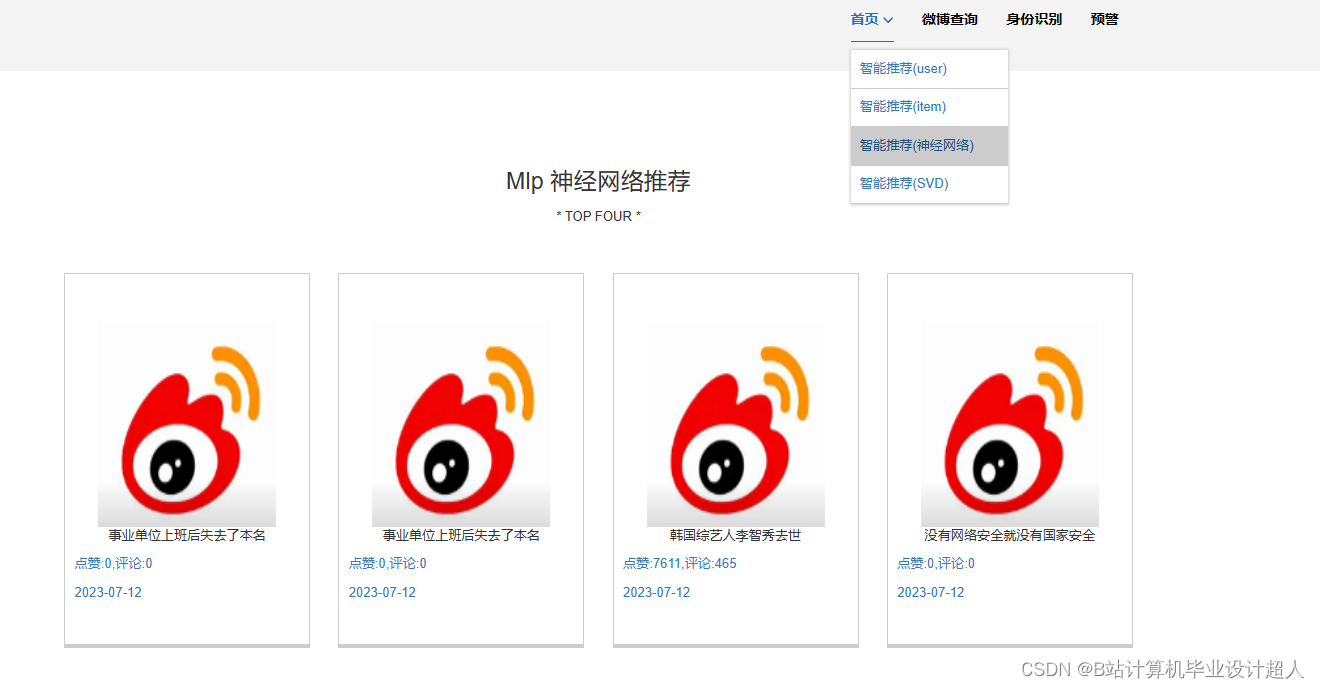
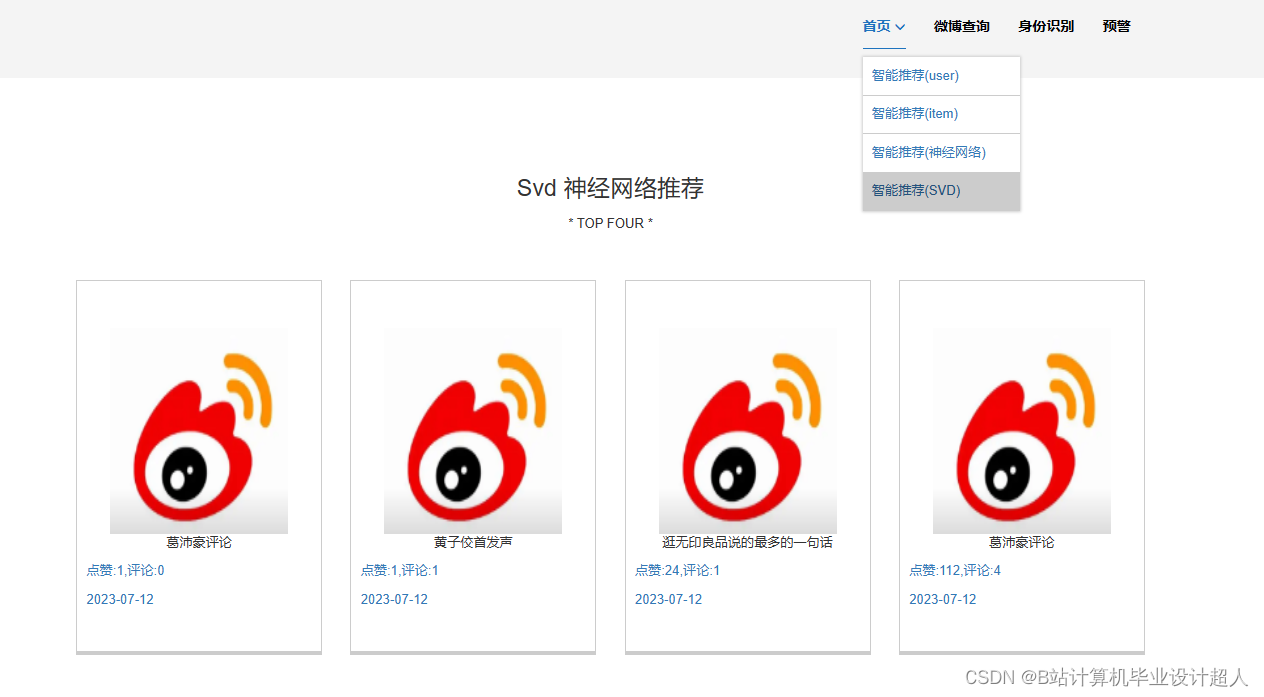
核心代码分享如下,可用于构建图谱:
# -*- codeing = utf-8 -*-
# 创建图谱专用的json文件
#
import numpy as np
import pandas as pd
import json
from db import db_util
d = db_util()
db, cursor = d.get_conn()
def build():
s_dict = {}
t_dict = {}
ret = []
ind1 = 10000
ind2 = 20000
ind3 = 30000
rind = 900000
sql = 'select * from tb_article'
df = pd.read_sql(sql, con=db)
for index, row in df.iterrows():
comment = row['comment']
username = row['username']
if comment not in s_dict:
ind2 = ind2 + 1
s_dict[comment] = ind2
index2 = ind2
else:
index2 = s_dict[comment]
if username not in t_dict:
ind3 = ind3 + 1
t_dict[username] = ind3
index3 = ind3
else:
index3 = t_dict[username]
properties = {"name": row['title'], 'shares': row['shares'], 'comments':row['comments']}
start = {'identity': index, 'labels':['话题'], 'properties':properties}
end = {'identity': index2, 'labels':['评论'], 'properties':{"name": comment}}
relationship = {"identity": rind, "start": index,"end": index2,
"type": "type", "properties": {"name": "评论"}}
rind = rind + 1
segments = []
segments.append(dict(start=start, relationship=relationship, end=end))
end = {'identity': index3, 'labels': ['用户名'], 'properties': {"name": username}}
relationship = {"identity": rind, "start": index, "end": index3,
"type": "type", "properties": {"name": "用户"}}
rind = rind + 1
segments.append(dict(start=start, relationship=relationship, end=end))
p = dict(segments=segments, length=1.0)
ret.append(dict(p=p, score=2))
json_str = json.dumps(ret, ensure_ascii=False)
with open('test.json', 'w', encoding='utf8') as f2:
# ensure_ascii=False才能输入中文,否则是Unicode字符
# indent=2 JSON数据的缩进,美观
json.dump(ret, f2, ensure_ascii=False, indent=2)
print(json_str)
print("end..")
if __name__ == '__main__':
build()

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











