







温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+大模型考研分数线预测系统与考研院校推荐系统文献综述
摘要:随着考研竞争的加剧,考生在院校选择和分数线预测方面面临诸多挑战。本文综述了基于Python与大模型的考研分数线预测系统与考研院校推荐系统的研究现状,分析了数据采集与处理、算法应用、系统架构与可视化技术等关键技术,探讨了现有研究的不足与未来发展方向,旨在为该领域的进一步研究提供参考。
关键词:Python;大模型;考研分数线预测;考研院校推荐;机器学习;数据可视化
一、引言
近年来,我国研究生报考人数持续增长,考研已成为众多大学生提升学历、增强就业竞争力的重要途径。然而,考研分数线的波动性以及院校专业信息的海量性和复杂性,使得考生在备考和志愿填报过程中面临诸多不确定性。传统的人工预测方法和经验式院校推荐存在效率低、主观性强、数据利用率不足等问题,难以满足考生的实际需求。随着大数据、人工智能等新兴技术的迅速发展,基于Python与大模型的考研分数线预测系统与考研院校推荐系统应运而生,为解决这些问题提供了新的思路和方法。
二、研究现状
(一)数据采集与处理
数据质量直接影响预测和推荐系统的准确性。现有研究多采用Scrapy或Requests库爬取教育部官网、各高校研究生院及考研论坛的数据,涵盖院校基本信息、历年分数线、报录比、就业质量报告等。例如,有研究通过解析研招网HTML结构,构建了包含2000余所高校、12个学科门类的标准化数据库。在数据清洗方面,Pandas与NumPy被广泛用于处理缺失值、异常值,并通过One-Hot编码或词嵌入技术将非结构化文本(如院校简介)转化为结构化特征。此外,部分研究还结合高校官方API与爬虫技术,实现招生动态的实时更新,以提高数据的时效性。
(二)算法应用
1. 考研分数线预测算法
在考研分数线预测方面,常用的算法有时间序列分析算法(如ARIMA、Prophet)、机器学习算法(如随机森林、XGBoost)和深度学习算法(如LSTM)。时间序列模型如Prophet算法适用于年度分数线预测,能够捕捉数据的趋势和季节性变化;机器学习模型如随机森林适用于多特征融合预测,能够处理非线性关系;深度学习模型如LSTM适用于长期趋势预测,能够捕捉考研分数线的长期依赖性。为了提高预测精度,系统通常采用集成学习策略,将多个模型的预测结果进行融合。例如,结合交叉验证和网格搜索进行超参数调优,选择最优模型参数,通过实验比较不同算法的性能,选择最优算法构建预测模型。Stacking集成策略可以将多个不同类型的基础模型进行组合,利用一个元模型对基础模型的预测结果进行再次学习,从而进一步提高预测的准确性。
2. 考研院校推荐算法
推荐算法是考研院校推荐系统的核心。协同过滤算法基于用户-院校交互数据(如浏览记录、收藏行为),计算用户相似度并推荐相似用户偏好的院校。例如,有研究通过杰卡德相似度与余弦相似度结合的方式,将推荐准确率提升至82%。内容推荐算法根据院校特征(如学科评估、地理位置)与用户画像(如本科院校、目标专业)进行匹配。有研究引入TF-IDF算法提取院校简介关键词,结合用户历史偏好生成推荐列表。混合推荐算法融合协同过滤与内容推荐的优势,能够综合考虑用户的历史行为和院校的客观特征。例如,有研究提出一种基于加权混合的推荐模型,通过动态调整参数优化推荐结果,在冷启动场景下表现尤为突出。此外,随着大模型技术的发展,基于大模型的语义理解和推理能力,能够进一步提高推荐的准确性和个性化程度。
(三)系统架构与可视化技术
Django框架因其“快速开发”与“可扩展性”优势被广泛采用于考研分数线预测系统与考研院校推荐系统的开发中。前端通常使用Vue.js或React实现响应式界面,支持多条件筛选(如专业、地域)与动态推荐结果展示。后端则利用Django REST Framework(DRF)构建RESTful API,通过JWT实现用户认证与授权。数据库方面,MySQL存储结构化数据,Redis缓存热点数据以提升查询效率。在可视化方面,ECharts或D3.js用于生成柱状图、地图等可视化图表,直观展示院校排名、分数线趋势等信息。例如,用户可通过交互式地图筛选目标城市院校,系统动态调整推荐结果,可视化界面显著提升了决策效率。
三、现有研究的不足
(一)数据时效性
多数系统依赖静态数据,难以实时更新院校招生政策。考研政策每年都可能发生变化,如招生计划的调整、考试科目的变更等,这些变化会直接影响考研分数线和院校的报考热度。然而,现有系统在数据更新方面存在滞后性,不能及时反映这些变化,导致预测和推荐结果的准确性受到影响。
(二)算法可解释性
黑箱模型(如深度学习)难以向用户解释推荐依据。在考研院校推荐系统中,考生往往希望了解推荐结果的原因,以便做出更加合理的决策。然而,一些复杂的深度学习模型缺乏可解释性,无法清晰地说明为什么推荐某个院校,这可能会降低用户对系统的信任度。
(三)多模态数据融合
现有研究多聚焦结构化数据,对图像、视频等非结构化数据利用不足。院校的宣传视频、校园实景图片等非结构化数据能够为考生提供更加直观的信息,帮助他们更好地了解院校的情况。但目前的研究大多只利用了结构化数据,没有充分挖掘非结构化数据的价值,限制了系统的性能和用户体验。
四、未来发展方向
(一)实时数据采集
结合高校官方API与爬虫技术,实现招生动态的实时更新。通过与高校官方系统的对接,及时获取最新的招生政策和信息,并将其整合到系统中,提高数据的时效性,使预测和推荐结果更加准确。
(二)可解释推荐算法
引入SHAP值或LIME方法,提升算法透明度。通过这些方法,可以解释推荐算法的决策过程,让用户了解推荐结果的依据,增加用户对系统的信任度,提高系统的可用性。
(三)多模态推荐
融合院校宣传视频、校园实景图片等多模态数据,增强用户感知。利用计算机视觉和自然语言处理等技术,对非结构化数据进行分析和处理,提取有价值的信息,并将其与结构化数据相结合,为考生提供更加全面、丰富的院校信息,提升用户体验。
五、结论
基于Python与大模型的考研分数线预测系统与考研院校推荐系统通过整合多源数据、应用先进算法与可视化技术,为考生提供了高效、精准的决策支持。然而,现有研究在数据时效性、算法可解释性与多模态数据融合等方面仍存在不足。未来研究需进一步关注这些问题,以提升系统的实用性与用户体验,为考研学子提供更有力的支持。
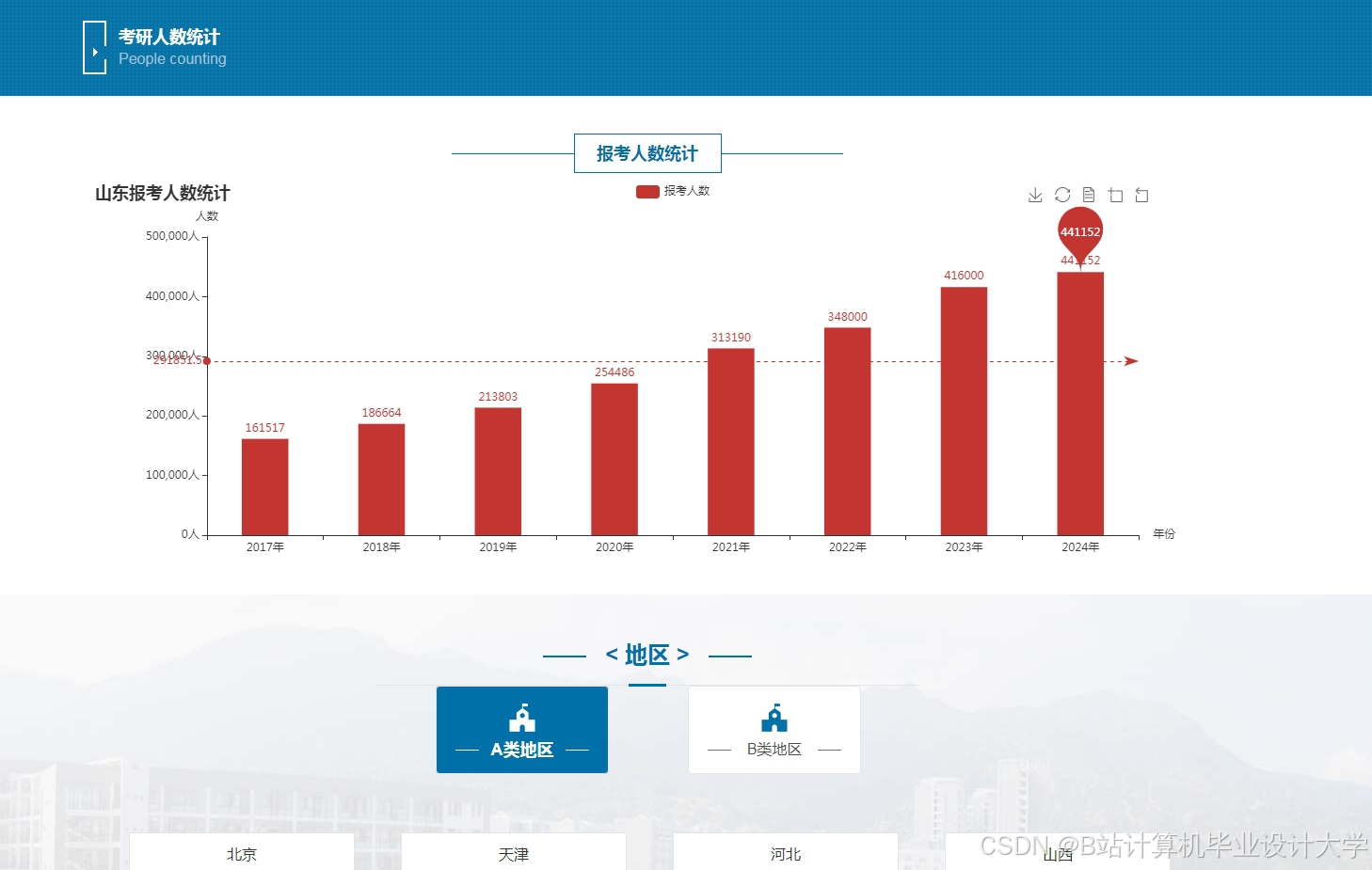
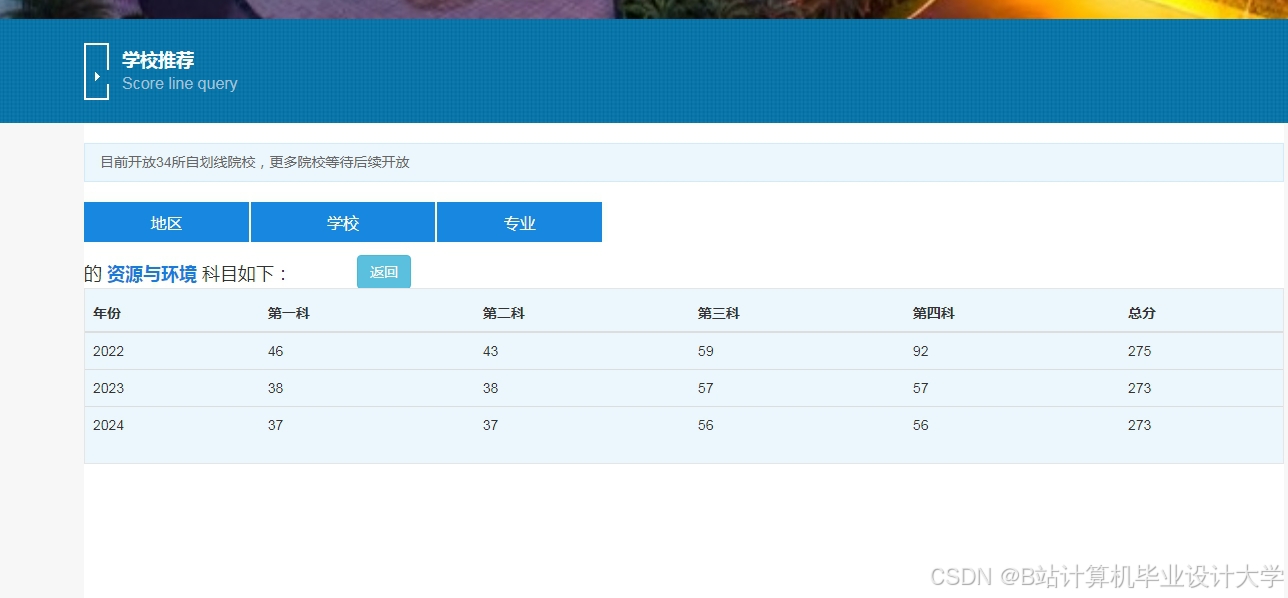
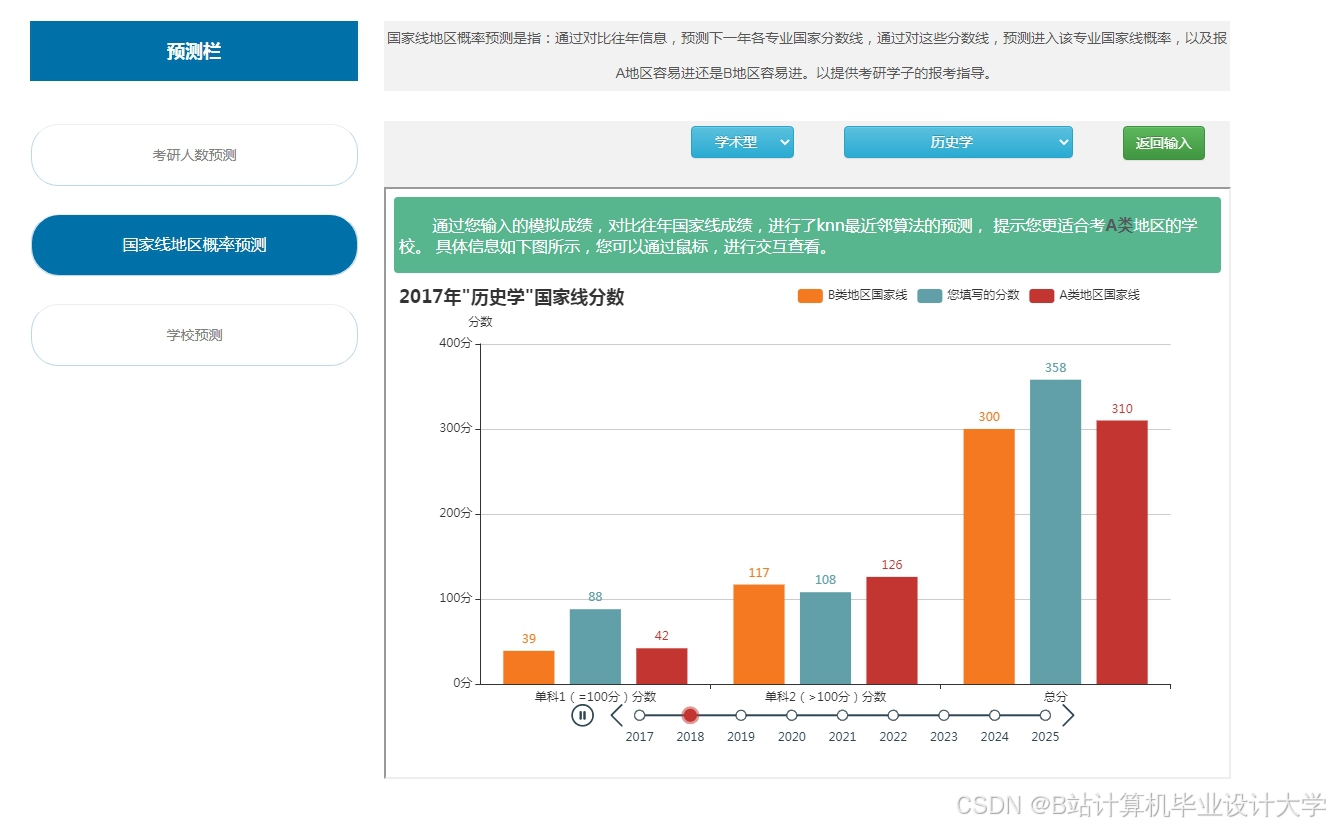
运行截图
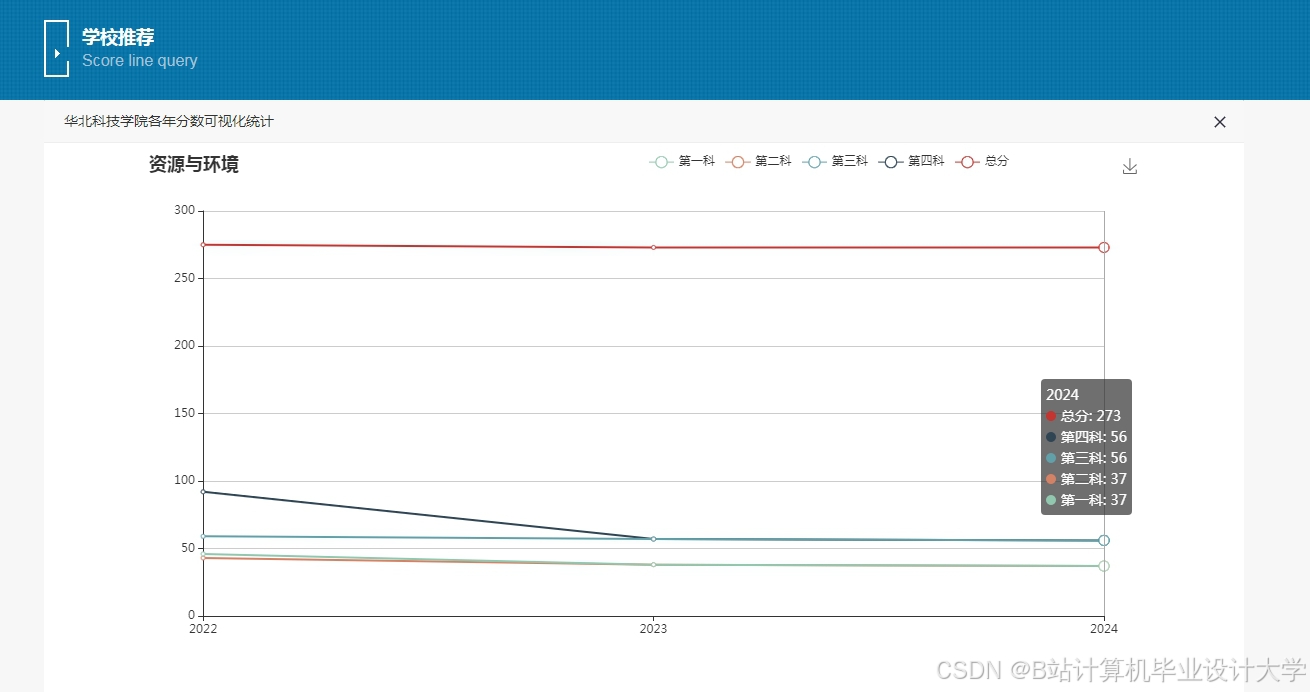
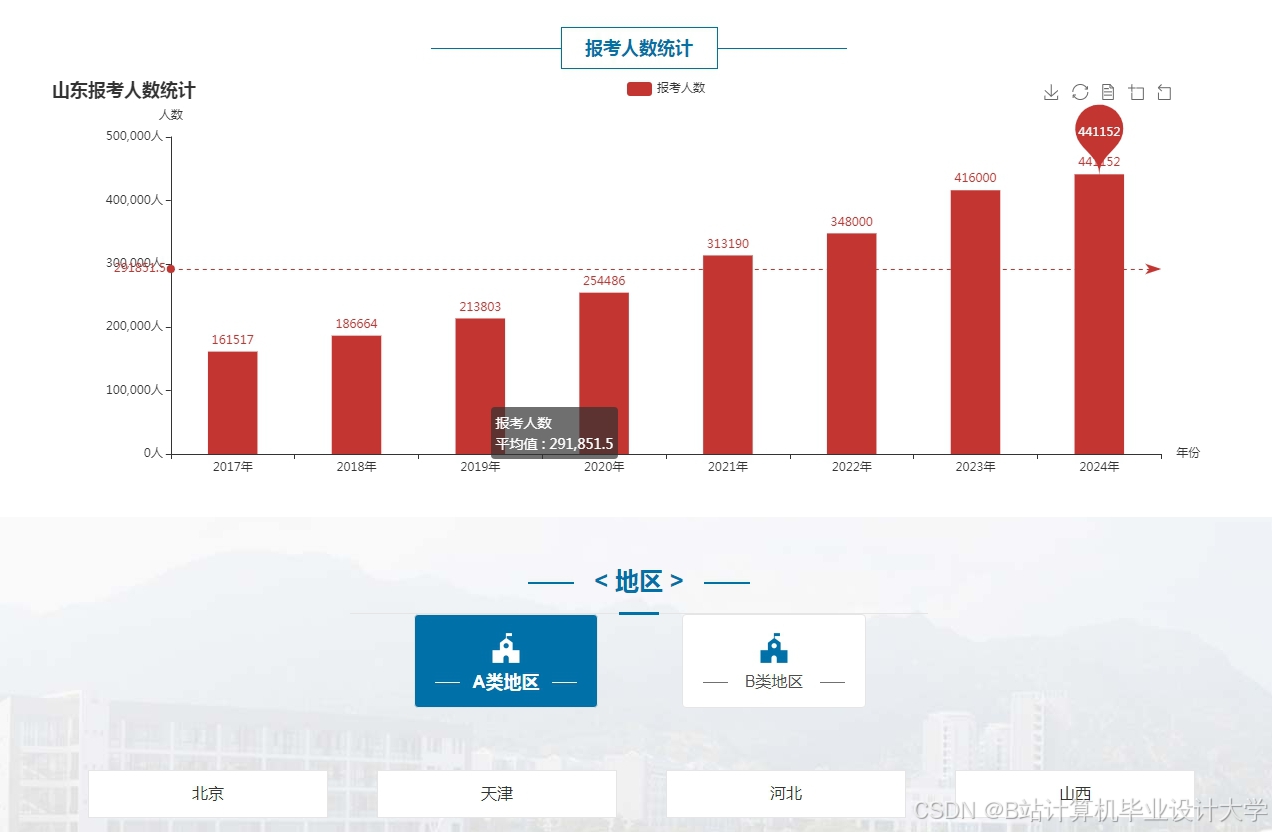
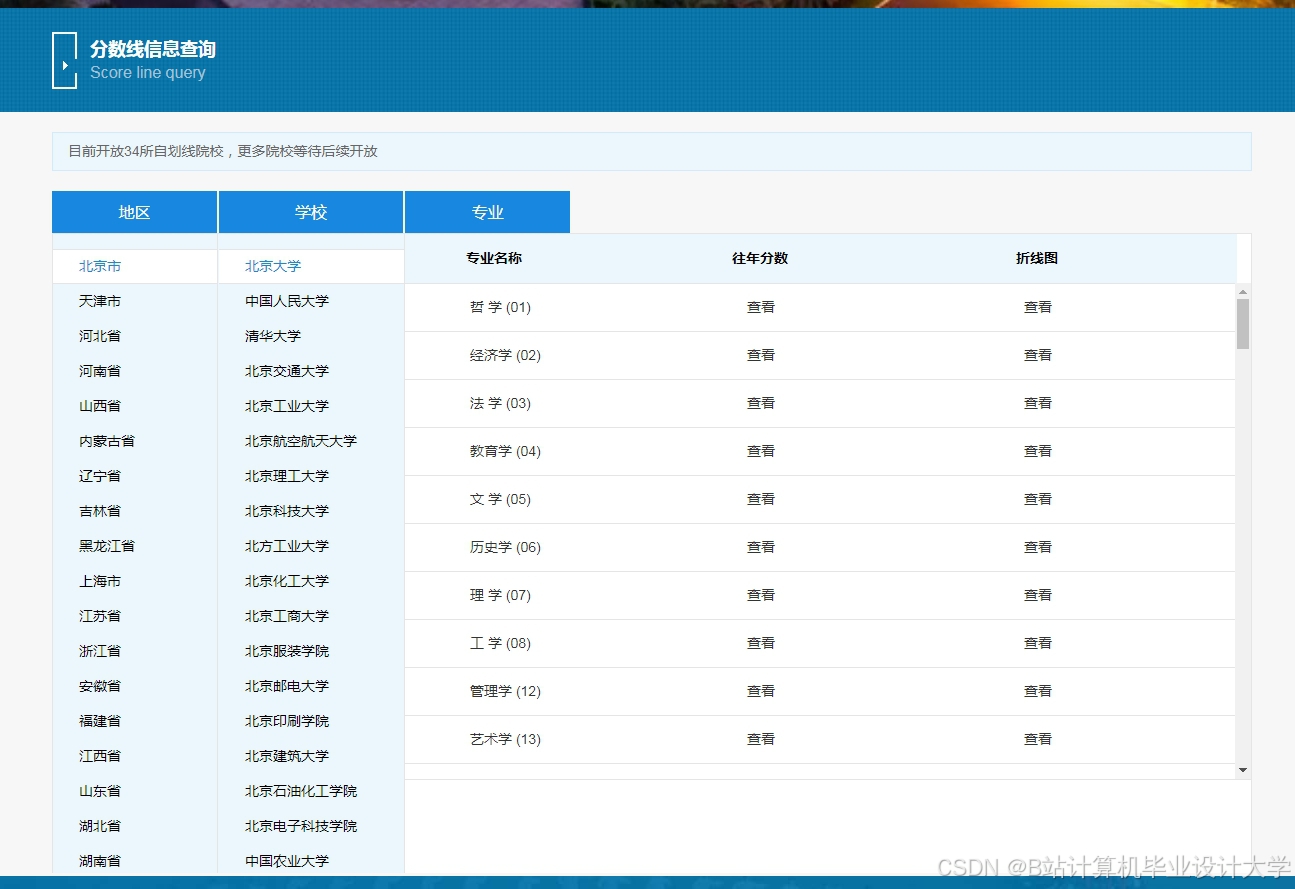
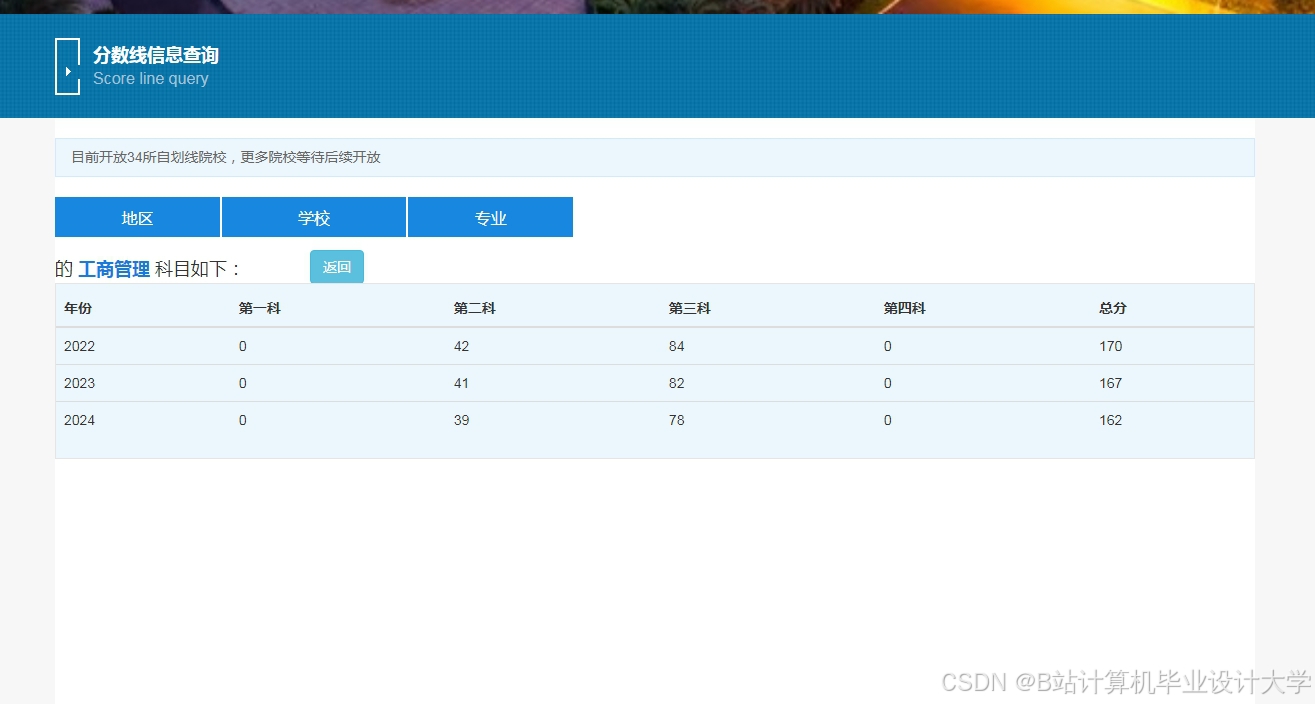
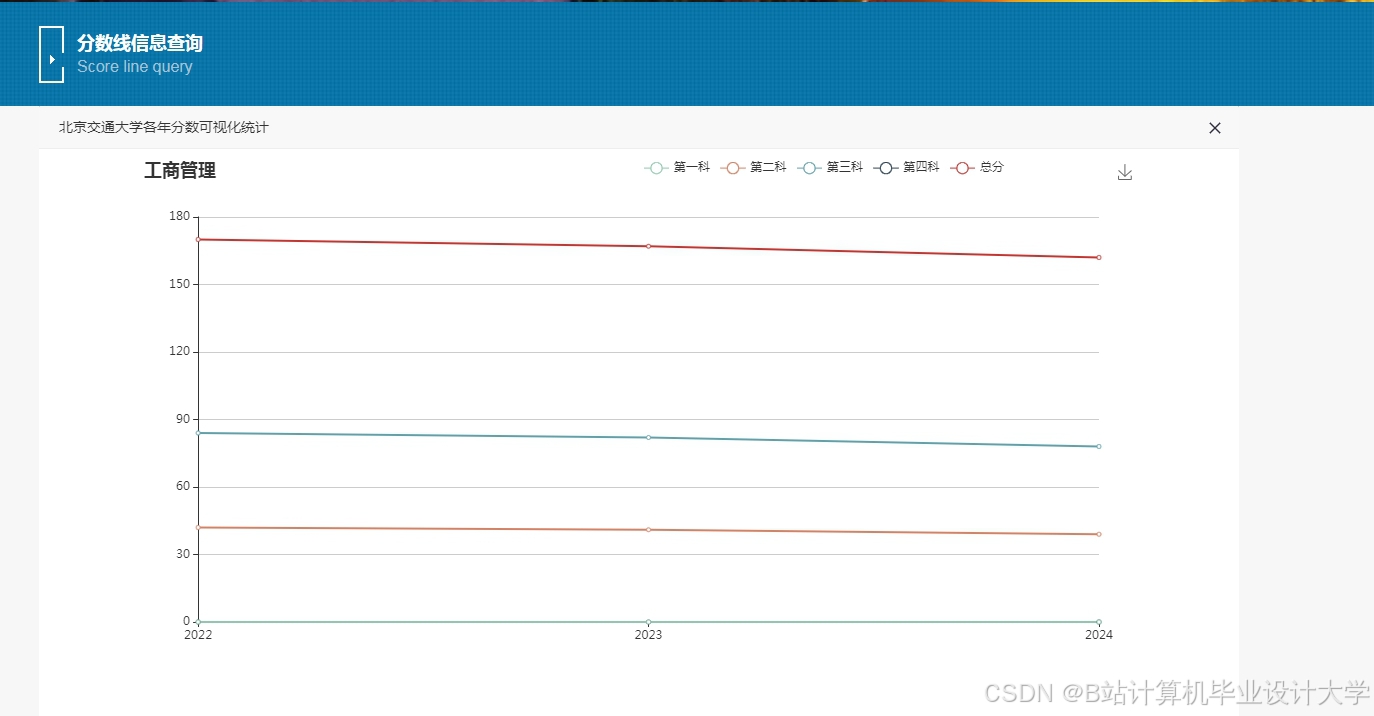
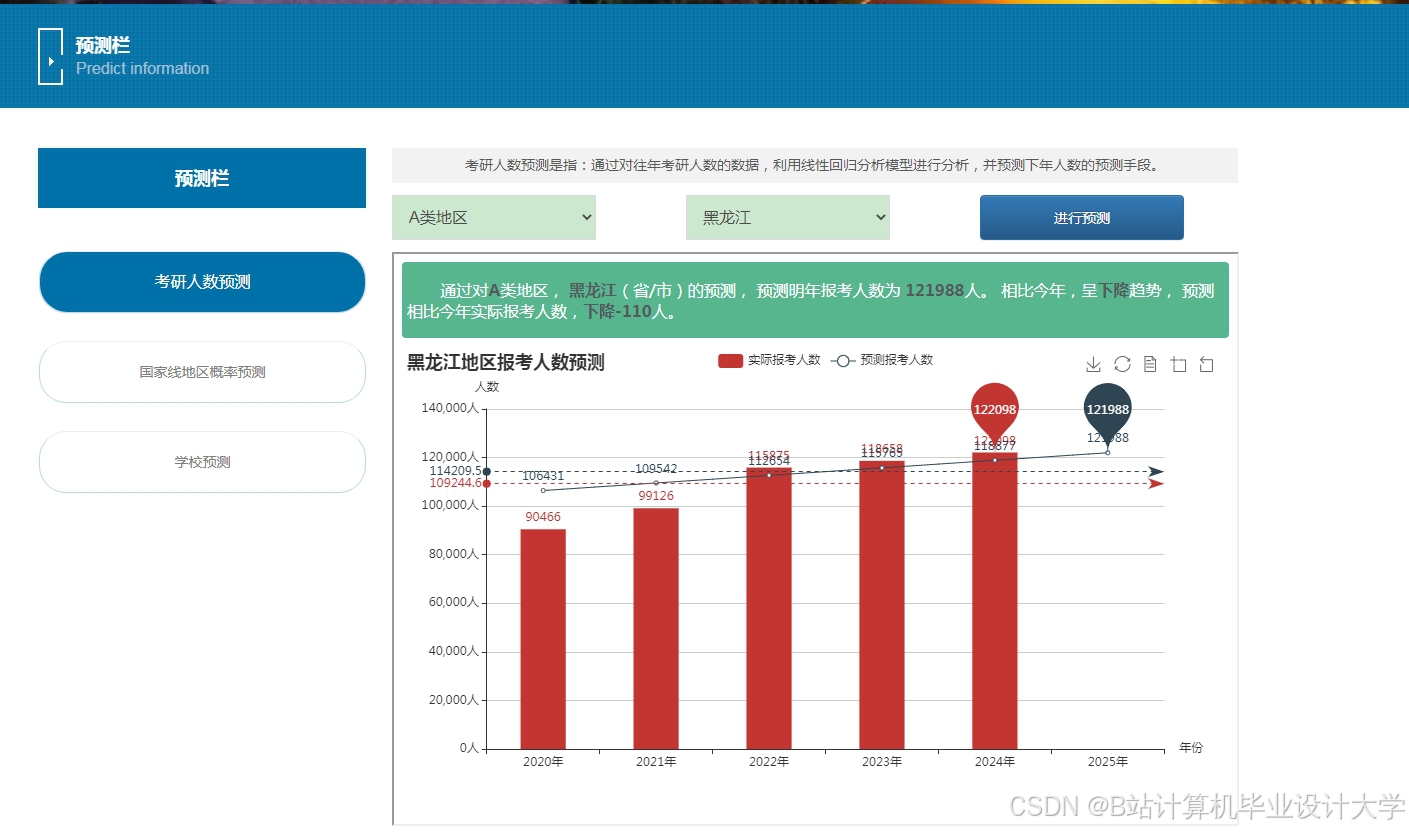
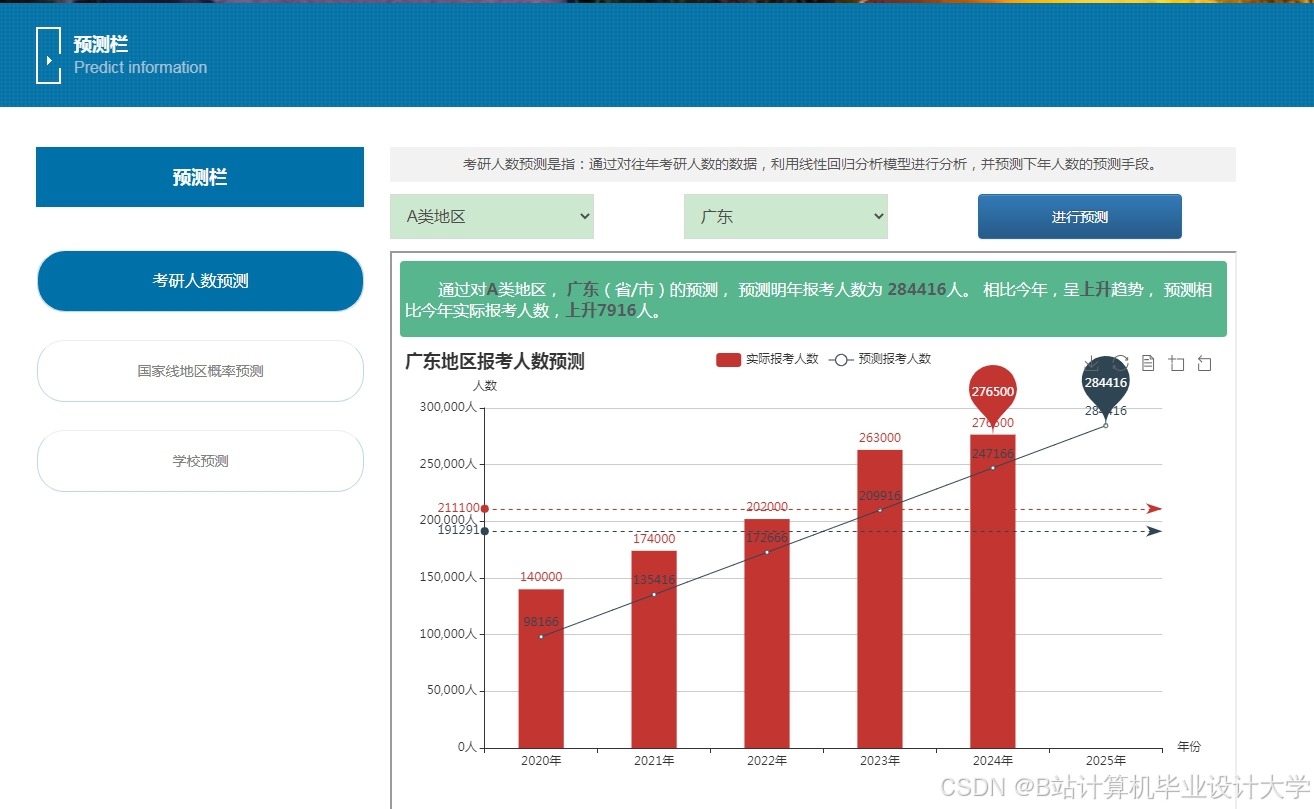
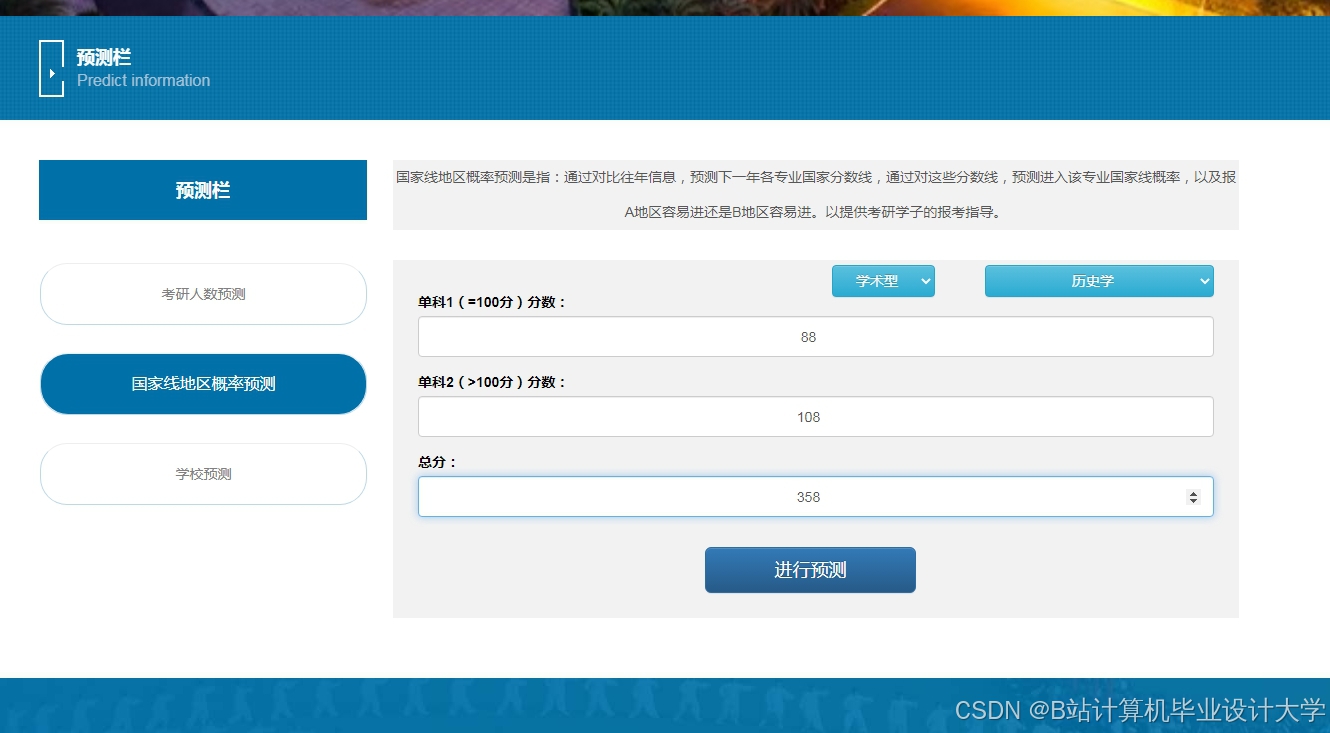
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











