










聊天机器人在AI领域并不稀奇,尤其是ChatGPT问世之后,很多人都把它当成一个可以随时对话随意提问的聊天机器人。而在实际应用领域,聊天机器人的场景也愈加丰富多样。
比如很多人熟知的客服聊天机器人,常用在电商领域,能够快速回答常见问题或者跟踪发货状态等等;还有医疗聊天机器人,在读取患者的症状并且持续提问后,就患者下一步应该采取的措施提出正确的建议;以及还有辅助销售的聊天机器人,用于财务计算、法务咨询相关的聊天机器人等等。
那么,如何拥有一个符合自己场景需求的聊天机器人?语言技术教育家Rachael Tatman博士为使用LLM(Large Language Models)开发聊天机器人提供了一些建议和想法,详细说明了数据扩充的内容、原因和方式。同时还展示了以数据多样性为重点进行数据扩充的建议,以及一些使用Cohere LLM的例子。
使用LLM的建议
首先,出于对用户体验考虑,以及存在的一些不可预测性,Rachael Tatman博士不建议向用户展示原始生成的文本。这是由于,对LLM的大多数对抗性攻击都需要访问原始生成的文本,如果不公布原始数据,那么就不必应对对抗性攻击。她建议在训练或者微调聊天机器人时,可以在人机交互的方面进行数据增强,从而使得用户能够在使用时感受到温暖。
注:对抗性攻击(Adversarial attacks),由于机器学习算法的输入形式是一种数值型向量(Numeric vectors),所以攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击。
数据增强什么时候有用?
数据增强什么时候有用呢,答案是,在没有目标用户的代表性数据的时候。她还指出,在我们有足够完善的代表性数据时,数据扩充当然是有效的,但是会缺乏一些有特殊含义或者其他意图的内容。比如说因为热点事件或者新的含义,某些事物会从不相关变成相关。,此外,在处理一些非常干净且不能完全代表用户生成文本的研究数据时,数据扩充是非常重要的。
为什么使用LLM而不是其他?
与其他基于模板规则的数据扩充技术相比,LLM可以避免重复和意外错误。并且基于模板规则的方法在生成具有不同语法的数据方面存在滞后。Rachael Tatman博士提到,对比其他模型,LLM是一种生成数据更快、更便宜、更可靠的方法。虽然LLM也会被各种各样的用户生成文本而干扰,因此,在训练我们的模型时,多样性的数据增强是非常有必要的。
Cohere是如何收集数据来训练模型的?
Cohere的Generation Large Language Model是在Cohere基础设施团队从网上抓取的Google Books数据集、Common Crawl和其他文本上训练的。Cohere团队筛选出的前十个域名包括:wordpress.com, medium.com, stackexchange.com, tumblr.com, elsevier.com, genius.com, bbc.co.uk, libsyn.com, yahoo.com, nytimes.com。在这个基础上,Cohere LLM使用了各种数据来训练模型,包括干扰数据。
如何使用LLM更快构建聊天机器人?
虽然根据具体情况和实际场景,数据会各不相同,但建议通过尽可能有代表性并且齐全的数据,来进行模拟训练以生成新数据。正如Rachael Tatman博士所介绍的,她使用SLURP数据集[U1] 创建的一个例子。她之所以会使用这些数据,是因为它非常干净而且正式。
再举个例子,当你有一些训练数据时,如何利用这些训练数据来生成更多基于它的数据。在Cohere的AI聊天机器人对话框内,
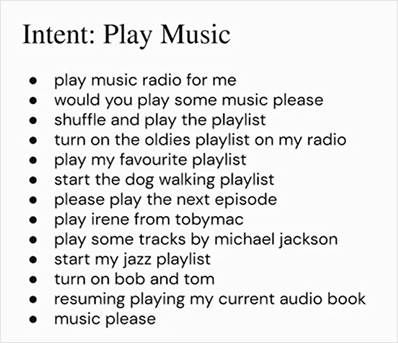
我们给了一个指示:play music有了这个,我们提供了一堆例子。当我们单击生成按钮时,它将生成相关文本。
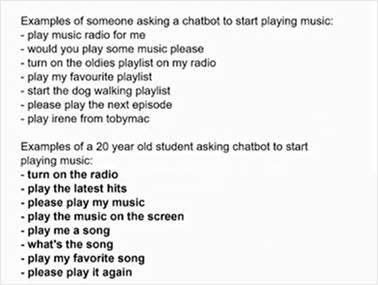
演示了使用Cohere聊天机器人生成文本的另一个示例。在这里,我们给它喂食一个意图,例如,设置闹钟或提醒。

如何为数据增加多样性?
到目前为止,我们已经看到了使用数据增强技术增加数据的方法。但是,生成的数据与现有数据类似。如果我们想增加数据多样性怎么办?她将增加多样性的方法分为两部分。
l 基于情绪或使用角色的提示
基于情绪的提示,也就是喂给一些情绪的提示。 例如,当要求聊天机器人愤怒地播放音乐时,她发现播放音乐的意图发生了变化,聊天机器人生成的文本建议关闭音乐。如下图,聊天机器人给到的文本与可能我们的意图完全相反。所以,情感背景和意图不是IID(独立和相同分布)。然而,这种方法可能适合生成负面情绪的数据集。

l 基于特定用户角色的提示
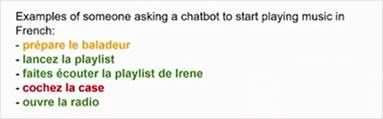
在使用基于用户的特定角色时,它主要基于刻板印象。人们不太可能通过一些人口统计的数据来介绍自己,除非他们想引入一些基于此的刻板印象,比如说“我现在20岁,请播放音乐”“我是法国人,请播放音乐”。但是,使用多语言数据是个特殊情况,有可能就会由数据衍生一些结论,如下图所示。所以,我们应该谨慎地采取这种做法。
l 基于网站人口统计数据的提示
通过引用特定网站进行提示,她提供了一种风险较小的方法来使用社交媒体网站的人口统计数据来创建提示。她提到这种方法可以用作提示中角色的代理,这种方法也考虑了主题的影响。
比如说当引入不同社交网站的数据后,Twitter、Facebook、YouTube上的不同用户,对聊天机器人要求播放音乐,会得到不同的回复。
Facebook:

YouTube:

使用LLM的一些注意事项
在一些场景下,如果和聊天机器人表达的意图过于具体或独特,上述方法将无法很好生效。如果您的目标用户是大量现有社交媒体用户,那么提供的方法将最有效。此外,如果您的目标用户的确是比较独特的,那么可以尝试,以给定方式添加数据多样性,尽管这并不能完全代表您的实际用户,但是算是个权宜之计。
如何验证生成的数据?
建议在第一遍进行手动验证。如果能增肌人机交互的内容将会得到更好的性能。除此之外,她建议使用嵌入可视化来确保整个分布中真实数据和生成的数据的混合。还可以使用嵌入可视化来确定您是否对新集群感到满意。
最后的思考
总结一下,LLM可以帮助我们通过数量和多样性来增加数据,直到我们得到一些实际数据,使我们的系统的可用性更高。她补充说,我们可以提示现有和新生成的数据。最后,建议在第一遍手动验证生成的数据,以确保它符合我们正在寻找的标准和质量。
[U1]https://arxiv.org/abs/2011.13205?ref=txt.cohere.com















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









