






机器学习:机器学习是一类算法的总称,其目标是为了从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类。具体的来说,机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果。机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。学到的函数适用于新样本的能力,称为泛化能力。
机器学习的一些基本概念:属性/特征:事件在某方面的表现或性质。
训练:从数据中学的模型的过程。(训练数据、训练样本、训练集)
测试:使用学的模型进行预测的过程。(测试样本)
标记/标签:关于示例结果的信息。
分类和回归:预测的是离散值的学习任务称为分类,预测连续值为回归。
泛化能力:学得模型适用于新样本的能力。一般训练样本越多,越有可能通过学习获得具有强泛化能力的模型。
参数估计:根据从总体中抽取的样本估计总体分布中包含的未知参数的方法。
机器学习分类:
任务类型分类:回归模型、分类模型、结构化学习模型
方法角度:线性模型、非线性模型
学习理论分类:有监督学习、半监督学习、无监督学习、迁移学习和强化学习 有监督学习:训练样本有标签;半监督学习:部分有标签,部分无标签;迁移学习是把已经训练好的模型参数迁移到新的模型上以帮助新模型训练。强化学习是一个学习最优策略,可以让本体在特定环境中,根据当前状态,做出行动,从而获得最大回报。强化学习和有监督学习最大的不同是,每次的决定没有对与错,而是希望获得最多的累计奖励。
机器学习步骤:
1.收集数据:数据中蕴含模型所要“学习”的知识,因此数据至关重要,搜集数据的质量和数量都将决定最终模型的性能好坏。实际处理中,数据大都存在着问题,不能直接使用,需要对数据进行清洗,数据的清洗主要要空值处理、异常值处理、数据标准化(min-max标准化,Z-score标准化)
2.模型选择:算法的效果不能脱离实际问题,在某些问题上表现好的算法,在另一个问题上的表现可能不是很好。每个算法有其固定的特点,有相匹配的应用场景。模型选择包含两层含义,一层含义是指机器学习算法众多,对于同一个问题,从多种算法中进行选择;另外一层含义是对于同一种算法来说,设置不同的参数后,算法效果可能发生很大变化,甚至会变成不同的模型。
3.模型训练与测试:模型在运用之前,需要测定模型的准确程度。因此建立模型需要两个数据集———训练用数据集(测试集)和测试用数据集(训练集)。验证集:是模型训练单独留出的样本集,可以用于调整模型的参数和用于对模型的能力进行初步评估。一般在训练集中单独划分出一块作为验证集,使用验证集能减少过拟和。
4.模型性能评估:对于模型评价有很多方法,常用的指标如准确率、错误率、精准率、召回率、roc曲线、ks曲线等
用e代表错误率,计算方式:e=分类错误的样本数/样本总数
精确率(p)=正确识别的个体总数/识别的个体总数
召回率(r)=正确识别的个体总数/测试集存在的个体总数


ks曲线:量化评估模型区分度 KS=max(TPR-FPR) 通常KS大于0.3。
ks值含义:ks小于0.2,一般认为模型的区分能力较弱;
ks值在0.2到0.3之间,模型有一定的区分能力;
ks值在0.3到0.5内,模型具有较高的区分能力。
如果ks过大,往往表示模型有异常。
过拟合和欠拟合:
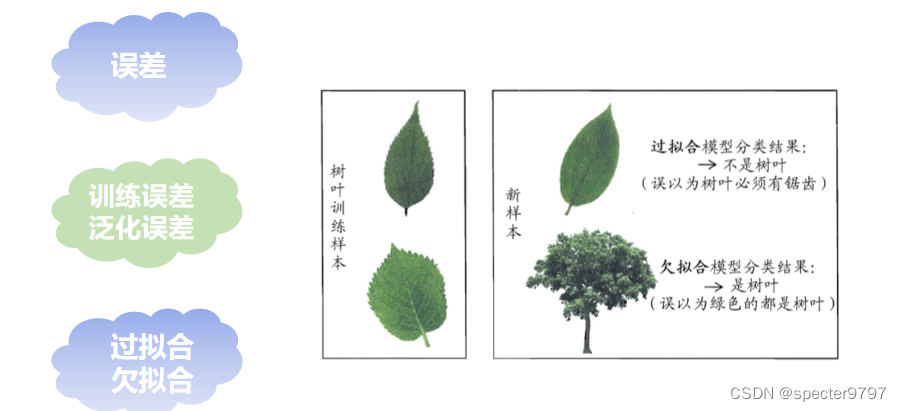
欠拟合和过拟合产生原因及解决办法 :
欠拟合
定义:模型在训练集上的误差较高。
产生原因:模型过于简单,没有很好的捕捉到数据特征,不能很好的拟合数据。
解决办法:模型复杂化、增加更多的特征,使输入数据具有更强的表达能力等。
过拟合
定义:在训练集上误差低,测试集上误差高。
产生原因:模型把数据学习的太彻底,以至于把噪声数据的特征也学习到,这样就会导致在后期测试的时候不能够很好地识别数据,模型泛化能力太差。
解决办法:降维、增加训练数据、正则约束等。
特征工程:到手的数据不太可能直接拿来使用,这便需要对数据进行处理。
非数值类型处理: 1.Get_dummies哑变量处理 2.Label Encoding编号处理 (replace()函数)转化为数值型数据。
特征值筛选:woe值与iv值


iv值:iv值越高,说明该特征变量越具有区分度,也并不是iv值越大越好。
XGBoost算法:XGBoost核心算法原理详解_野犬1998的博客-CSDN博客_xgboost算法
LightGBM算法原理:采用损失函数负梯度作为当前决策树的残差近似值,去拟合新的决策树。该算法与传统的机器学习算法具有的优势是:训练效率更高,低内存使用,可以处理大规模数据。
孤立森林算法:简书 (该算法论文)















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









