







神经元模型
神经元(M-P)的结构
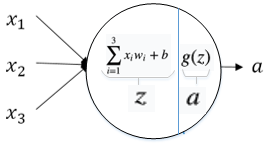
代表输入,
代表权重,b代表偏置,
代表非线性激活函数。
叫做带权输入,
叫做激活值,是神经元的输出。
在M-P模型中,神经元接受其他n个神经元的输入信号(0或1),这些输入信号经过权重加权并求和,将求和结果与阈值(threshold) θ 比较,然后经过激活函数处理,得到神经元的输出。
神经网络的结构
人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。
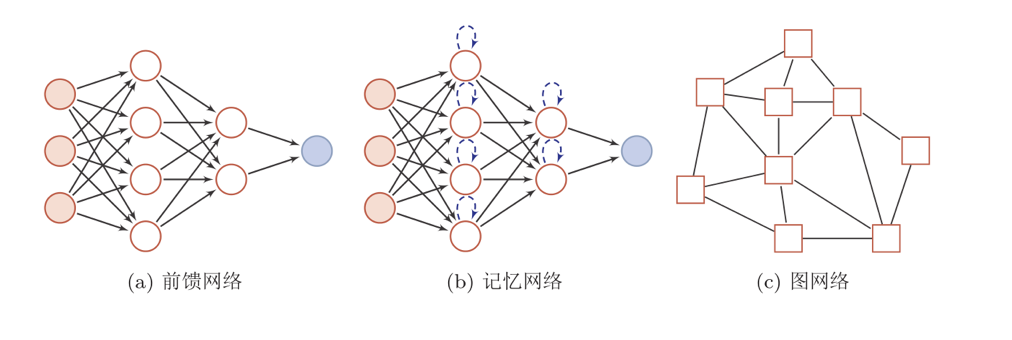
其中圆形节点表示一个神经元,方形节点表示一组神经元。
感知器
单层感知器
与 M-P 模型需 要人为确定参数不同,感知器能够通过训练自动确定参数。训练方式为有监督学习,即需要设定训练样本和期望输出,然后调整实际输出和期望输出之差的方式(误差修正学习)。
其中, 是学习率,
和
分别是期望输出和实际输出。
感知器权重调整的基本思路:
- 实际输出
与期望输出
相等时,
和
不变
- 实际输出
| 未激活 | 激活过度 |
| 实际输出 | 实际输出 |
| 减小 增大
| 增大 降低
|
感知器模型的训练过程:

多层感知器
单层感知器只能解决线性可分问题,多层感知机可以解决线性不可分问题
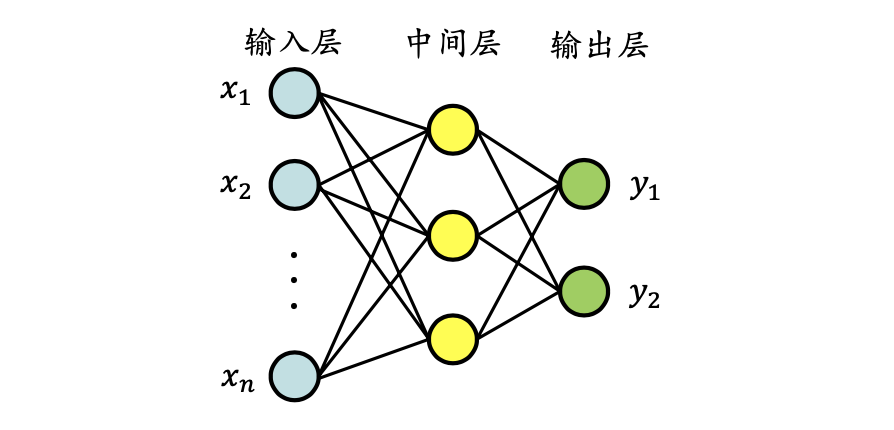
多层感知器指的是由多层结构的感知器递阶组成的输入值向前传播的网络,也被称为前馈网络或正向传播网络。
以三层结构的多层感知器为例,它由输入层、中间层及输出层组成
- 与M-P模型相同,中间层的感知器通过权重与输入层的各单元相连接,通过阈值函数计算中间层各单元的输出值
- 中间层与输出层之间同样是通过权重相连接
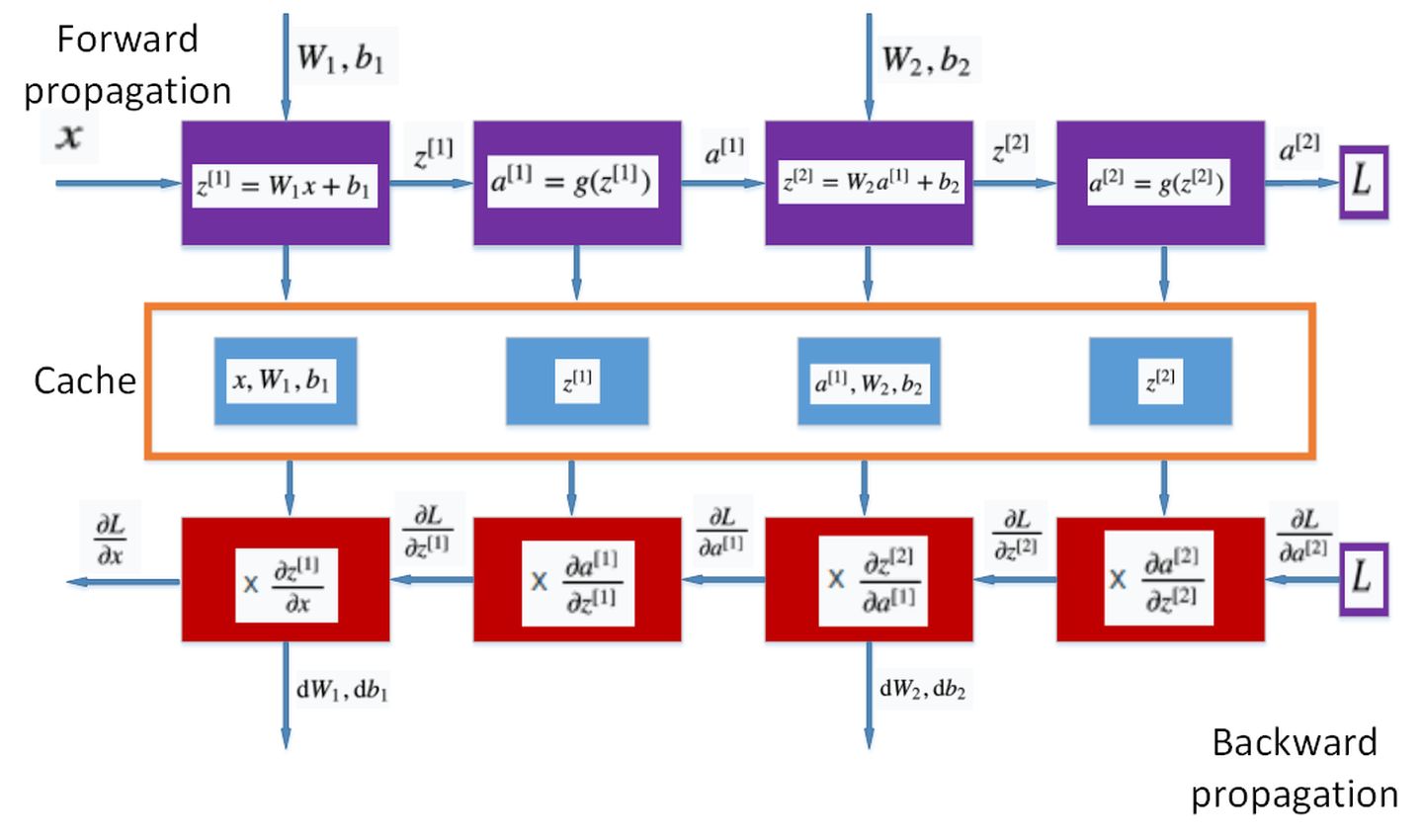
BP算法
多层感知器的训练使用误差反向传播算法(Error Back Propagation),即BP算法。
BP算法的基本过程
- 前向传播计算:由输入层经过隐含层向输出层的计算网络输出
- 误差反向逐层传递:网络的期望输出与实际输出之差的误差信号由输出层经过隐含层逐层向输入层传递
- 由“前向传播计算”与“误差反向逐层传递”的反复进行的网络训练 过程
BP算法就是通过比较实际输出和期望输出得到误差信号,把误差信号从输出层逐层向前传播得到各层的误差信号,再通过调整各层的连接权重以减小误差。权重的调整主要使用梯度下降法:
激活函数
为什么需要非线性激活函数?
如果没有非线性激活函数,得到的输出仅仅是输入的线性组合。这样多层的神经网络的模型复杂度就和单层神经网络一样了。
常见的激活函数:Sigmoid函数、ReLu(Rectified Linear Unit 修正线性单元)和tanh
sigmoid函数

Sigmoid函数的导数:
sigmoid函数在u接近0或者1时,函数的导数很小(接近0),会使模型收敛速度变慢。
我们一般不使用sigmoid函数,只在以下两种情况时使用:
- 二分类的时候,输出层使用
- 需要输出值在0到1之间,输出层使用
tanh函数

tanh函数和sigmoid函数的关系:
tanh函数的导数:
tanh几乎在任何情况下效果都比sigmoid要好。tanh函数的值在-1和1之间,输出的结果的平均值为0。tanh函数和sigmoid函数的共同缺点是在z接近无穷大或无穷小时,这两个函数的导数也就是梯度变得非常小,此时梯度下降的速度也会变得非常慢。
ReLU函数

ReLU函数是非线性激活函数的默认选择,如果你不知道该选择哪个激活函数,ReLU很可能是个好的选择。
BP算法示例
具体实现流程:
(涉及复合函数求导,具体求导过程有点懵……结果见下图)
中间层到输出层
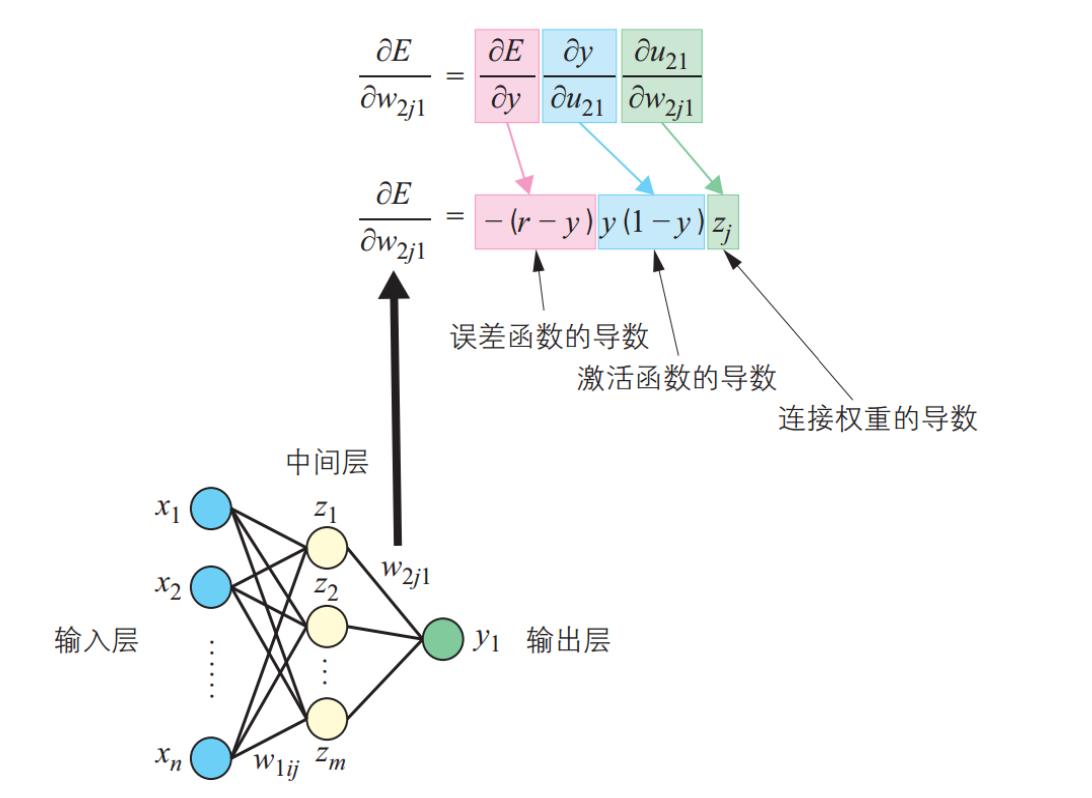
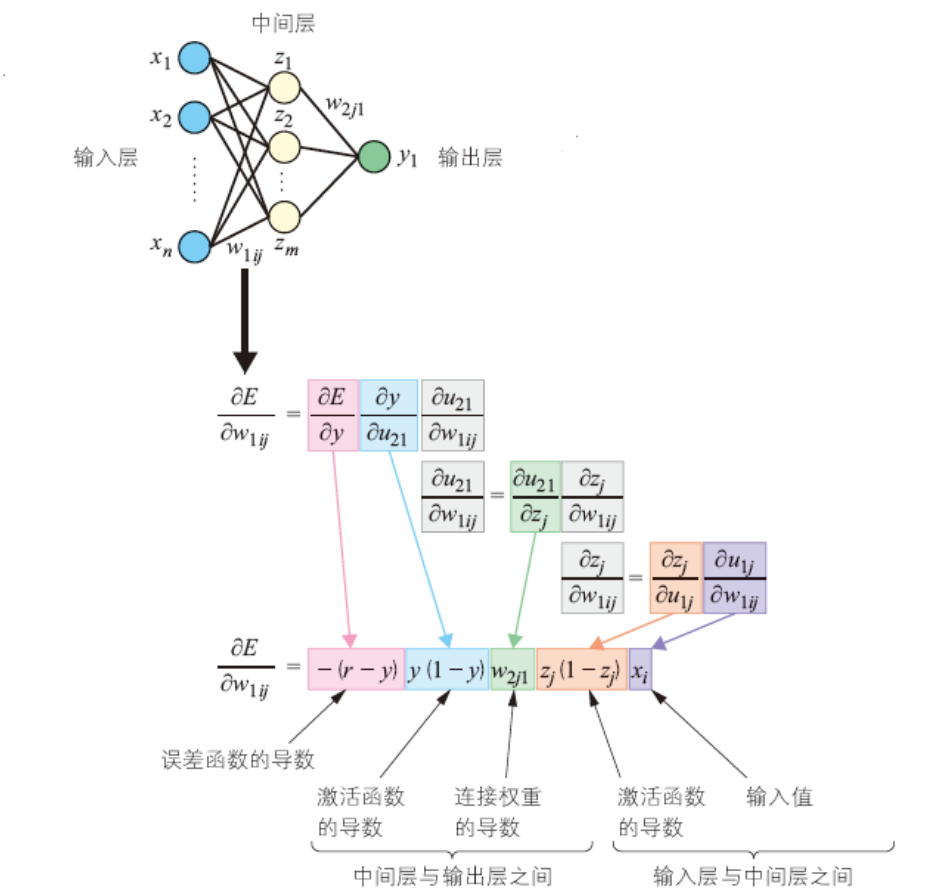
输入层到中间层
优化问题
难点
- 参数过多,影响训练
- 非凸优化问题:即存在局部最优而非全局最优解,影响迭代
- 梯度消失问题,下层参数比较难调
- 参数解释起来比较困难
需求
- 计算资源要大
- 数据要多
- 算法效率要好:即收敛快














 9975
9975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









