转自http://blog.csdn.net/pirage/article/details/53424544
分词原理
本小节内容参考待字闺中的两篇博文:
- 97.5%准确率的深度学习中文分词(字嵌入+Bi-LSTM+CRF)
- 如何深度理解Koth的深度分词?
简单的说,kcws的分词原理就是:
- 对语料进行处理,使用word2vec对语料的字进行嵌入,每个字特征为50维。
- 得到字嵌入后,用字嵌入特征喂给双向LSTM, 对输出的隐层加一个线性层,然后加一个CRF就得到本文实现的模型。
- 于最优化方法,文本语言模型类的貌似Adam效果更好, 对于分类之类的,貌似AdaDelta效果更好。
另外,字符嵌入的表示可以是纯预训练的,但也可以在训练模型的时候再fine-tune,一般而言后者效果更好。对于fine-tune的情形,可以在字符嵌入后,输入双向LSTM之前加入dropout进一步提升模型效果。
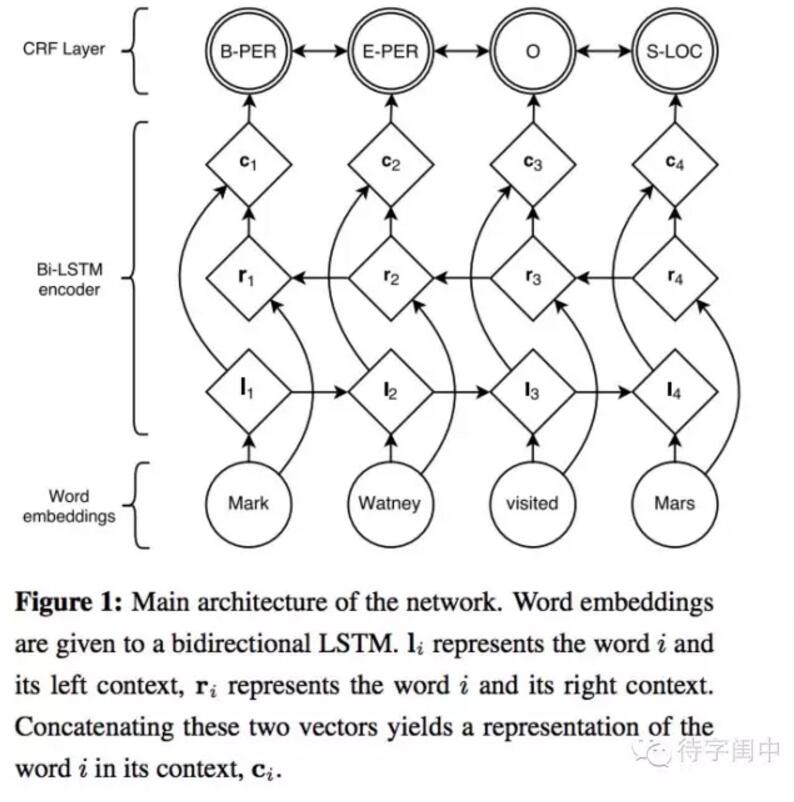
具体的解决方案,基于双向LSTM与CRF的神经网络结构:
如上图所示,单层圆圈代表的word embedding输入层,菱形代表学习输入的决定性方程,双层圆圈代表随机变量。信息流将输入层的word embedding送到双向LSTM, l(i)代表word(i)和从左边传入的历史信号,r(i)代表word(i)以及从右边传入的未来的信号,用c(i)连接这两个向量的信息,代表词word(i)。
先说Bi-LSTM这个双向模型,LSTM的变种有很多,基本流程都是一样的,文献中同样采用上一节说明的三个门,控制送入memory cell的输入信息,以及遗忘之前阶段信息的比例,再对细胞状态进行更新,最后用tanh方程对更新后的细胞状态再做处理,与sigmoid叠加相乘作为最终输出。具体的模型公式见下图,经过上一节的解释,这些符号应该不太陌生了。
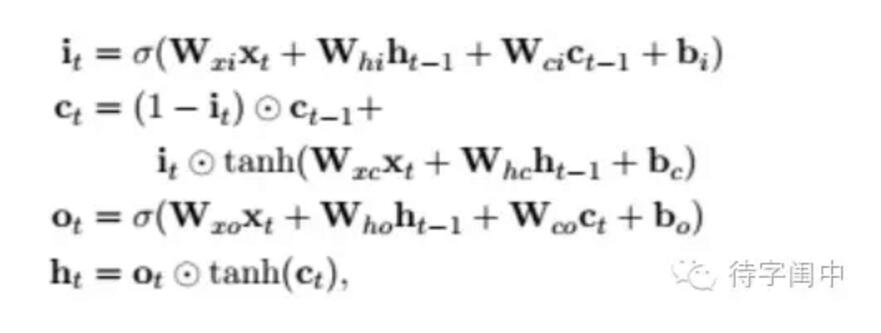
双向LSTM说白了,就是先从左至右,顺序学习输入词序列的历史信息,再从右至左,学习输入词序列未来影响现在的信息,结合这两种方式的最终表示有效地描述了词的内容,在多种标注应用上取得了好效果。
如果说双向LSTM并不特殊,这个结构中另一个新的尝试,就是将深度神经网络最后学出来的结果,作为特征,用CRF模型连接起来,用P来表示双向LSTM神经网络学习出来的打分输出矩阵,它是一个 nxk 的矩阵,n是输入词序列个数,k是标记类型的数目, P(ij)指的是在一个输入句子中,第i个词在第j个tag标记上的可能性(打分)。另外一个特征函数是状态转移矩阵 A,A(ij) 代表从tag i转移到tag j的可能性(打分),但这个转移矩阵实际上有k+2维,其中包括句子的开始和结束两个状态,用公式表示如下图:
s(X,y)=∑i=0nAyi,yi+1+∑i=1nPi,yi
在给定输入序列X,最终定义的输出y序列的概率,则使用softmax函数表示如下:
p(y|X)=es(X,y)∑y˘∈YXes(X,y˘)
而在训练学习目标函数的时候,要优化的就是下面这个预测输出标记序列的log概率,其中 Y(X)代表的是所有可能的tag标记序列集合,那么最后学习得到的输出,就是概率最大的那个标记序列。如果只是模拟输出的bigram交互影响方式,采用动态规划即可求解下列方程。
log(p(y|X))=s(X,y)−log(∑y˘∈YXes(X,y˘))
=s(X,y)−logaddy˘∈YXs(X,y˘)
y∗=argmaxy˘∈YXs(X,y˘)
至此,基于双向LSTM与CRF的神经网络结构已经介绍完毕,文献中介绍的是在命名实体识别方面的一个实践应用,这个思路同样可以用在分词上。具体的实践和调参,也得应场景而异,Koth在上一篇博客中已经给出了自己的践行,读者们可以借鉴参考。
代码结构与实践
koth大神开源的项目地址为:https://github.com/koth/kcws
主要的代码在目录kcws/kcws/train路径下。(写这篇文章的时候发现K大神做了更新,我主要还是分析之前的代码)
- process_anno_file.py 将人民网2014训练语料进行单字切割,包括标点符号
- generate_training.py 生成单字的vector之后,处理每篇训练语料,以“。”划分为句子,对每个句子,如果长度大于MAX_LEN(默认设置为80,在代码里改),不处理,Long lines加一,如果长度小于MAX_LEN,则生成长度为160的vector,前80为单字在字典中的index,不足80的补0,后80为每个字对应的SBME标记(S表示单字,B表示开始,M表示中间,E表示结尾)。
- filter_sentence.py 将语料切分为训练集和测试集,作者将含有两个字以下的句子过滤掉,剩下的按照二八分,测试集最多8000篇。
- train_cws_lstm.py 主要训练代码。
作者在项目主页上很详细的写了构建和训练的步骤,按照这些步骤来实践一下不算难,我主要遇到了以下几个问题:
- 之前安装tensorflow的时候没有用bazel,不了解bazel的工作方式和原理,但是这个项目必须要用,因为需要用到third_party中word2vec的类。(可以将word2vec的某些类构建为python可以import的类?)
- 已安装的0.8.0版本的tensorflow没有实现crf,需要升级。
- 安装tensorflow 0.11.0版本后运行,出现PyUnicodeUCS4_AsUTF8String的错误,查找后发现是当前安装的python默认是unicode=ucs2,需要重新编译安装python。编译的时候设置./configure –enable-unicode=ucs4 。
- numpy,scipy都需要重新build,setup。
主要代码分析
def main(unused_argv):
curdir = os.path.dirname(os.path.realpath(__file__))
trainDataPath = tf.app.flags.FLAGS.train_data_path
if not trainDataPath.startswith("/"):
trainDataPath = curdir + "/" + trainDataPath
graph = tf.Graph()
with graph.as_default():
model = Model(FLAGS.embedding_size, FLAGS.num_tags,
FLAGS.word2vec_path, FLAGS.num_hidden)
print("train data path:", trainDataPath)
X, Y = inputs(trainDataPath)
tX, tY = do_load_data(tf.app.flags.FLAGS.test_data_path)
total_loss = model.loss(X, Y)
train_op = train(total_loss)
test_unary_score, test_sequence_length = model.test_unary_score()
sv = tf.train.Supervisor(graph=graph, logdir=FLAGS.log_dir)
with sv.managed_session(master='') as sess:
training_steps = FLAGS.train_steps
for step in range(training_steps):
if sv.should_stop():
break
try:
_, trainsMatrix = sess.run(
[train_op, model.transition_params])
if step % 100 == 0:
print("[%d] loss: [%r]" % (step, sess.run(total_loss)))
if step % 1000 == 0:
test_evaluate(sess, test_unary_score,
test_sequence_length, trainsMatrix,
model.inp, tX, tY)
except KeyboardInterrupt, e:
sv.saver.save(sess,
FLAGS.log_dir + '/model',
global_step=step + 1)
raise e
sv.saver.save(sess, FLAGS.log_dir + '/finnal-model')
sess.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
Class Model:
def __init__(self, embeddingSize, distinctTagNum, c2vPath, numHidden):
self.embeddingSize = embeddingSize
self.distinctTagNum = distinctTagNum
self.numHidden = numHidden
self.c2v = self.load_w2v(c2vPath)
self.words = tf.Variable(self.c2v, name="words")
with tf.variable_scope('Softmax') as scope:
self.W = tf.get_variable(
shape=[numHidden * 2, distinctTagNum],
initializer=tf.truncated_normal_initializer(stddev=0.01),
name="weights",
regularizer=tf.contrib.layers.l2_regularizer(0.001))
self.b = tf.Variable(tf.zeros([distinctTagNum], name="bias"))
self.trains_params = None
self.inp = tf.placeholder(tf.int32,
shape=[None, FLAGS.max_sentence_len],
name="input_placeholder")
pass
def length(self, data):
used = tf.sign(tf.reduce_max(tf.abs(data), reduction_indices=2))
length = tf.reduce_sum(used, reduction_indices=1)
length = tf.cast(length, tf.int32)
return length
def inference(self, X, reuse=None, trainMode=True):
word_vectors = tf.nn.embedding_lookup(self.words, X)
length = self.length(word_vectors)
length_64 = tf.cast(length, tf.int64)
if trainMode:
word_vectors = tf.nn.dropout(word_vectors, 0.5)
with tf.variable_scope("rnn_fwbw", reuse=reuse) as scope:
forward_output, _ = tf.nn.dynamic_rnn(
tf.nn.rnn_cell.LSTMCell(self.numHidden),
word_vectors,
dtype=tf.float32,
sequence_length=length,
scope="RNN_forward")
backward_output_, _ = tf.nn.dynamic_rnn(
tf.nn.rnn_cell.LSTMCell(self.numHidden),
inputs=tf.reverse_sequence(word_vectors,
length_64,
seq_dim=1),
dtype=tf.float32,
sequence_length=length,
scope="RNN_backword")
backward_output = tf.reverse_sequence(backward_output_,
length_64,
seq_dim=1)
output = tf.concat(2, [forward_output, backward_output])
output = tf.reshape(output, [-1, self.numHidden * 2])
matricized_unary_scores = tf.batch_matmul(output, self.W)
unary_scores = tf.reshape(
matricized_unary_scores,
[-1, FLAGS.max_sentence_len, self.distinctTagNum])
return unary_scores, length
def loss(self, X, Y):
P, sequence_length = self.inference(X)
log_likelihood, self.transition_params = tf.contrib.crf.crf_log_likelihood(
P, Y, sequence_length)
loss = tf.reduce_mean(-log_likelihood)
return loss
def load_w2v(self, path):
fp = open(path, "r")
print("load data from:", path)
line = fp.readline().strip()
ss = line.split(" ")
total = int(ss[0])
dim = int(ss[1])
assert (dim == (FLAGS.embedding_size))
ws = []
mv = [0 for i in range(dim)]
ws.append([0 for i in range(dim)])
for t in range(total):
line = fp.readline().strip()
ss = line.split(" ")
assert (len(ss) == (dim + 1))
vals = []
for i in range(1, dim + 1):
fv = float(ss[i])
mv[i - 1] += fv
vals.append(fv)
ws.append(vals)
for i in range(dim):
mv[i] = mv[i] / total
ws.append(mv)
fp.close()
return np.asarray(ws, dtype=np.float32)
def test_unary_score(self):
P, sequence_length = self.inference(self.inp,
reuse=True,
trainMode=False)
return P, sequence_length
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
其他的代码比较简单,个人觉得不必要做深入分析。























 3720
3720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









