






Linear函数详解
Linear函数基本定义:
torh.nn.Linear定义一个神经网络的线性层,它的方法如下:
torch.nn.Linear(in_features, # 输入的神经元个数
out_features, # 输出神经元个数
bias=True # 是否包含偏置
)
实际上,他进行的是y_pre=w*x+b的线性变换,从而得到预测值y_pre。
例子
print("--------Linear函数--------")
import torch
lp=torch.nn.Linear(2,3)
print("输出线性函数权重w值:",lp.weight)
print("输出线性函数权重w形状:",lp.weight.shape)
print()
print("输出线性函数偏置b值:",lp.bias)
print("输出线性函数偏置b形状:",lp.bias.shape)
print()
data=torch.Tensor([[1.0,1.0]])
print("测试数据:",data)
print("测试数据形状:",data.shape)
print()
out1=lp(data)
print("输出线性函数自动计算结果:",out1)
out2=data.matmul(lp.weight.T)+lp.bias
print("输出线性函数手工计算结果:",out2)首先,我们先定义一个Linear函数,输入层为2个神经元,而输出层为3个神经元。
接着,我们分别输出权重和偏置,即w和b的值和形状,这里的值都是随机生成的。
在输出x.shape时,Linear函数会自动进行转置,变为(out_features,in_features),即由原来的两行三列自动转为三行两列。
这里,bias即b的形状为3,即(out_features)
生成一个Tensor类型的数据data来观察Linear函数的准确性
利用out1来看自动计算的结果
data.matmul(lp.weight.T)+lp.bias,data乘最初始的w,即转置后的w,再加上bias,得到手动计算结果out2
--------Linear函数--------
输出线性函数权重w值: Parameter containing:
tensor([[-0.2108, 0.1091],
[ 0.0212, 0.0785],
[-0.6126, 0.6920]], requires_grad=True)
输出线性函数权重w形状: torch.Size([3, 2])
输出线性函数偏置b值: Parameter containing:
tensor([-0.5013, 0.1634, 0.1016], requires_grad=True)
输出线性函数偏置b形状: torch.Size([3])
测试数据: tensor([[1., 1.]])
测试数据形状: torch.Size([1, 2])
输出线性函数自动计算结果: tensor([[-0.6030, 0.2631, 0.1810]], grad_fn=<AddmmBackward0>)
输出线性函数手工计算结果: tensor([[-0.6030, 0.2631, 0.1810]], grad_fn=<AddBackward0>)最终我们发现,自动计算结果和手动计算结果相同。
通过这个例子,我们能够更好地了解Linear函数
ReLu函数详解
ReLu函数基本定义:
下面是它的图像
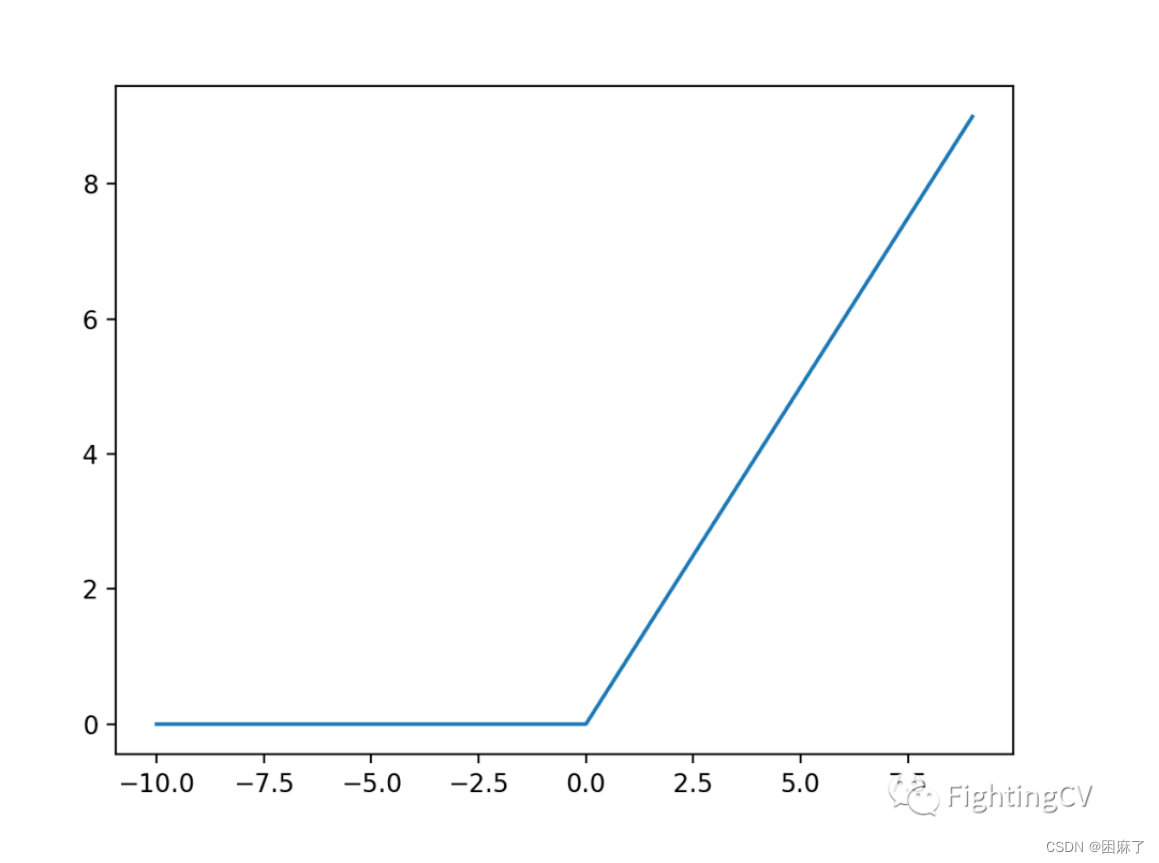
当输入值为正数时,返回原来的值,为负数时,返回0
torch.nn.ReLU(inplace=True)
torch.nn.ReLU(inplace=True)是PyTorch中的一个激活函数,其功能是对输入进行逐元素的非线性变换。
当参数inplace=True表示将变换后的结果直接覆盖原来的输入张量,节省内存空间。如果没有指定inplace=True,则会返回一个新的张量作为输出。
例子
print("--------ReLu函数--------")
import torch
relu = torch.nn.ReLU()
in1=torch.tensor([0.1234,-0.8373,0.2523,-0.4642,0.5268])
print("输入处理前数据:",in1)
out1=relu(in1)
print("ReLu计算后结果:",out1)
print("输入处理后数据:",in1)默认值为False
没有传参时,结果为:
输入处理前数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
ReLu计算后结果: tensor([0.1234, 0.0000, 0.2523, 0.0000, 0.5268])
输入处理后数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
可以看到,使用ReLu函数后不影响原输入量
参数inplace
下面,让我们对比下inplace=True或False的区别
import torch
print("Ture:")
relu1 = torch.nn.ReLU(inplace=False)
in1=torch.tensor([0.1234,-0.8373,0.2523,-0.4642,0.5268])
print("输入处理前数据:",in1)
out1=relu1(in1)
print("ReLu计算后结果:",out1)
print("输入处理后数据:",in1)
print("False:")
relu2 = torch.nn.ReLU(inplace=True)
print("输入处理前数据:",in1)
out2=relu2(in1)
print("ReLu计算后结果:",out2)
print("输入处理后数据:",in1)结果为:
Ture:
输入处理前数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
ReLu计算后结果: tensor([0.1234, 0.0000, 0.2523, 0.0000, 0.5268])
输入处理后数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
False:
输入处理前数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
ReLu计算后结果: tensor([0.1234, 0.0000, 0.2523, 0.0000, 0.5268])
输入处理后数据: tensor([0.1234, 0.0000, 0.2523, 0.0000, 0.5268])
Sogtmax激活函数
Softmax函数基本定义
在多分类问题中,我们通常会使用softmax函数作为网络输出层的激活函数。
softmax函数可以对输出值进行归一化操作,把所有输出值都转化为概率,所有概率值加起来等于1
torch.nn.Softmax(input, dim)
dim=0 表示按列计算
dim=1 表示按行计算
让我们先学习它的数学公式:
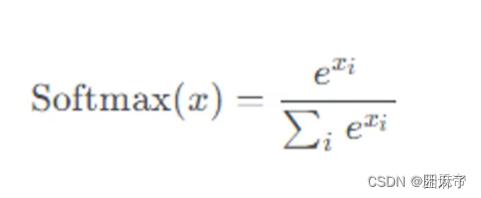
然后我们再学习它的推导过程
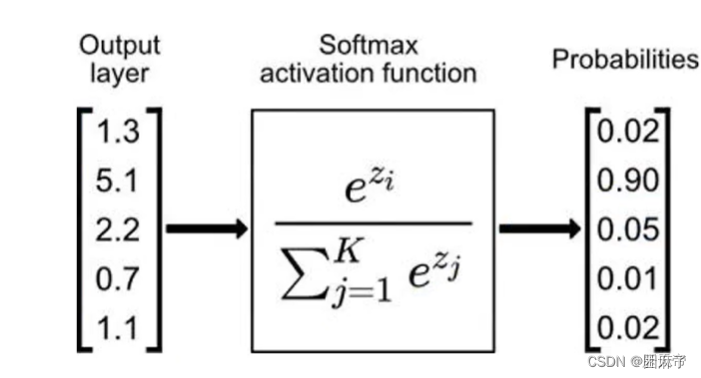
我们再后面手工计算softmax时需要用到
例子
import numpy as np
import torch
print("numpy版手工计算softmax")
ipnum=np.array([[1,2,3],[1,2,4]])
sum1=np.exp(1)+np.exp(2)+np.exp(3)
sum2=np.exp(1)+np.exp(2)+np.exp(4)
x00=np.exp(1)/sum1
x01=np.exp(2)/sum1
x02=np.exp(3)/sum1
x10=np.exp(1)/sum2
x11=np.exp(2)/sum2
x12=np.exp(4)/sum2
print("输出softmax手工计算结果:")
print(x00,x01,x02)
print(x10,x11,x12)
print("pytorch版softmax")
softmax=torch.nn.Softmax(dim=1)
input=torch.Tensor([[1,2,3],[1,2,4]])
output=softmax(input)
print("输出softmax自动计算结果:")
print(output)结果:
numpy版手工计算softmax
输出softmax手工计算结果:
0.09003057317038046 0.24472847105479767 0.6652409557748219
0.04201006613406605 0.11419519938459449 0.8437947344813395
pytorch版softmax
输出softmax自动计算结果:
tensor([[0.0900, 0.2447, 0.6652],
[0.0420, 0.1142, 0.8438]]通过numpy与pytorch两个版本的softmax,我们可以更好的了解Softmax的公式以及推导过程,这对我们加深对Softmax的理解有很大作用
用处
Softmax激活函数只能用在输出层神经元上。当感知器用于解决多分类问题时,输出层的神经元使用Softmax激活函数。当感知器用于解决二分类问题时,输出层的神经元可以使用Softmax激活函数,也可以使用Sigmoid激活函数。
NLLLoss函数
首先我们要了解交叉熵损失函数,torch.nn.CrossEntropyLoss()。
什么是熵?
熵是用来描述一个系统的混乱程度,通过交叉熵我们就能够确定预测数据与真实数据之间的相近程度。交叉熵越小,表示数据越接近真实样本。
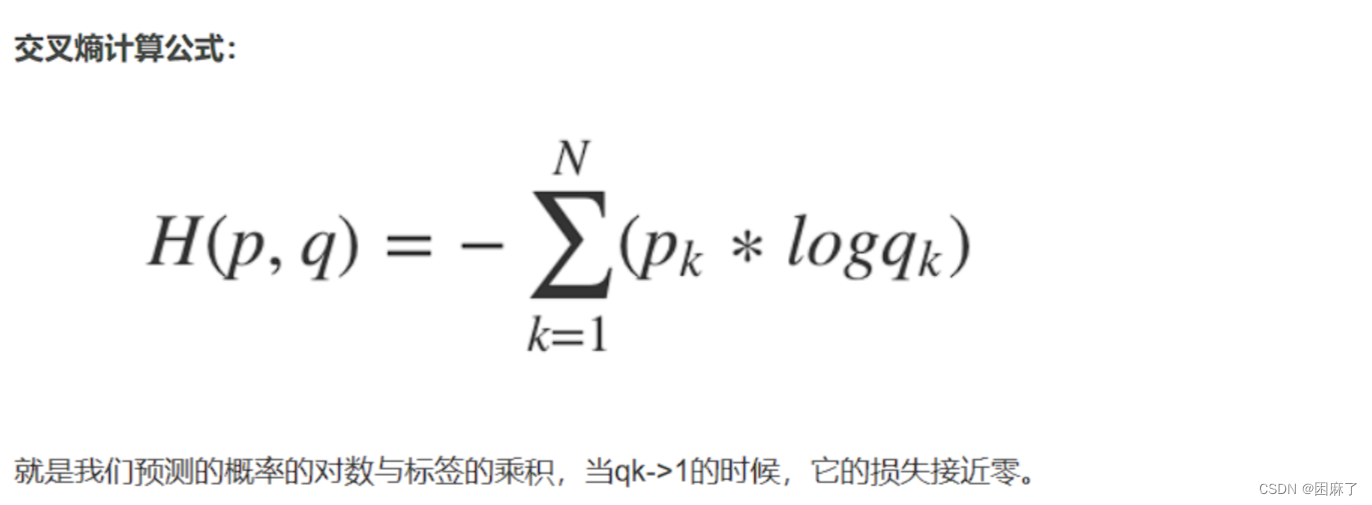
(预测的概率就是我们的预测值的准确值)
torch.nn.NLLLoss()
torch.nn.NLLLoss输入是一个对数概率向量和一个目标标签,它与torch.nn.CrossEntropyLoss的关系可以描述为:
假设有张量x,先softmax(x)得到y,然后再log(y)得到z,然后我们已知标签b,则:
NLLLoss(z,b)=CrossEntropyLoss(x,b)、
NLLLoss函数基本定义
NLLloss就是在做交叉熵损失函数的最后一步:预测结果的取负求和
例子
import torch
logsoftmax = torch.nn.LogSoftmax(dim=1)
input=torch.Tensor([[1,2,3],[1,2,4]])
output=logsoftmax(input)
print("输出LogSoftmax计算后结果:\n",output)
criterion = torch.nn.NLLLoss()
labels=torch.tensor([1,2])
loss=criterion(output,labels)
print(loss)
print((1.4076+0.1698)/2)labels=torch.tensor([1,2]) 意思是第一行取第1+1个,第二行取第2+1个
loss=criterion(output,labels)是指在结果output中,取label中的值,再去掉负号,再求均值,对应最后的(1.4076+0.1698)/2
下面我让我们看一下结果:
输出LogSoftmax计算后结果:
tensor([[-2.4076, -1.4076, -0.4076],
[-3.1698, -2.1698, -0.1698]])
tensor(0.7887)
0.7887
通过这个函数,我们能够更好地理解NLLLoss函数
CrossEntropyLoss函数
数学公式及含义
首先,我们要先了解一下它的数学公式
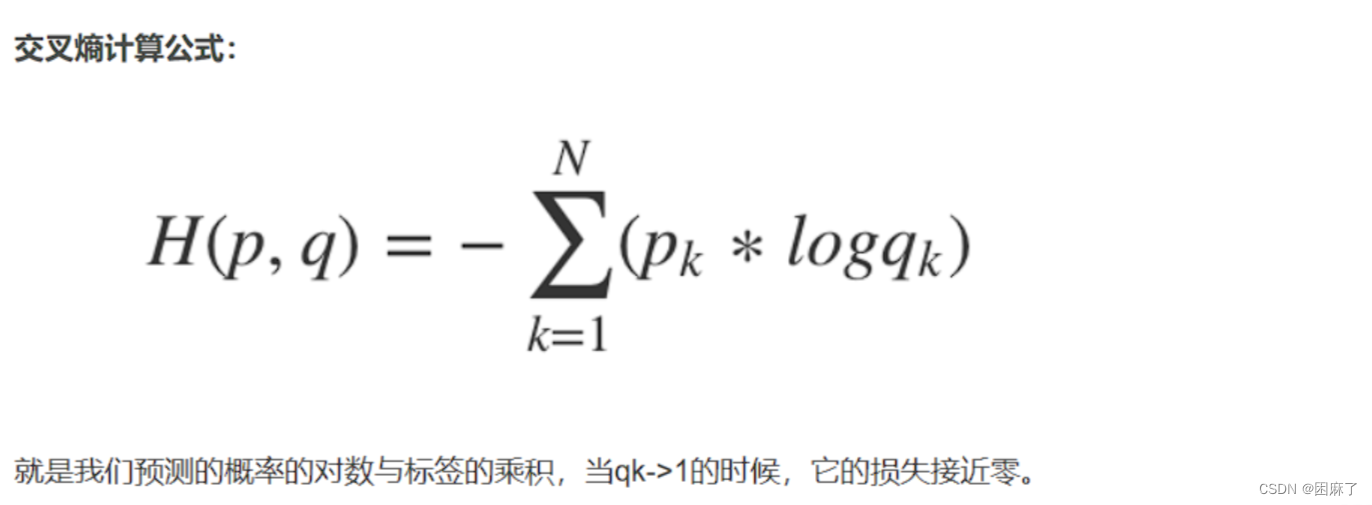
交叉熵:它主要刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。
Pytorch中CrossEntropyLoss()函数的主要是将softmax-log-NLLLoss合并到一块得到的结果。
Softmax后的数值都在0~1之间,所以 log 之后值域是负无穷到0。
然后将Softmax之后的结果取log,将乘法改成加法减少计算量,同时保障函数的单调性。
NLLLoss 的结果就是把上面的输出与 Label 对应的那个值拿出来,去掉负号,再求均值。
例子
import torch
print("使用NLLLoss函数")
logsoftmax1 = torch.nn.LogSoftmax(dim=1)
input1=torch.Tensor([[1,2,3],[1,2,4]])
output1=logsoftmax1(input1)
print("输出LogSoftmax计算后结果:\n",output1)
criterion1 = torch.nn.NLLLoss()
labels1=torch.tensor([1,2])
loss1=criterion1(output1,labels1)
print(loss1)
print("使用CrossEntropyLoss交叉熵损失函数")
criterion2 = torch.nn.CrossEntropyLoss()
loss2=criterion2(input1,labels1)
print(loss2)详细可以看上一部分
结果:
使用NLLLoss函数
输出LogSoftmax计算后结果:
tensor([[-2.4076, -1.4076, -0.4076],
[-3.1698, -2.1698, -0.1698]])
tensor(0.7887)
使用CrossEntropyLoss交叉熵损失函数
tensor(0.7887)
全部代码!!
print("--------Linear函数--------")
import torch
lp=torch.nn.Linear(2,3)
print("输出线性函数权重w值:",lp.weight)
print("输出线性函数权重w形状:",lp.weight.shape)
print()
print("输出线性函数偏置b值:",lp.bias)
print("输出线性函数偏置b形状:",lp.bias.shape)
print()
data=torch.Tensor([[1.0,1.0]])
print("测试数据:",data)
print("测试数据形状:",data.shape)
print()
out1=lp(data)
print("输出线性函数自动计算结果:",out1)
out2=data.matmul(lp.weight.T)+lp.bias
print("输出线性函数手工计算结果:",out2)
print("--------ReLu函数--------")
import torch
print("Ture:")
relu1 = torch.nn.ReLU(inplace=False)
in1=torch.tensor([0.1234,-0.8373,0.2523,-0.4642,0.5268])
print("输入处理前数据:",in1)
out1=relu1(in1)
print("ReLu计算后结果:",out1)
print("输入处理后数据:",in1)
print("False:")
relu2 = torch.nn.ReLU(inplace=True)
print("输入处理前数据:",in1)
out2=relu2(in1)
print("ReLu计算后结果:",out2)
print("输入处理后数据:",in1)
print("--------Softmax函数--------")
import numpy as np
import torch
print("numpy版手工计算softmax")
ipnum=np.array([[1,2,3],[1,2,4]])
sum1=np.exp(1)+np.exp(2)+np.exp(3)
sum2=np.exp(1)+np.exp(2)+np.exp(4)
x00=np.exp(1)/sum1
x01=np.exp(2)/sum1
x02=np.exp(3)/sum1
x10=np.exp(1)/sum2
x11=np.exp(2)/sum2
x12=np.exp(4)/sum2
print("输出softmax手工计算结果:")
print(x00,x01,x02)
print(x10,x11,x12)
print("pytorch版softmax")
softmax=torch.nn.Softmax(dim=1)
input=torch.Tensor([[1,2,3],[1,2,4]])
output=softmax(input)
print("输出softmax自动计算结果:")
print(output)
print("--------NLLLoss函数--------")
import torch
logsoftmax = torch.nn.LogSoftmax(dim=1)
input=torch.Tensor([[1,2,3],[1,2,4]])
output=logsoftmax(input)
print("输出LogSoftmax计算后结果:\n",output)
criterion = torch.nn.NLLLoss()
labels=torch.tensor([1,2])
loss=criterion(output,labels)
print(loss)
print((1.4076+0.1698)/2)
print("--------CrossEntropyLoss函数--------")
import torch
print("使用NLLLoss函数")
logsoftmax1 = torch.nn.LogSoftmax(dim=1)
input1=torch.Tensor([[1,2,3],[1,2,4]])
output1=logsoftmax1(input1)
print("输出LogSoftmax计算后结果:\n",output1)
criterion1 = torch.nn.NLLLoss()
labels1=torch.tensor([1,2])
loss1=criterion1(output1,labels1)
print(loss1)
print("使用CrossEntropyLoss交叉熵损失函数")
criterion2 = torch.nn.CrossEntropyLoss()
loss2=criterion2(input1,labels1)
print(loss2)结果如下:
--------Linear函数--------
输出线性函数权重w值: Parameter containing:
tensor([[ 0.3665, -0.5803],
[ 0.1982, -0.6994],
[ 0.2461, -0.0464]], requires_grad=True)
输出线性函数权重w形状: torch.Size([3, 2])
输出线性函数偏置b值: Parameter containing:
tensor([-0.0942, -0.0508, -0.6012], requires_grad=True)
输出线性函数偏置b形状: torch.Size([3])
测试数据: tensor([[1., 1.]])
测试数据形状: torch.Size([1, 2])
输出线性函数自动计算结果: tensor([[-0.3080, -0.5521, -0.4015]], grad_fn=<AddmmBackward0>)
输出线性函数手工计算结果: tensor([[-0.3080, -0.5521, -0.4015]], grad_fn=<AddBackward0>)
--------ReLu函数--------
Ture:
输入处理前数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
ReLu计算后结果: tensor([0.1234, 0.0000, 0.2523, 0.0000, 0.5268])
输入处理后数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
False:
输入处理前数据: tensor([ 0.1234, -0.8373, 0.2523, -0.4642, 0.5268])
ReLu计算后结果: tensor([0.1234, 0.0000, 0.2523, 0.0000, 0.5268])
输入处理后数据: tensor([0.1234, 0.0000, 0.2523, 0.0000, 0.5268])
--------Softmax函数--------
numpy版手工计算softmax
输出softmax手工计算结果:
0.09003057317038046 0.24472847105479767 0.6652409557748219
0.04201006613406605 0.11419519938459449 0.8437947344813395
pytorch版softmax
输出softmax自动计算结果:
tensor([[0.0900, 0.2447, 0.6652],
[0.0420, 0.1142, 0.8438]])
--------NLLLoss函数--------
输出LogSoftmax计算后结果:
tensor([[-2.4076, -1.4076, -0.4076],
[-3.1698, -2.1698, -0.1698]])
tensor(0.7887)
0.7887
--------CrossEntropyLoss函数--------
使用NLLLoss函数
输出LogSoftmax计算后结果:
tensor([[-2.4076, -1.4076, -0.4076],
[-3.1698, -2.1698, -0.1698]])
tensor(0.7887)
使用CrossEntropyLoss交叉熵损失函数
tensor(0.7887)
进程已结束,退出代码为 0














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









