






代码之后的注释和GAN的一样,大家如果已经掌握GAN,可以忽略掉哦!!!
在学习DCGAN之前,我们要先掌握GAN,深度学习--生成对抗网络GAN-CSDN博客 这篇博客讲的就是GAN的相关知识,还是很详细的。
DCGAN论文:1511.06434 (arxiv.org)
我们先来了解一下DCGAN的原理
DCGAN原理
在学习原理之前,我们要先复习一下GAN的结构,如下图:

DCGAN模型
它的生成器的结构如下:
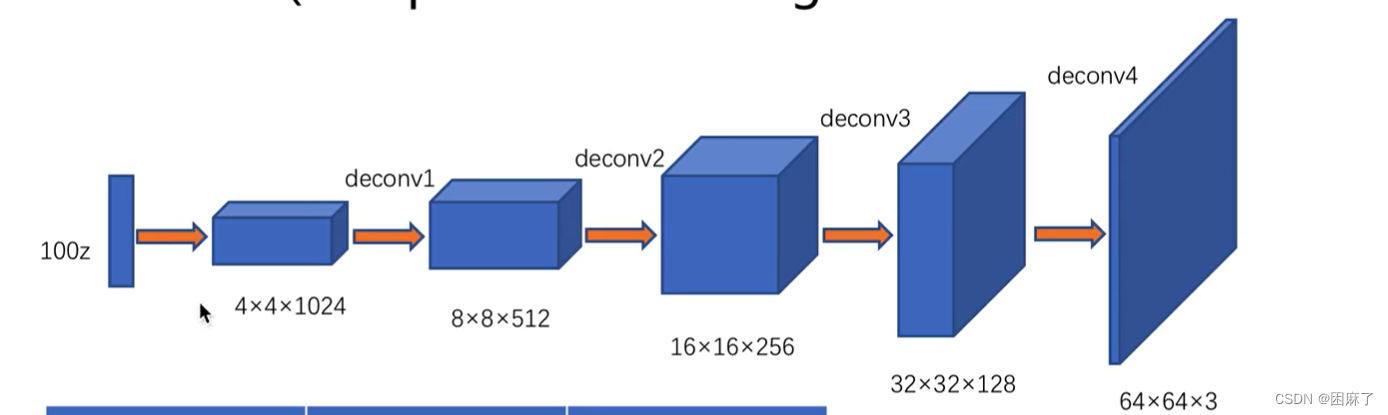
生成器的输入是噪声,输出是图片。
在生成器之中,我们就用到了转置卷积的结构,进行了上采样。
它在不断地提高分辨率,减少通道数。
判别器的结构:
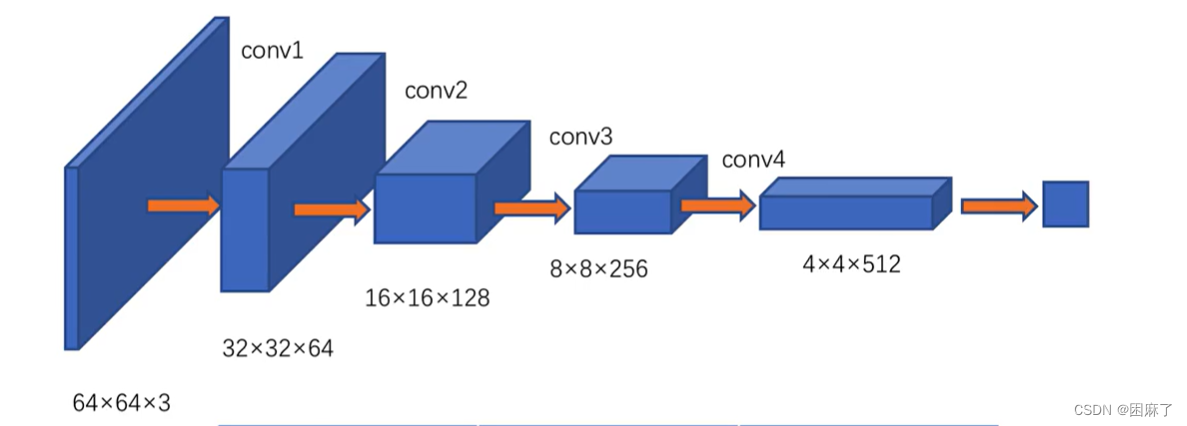
使用的是下采样的卷积 。
它的输入是64*64的图像,输出是真假的判别。
他在不断地提高通道数,减少分辨率。
DCGAN工程技巧
也就是DCGAN与GAN的不同之处:

简单翻译一下,意思就是:
1.在网络深层去除全连接层,
2.使用带步长的卷积替换池化,
3.在生成器的输出层使用Tanh激活函数,在其他层使用ReLu,
4.在判别器中使用LeakyReLu激活函数,
5.只对生成器模型的输出层和判别器模型的输入层Batch Normalization,BN可以稳定学习,有助于处理初始化不良导致的训练问题。也就是采用了批归一化, 将每一层的输入变换到0均值和单位方差(或者说转变到[0,1]范围内)。
预备知识
torch.nn.BatchNorm1d
nn.BatchNorm1d 是 PyTorch 中的一个用于一维数据(例如序列或时间序列)的批标准化(Batch Normalization)层。
批标准化是一种常用的神经网络正则化技术,旨在加速训练过程并提高模型的收敛性和稳定性。它通过对每个输入小批次的特征进行归一化处理来规范化输入数据的分布。
在一维数据上使用 nn.BatchNorm1d 层时,它会对每个特征维度上的数据进行标准化处理。具体而言,它会计算每个特征维度的均值和方差,并将输入数据进行中心化和缩放,以使其分布接近均值为0、方差为1的标准正态分布。
torch.nn.ConvTranspose2d
这是反卷积,也就是转置卷积的函数.
参数如下:
torch.nn.ConvTranspose2d(
in_channels, out_channels, kernel_size, stride=1, padding=0,
output_padding=0, groups=1, bias=True, dilation=1, padding_mode='zeros',
device=None, dtype=None)
转置卷积的计算步骤在下面的视频中,简单粗暴
torch.nn.Dropout2d
有多个channel的二维输出。赋值对象是彩色的图像数据(batch N,通道 C,高度 H,宽 W)的一个通道里的每一个数据。即输入为 Input: (N, C, H, W) 时,对每一个通道维度 C 按概率赋值为 0。
适用性:nn.Dropout2d用于将 dropout 正则化应用于卷积层,要求输入和输出数据为4维(N,C,H,W)。卷积层用于处理空间数据,例如图像,它们具有二维结构。
维度:它在二维张量上运行。如果您有一个 shape 的输入张量(batch_size, channels, height, width),nn.Dropout2d则会独立地将 dropout 应用于每个通道的空间维度,使每个通道独立清零。
有利于促进独立性特征图。
torch.nn.functional.leaky_relu
相当于LeakyReLu函数

函数图像如下
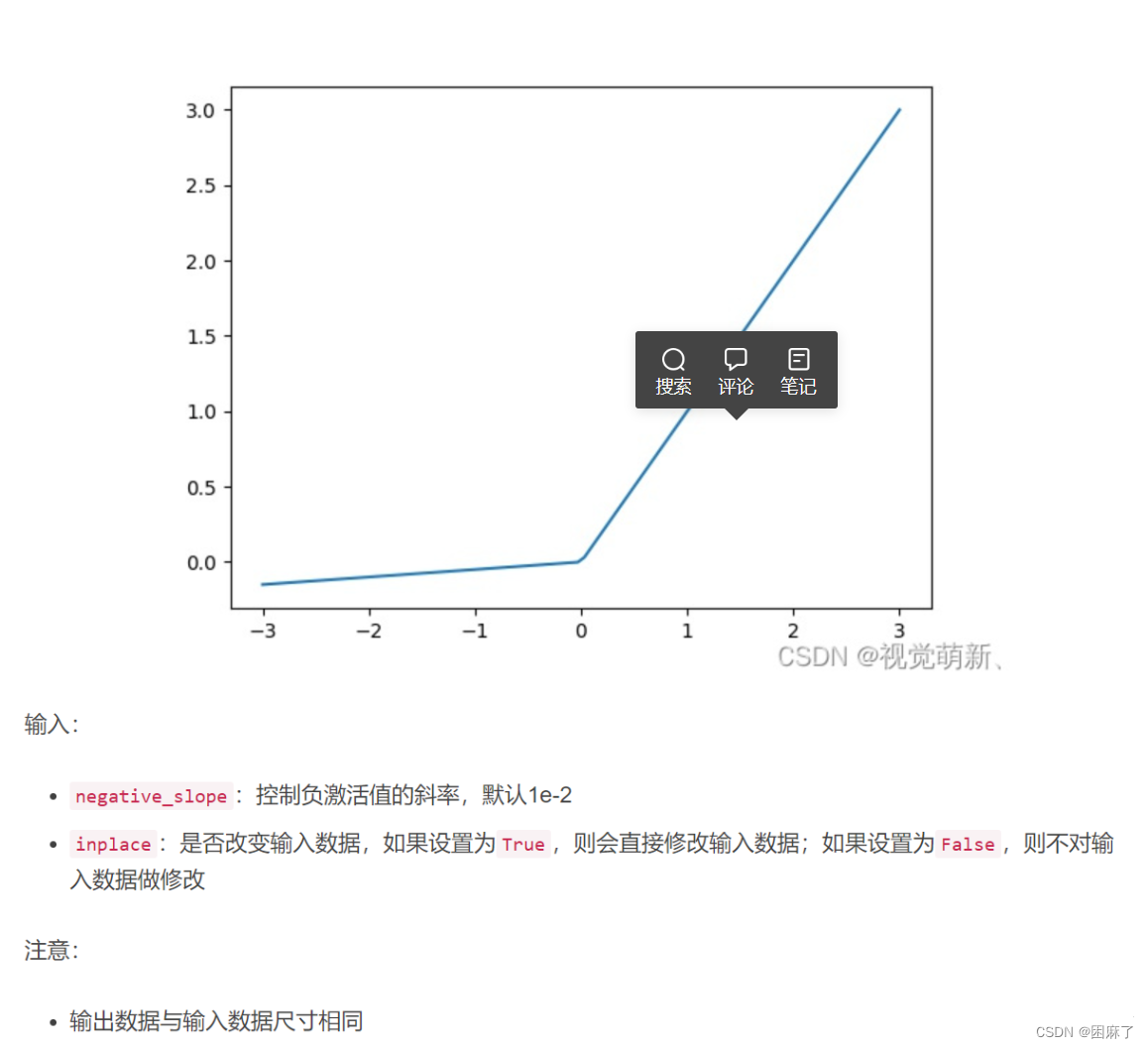
代码
导库
import matplotlib.pyplot as plt
import matplotlib
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
import numpy as np
import torch.nn.functional as F加载处理数据集
# 导入数据集并且进行数据处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0.5, 0.5)])
traindata = torchvision.datasets.MNIST(root='D:\learn_pytorch\数据集', train=True, download=True,
transform=transform) # 训练集60,000张用于训练
# 利用DataLoader加载数据集
trainload = DataLoader(dataset=traindata, shuffle=True, batch_size=64)
在加载数据集时,我们要将数据进行归一化,在GAN中,我们就需要将数据归一化到(-1,1)之间,这是为什么呢?原因是我们在下面会用到Tanh激活函数,而Tanh函数的范围是在-1到1之间的,见下图
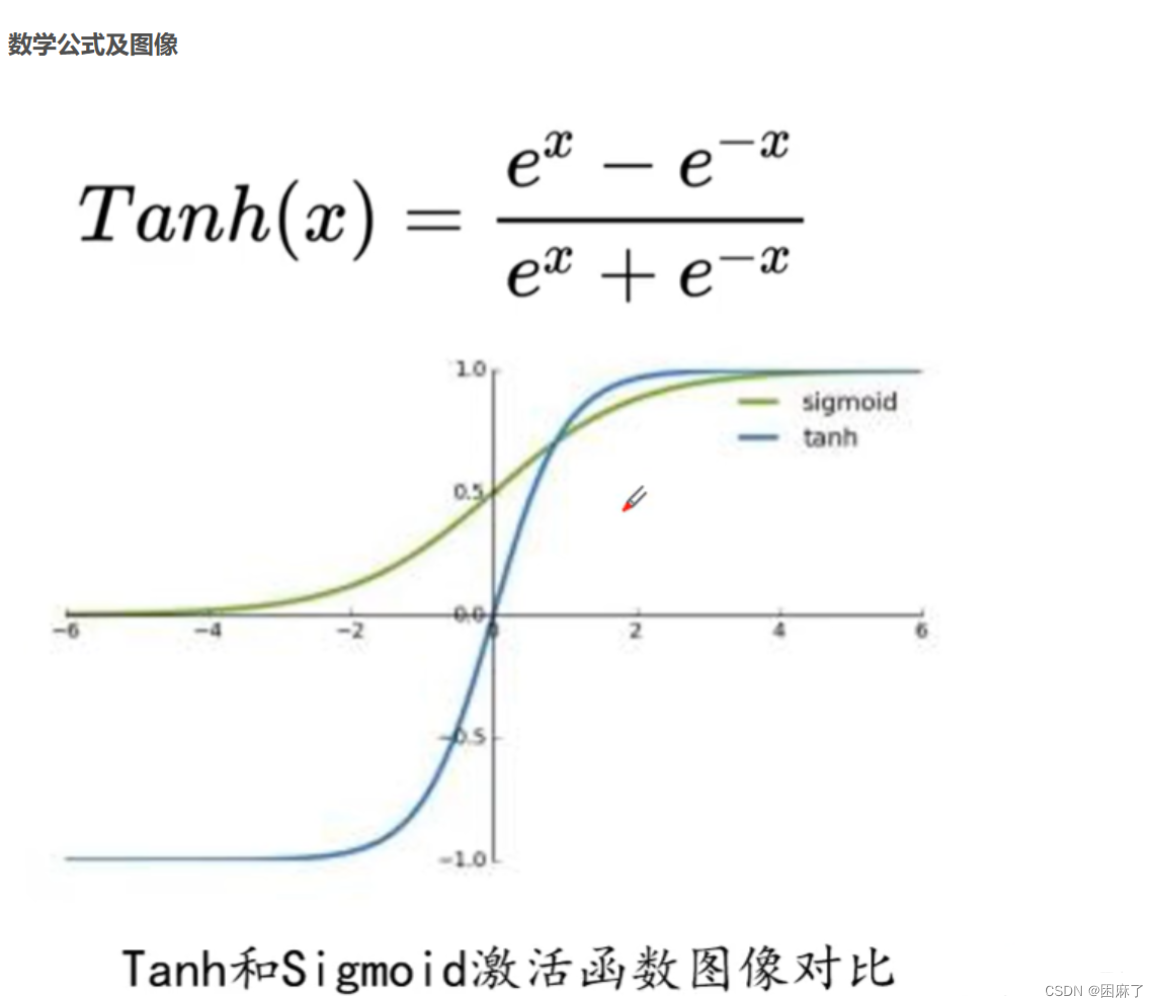
在我们既然知道了为什么要这样,下面就要学会如何做到了
在ToTensor中,我们是将数据的范围限制在了(0,1)之间,而后面的Normalize是将数据限制在(-1,1)之间,计算公式为(x-均值)/方差
生成器
class Generator(torch.nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = torch.nn.Linear(100, 7 * 7 * 256)
self.bn1 = torch.nn.BatchNorm1d(7 * 7 * 256)
self.uconv1 = torch.nn.ConvTranspose2d(256, 128, kernel_size=(3, 3), padding=1)
self.bn2 = torch.nn.BatchNorm2d(128)
self.uconv2 = torch.nn.ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=2, padding=1)
self.bn3 = torch.nn.BatchNorm2d(64)
self.uconv3 = torch.nn.ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=2, padding=1)
def forward(self, x):
# print('--------------------------------------')
# print('x.shape:',x.shape)
x = F.relu(self.linear1(x)) # torchsize([,]) .
x = F.relu(self.bn1(x))
# print('x.shape:',x.shape)
x = self.bn1(x)
x = x.view(-1, 256, 7, 7) # 64,256,7,7
# print('x.shape:',x.shape)
x = F.relu(self.uconv1(x))
# print('x.shape:',x.shape)
x = self.bn2(x)
# print('x.shape:', x.shape)
x = F.relu(self.uconv2(x))
# print('x.shape:', x.shape)
x = self.bn3(x)
# print('x.shape:', x.shape)
x = torch.tanh(self.uconv3(x))
# print('x.shape:', x.shape)#torch.Size([64, 1, 28, 28])
return x
判别器
# 判别器,最后判断0,1,这意味着最后可以是一个神经元或者两个神经元
class Discraiminator(torch.nn.Module):
def __init__(self):
super(Discraiminator, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 64, 3, 2)
self.conv2 = torch.nn.Conv2d(64, 128, 3, 2)
self.bn = torch.nn.BatchNorm2d(128)
self.fc = torch.nn.Linear(128 * 6 * 6, 1)
def forward(self, x):
# print('--------------------')
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 1, 28, 28])
x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x = self.bn(x)
x = x.view(-1, 128 * 6 * 6)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 4608])
x = torch.sigmoid(self.fc(x))
# print('x.shape:', x.shape)#torch.size([64,1])
return x
定义损失函数,优化函数和优化器
# 定义损失函数和优化函数
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discraiminator().to(device)
# 定义优化器
gen_opt = torch.optim.Adam(gen.parameters(), lr=0.0001)
dis_opt = torch.optim.Adam(dis.parameters(), lr=0.0001)
loss_fn = torch.nn.BCELoss() # 损失函数
在这里,我们选择使用BCELoss,交叉熵损失函数,这是因为在GAN中,判别器通常被视为一个二分类器,它试图区分输入是真实样本还是由生成器生成的假样本,而BCELoss就是用来做二分类的损失函数,正好对应。
在优化器部分,它们分别对生成器和判别器的参数进行优化。
图像显示
# 图像显示
def gen_img_plot(model, testdata):
pre = np.squeeze(model(testdata).detach().cpu().numpy())
# tensor.detach()
# 返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad。
# 即使之后重新将它的requires_grad置为true,它也不会具有梯度grad
# 这样我们就会继续使用这个新的tensor进行计算,后面当我们进行反向传播时,到该调用detach()的tensor就会停止,不能再继续向前进行传播
plt.figure()
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(pre[i])
plt.show()
因为我们最终要得到要得到的是处理数据输出的数组,所以我们要用squeeze将额外的单维度删除。
detach是单独开辟空间来保存数据,从而保证数据的稳定性。
plt.figure用来生成一个新画布。
使用subplot函数在一个4x4的网格中定位每个子图。i + 1是因为子图的索引是从1开始的,而不是从0开始。
imshow是在子图中显示图像。
最后的show来显示整体的图像。
后向传播及可视化
# 后向传播
dis_loss = [] # 判别器损失值记录
gen_loss = [] # 生成器损失值记录
lun = [] # 轮数
for epoch in range(100):
d_epoch_loss = 0
g_epoch_loss = 0
cout = len(trainload) # 938批次
for step, (img, _) in enumerate(trainload):
img = img.to(device) # 图像数据
# print('img.size:',img.shape)#img.size: torch.Size([64, 1, 28, 28])
size = img.size(0) # 一批次的图片数量64
# 随机生成一批次的100维向量样本,或者说100个像素点
random_noise = torch.randn(size, 100, device=device)
# 先进性判断器的后向传播
dis_opt.zero_grad()
real_output = dis(img)
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) # 真实数据的损失函数值
d_real_loss.backward()
gen_img = gen(random_noise)
fake_output = dis(gen_img.detach())
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) # 人造的数据的损失函数值
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
dis_opt.step()
# 生成器的后向传播
gen_opt.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_fn(fake_output, torch.ones_like(fake_output))
g_loss.backward()
gen_opt.step()
d_epoch_loss += d_loss
g_epoch_loss += g_loss
dis_loss.append(float(d_epoch_loss))
gen_loss.append(float(g_epoch_loss))
print(f'第{epoch + 1}轮的生成器损失值:{g_epoch_loss},判别器损失值{d_epoch_loss}')
lun.append(epoch + 1)
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure()
plt.plot(lun, dis_loss, 'r', label='判别器损失值')
plt.plot(lun, gen_loss, 'b', label='生成器损失值')
plt.xlabel('训练轮数', fontsize=12)
plt.ylabel('损失值', fontsize=12)
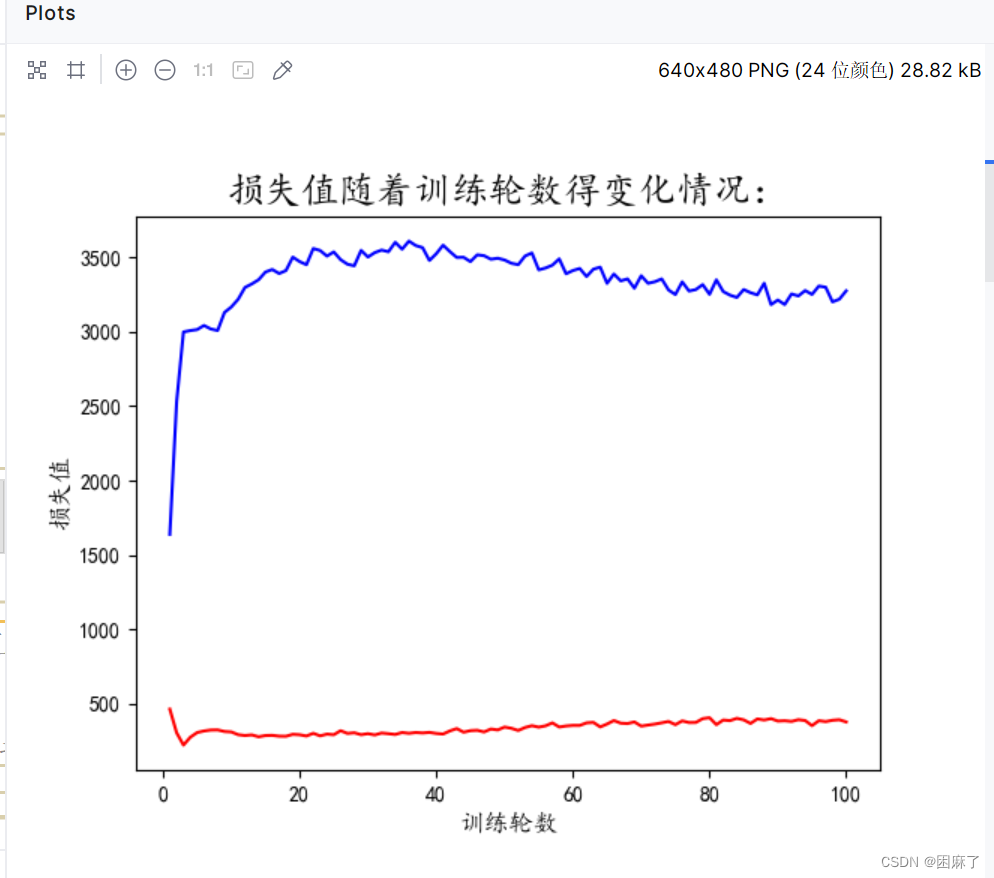
plt.title('损失值随着训练轮数得变化情况:',fontsize=18)
plt.show()
random_noise = torch.randn(16, 100, device=device)
gen_img_plot(gen, random_noise)
使用enumerate遍历训练数据集trainload,其中img是图像数据,但_表示我们在这里不使用标签(因为GAN是无监督的)。
step()用来更新判别器的模型参数。
在生成器的后向传播部分,
我们先进行梯度清零,然后通过生成器生成假图像,然后进行前向传播。
我们期望判别器对假图像的评分接近1(真实),因此我们将目标标签设置为与fake_output形状相同的全1张量torch.ones_like(fake_output)。
在这里,d_loss和g_loss是一张图像中的损失值,而d_epoch_loss和g_epoch_loss是每一轮损失值的累加,用于最后图像的绘制。
随机生成的噪声有16个样本,100个维度
全部代码
import matplotlib.pyplot as plt
import matplotlib
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
import numpy as np
import torch.nn.functional as F
# 导入数据集并且进行数据处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0.5, 0.5)])
traindata = torchvision.datasets.MNIST(root='D:\learn_pytorch\数据集', train=True, download=True,
transform=transform) # 训练集60,000张用于训练
# 利用DataLoader加载数据集
trainload = DataLoader(dataset=traindata, shuffle=True, batch_size=64)
# GAN生成对抗网络,步骤:
# 首先编写生成器和判别器
# 然后固定生成器,用我们的数据优化判别器,试得我们最开始生成器生成的图片判断为0,真实图片判断为1
# 接着固定判别器,利用我们的判别器判断生成器生成的图片,以判断的尽可能接近一为目的优化我们的生成器
# 生成器的代码(针对手写字体识别)
class Generator(torch.nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.linear1 = torch.nn.Linear(100, 7 * 7 * 256)
self.bn1 = torch.nn.BatchNorm1d(7 * 7 * 256)
self.uconv1 = torch.nn.ConvTranspose2d(256, 128, kernel_size=(3, 3), padding=1)
self.bn2 = torch.nn.BatchNorm2d(128)
self.uconv2 = torch.nn.ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=2, padding=1)
self.bn3 = torch.nn.BatchNorm2d(64)
self.uconv3 = torch.nn.ConvTranspose2d(64, 1, kernel_size=(4, 4), stride=2, padding=1)
def forward(self, x):
# print('--------------------------------------')
# print('x.shape:',x.shape)
x = F.relu(self.linear1(x)) # torchsize([,]) .
x = F.relu(self.bn1(x))
# print('x.shape:',x.shape)
x = self.bn1(x)
x = x.view(-1, 256, 7, 7) # 64,256,7,7
# print('x.shape:',x.shape)
x = F.relu(self.uconv1(x))
# print('x.shape:',x.shape)
x = self.bn2(x)
# print('x.shape:', x.shape)
x = F.relu(self.uconv2(x))
# print('x.shape:', x.shape)
x = self.bn3(x)
# print('x.shape:', x.shape)
x = torch.tanh(self.uconv3(x))
# print('x.shape:', x.shape)#torch.Size([64, 1, 28, 28])
return x
# 判别器,最后判断0,1,这意味着最后可以是一个神经元或者两个神经元
class Discraiminator(torch.nn.Module):
def __init__(self):
super(Discraiminator, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 64, 3, 2)
self.conv2 = torch.nn.Conv2d(64, 128, 3, 2)
self.bn = torch.nn.BatchNorm2d(128)
self.fc = torch.nn.Linear(128 * 6 * 6, 1)
def forward(self, x):
# print('--------------------')
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 1, 28, 28])
x = F.dropout2d(F.leaky_relu(self.conv1(x)), p=0.3)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x = F.dropout2d(F.leaky_relu(self.conv2(x)), p=0.3)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 128, 6, 6])
x = self.bn(x)
x = x.view(-1, 128 * 6 * 6)
# print('x.shape:', x.shape)#x.shape: torch.Size([64, 4608])
x = torch.sigmoid(self.fc(x))
# print('x.shape:', x.shape)#torch.size([64,1])
return x
# 定义损失函数和优化函数
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discraiminator().to(device)
# 定义优化器
gen_opt = torch.optim.Adam(gen.parameters(), lr=0.0001)
dis_opt = torch.optim.Adam(dis.parameters(), lr=0.0001)
loss_fn = torch.nn.BCELoss() # 损失函数
# 图像显示
def gen_img_plot(model, testdata):
pre = np.squeeze(model(testdata).detach().cpu().numpy())
# tensor.detach()
# 返回一个新的tensor,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个tensor永远不需要计算其梯度,不具有grad。
# 即使之后重新将它的requires_grad置为true,它也不会具有梯度grad
# 这样我们就会继续使用这个新的tensor进行计算,后面当我们进行反向传播时,到该调用detach()的tensor就会停止,不能再继续向前进行传播
plt.figure()
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(pre[i])
plt.show()
# 后向传播
dis_loss = [] # 判别器损失值记录
gen_loss = [] # 生成器损失值记录
lun = [] # 轮数
for epoch in range(100):
d_epoch_loss = 0
g_epoch_loss = 0
cout = len(trainload) # 938批次
for step, (img, _) in enumerate(trainload):
img = img.to(device) # 图像数据
# print('img.size:',img.shape)#img.size: torch.Size([64, 1, 28, 28])
size = img.size(0) # 一批次的图片数量64
# 随机生成一批次的100维向量样本,或者说100个像素点
random_noise = torch.randn(size, 100, device=device)
# 先进性判断器的后向传播
dis_opt.zero_grad()
real_output = dis(img)
d_real_loss = loss_fn(real_output, torch.ones_like(real_output)) # 真实数据的损失函数值
d_real_loss.backward()
gen_img = gen(random_noise)
fake_output = dis(gen_img.detach())
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output)) # 人造的数据的损失函数值
d_fake_loss.backward()
d_loss = d_real_loss + d_fake_loss
dis_opt.step()
# 生成器的后向传播
gen_opt.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_fn(fake_output, torch.ones_like(fake_output))
g_loss.backward()
gen_opt.step()
d_epoch_loss += d_loss
g_epoch_loss += g_loss
dis_loss.append(float(d_epoch_loss))
gen_loss.append(float(g_epoch_loss))
print(f'第{epoch + 1}轮的生成器损失值:{g_epoch_loss},判别器损失值{d_epoch_loss}')
lun.append(epoch + 1)
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']
plt.figure()
plt.plot(lun, dis_loss, 'r', label='判别器损失值')
plt.plot(lun, gen_loss, 'b', label='生成器损失值')
plt.xlabel('训练轮数', fontsize=12)
plt.ylabel('损失值', fontsize=12)
plt.title('损失值随着训练轮数得变化情况:',fontsize=18)
plt.show()
random_noise = torch.randn(16, 100, device=device)
gen_img_plot(gen, random_noise)
运行结果
第1轮的生成器损失值:1637.9466552734375,判别器损失值464.1025695800781
第2轮的生成器损失值:2530.494384765625,判别器损失值305.1524353027344
第3轮的生成器损失值:2997.694580078125,判别器损失值222.53155517578125
第4轮的生成器损失值:3006.974365234375,判别器损失值275.3566589355469
第5轮的生成器损失值:3013.507080078125,判别器损失值306.8394775390625
第6轮的生成器损失值:3041.133056640625,判别器损失值317.3689270019531
第7轮的生成器损失值:3017.63427734375,判别器损失值323.7129821777344
第8轮的生成器损失值:3007.423828125,判别器损失值324.5998840332031
第9轮的生成器损失值:3128.52783203125,判别器损失值313.85247802734375
第10轮的生成器损失值:3165.2890625,判别器损失值310.9962158203125
第11轮的生成器损失值:3216.90673828125,判别器损失值292.4429931640625
第12轮的生成器损失值:3296.56396484375,判别器损失值286.9037780761719
第13轮的生成器损失值:3320.12255859375,判别器损失值291.0125732421875
第14轮的生成器损失值:3348.47802734375,判别器损失值278.4036560058594
第15轮的生成器损失值:3400.251708984375,判别器损失值286.7728576660156
第16轮的生成器损失值:3417.241943359375,判别器损失值287.98321533203125
第17轮的生成器损失值:3390.15380859375,判别器损失值282.5353088378906
第18轮的生成器损失值:3410.00732421875,判别器损失值281.8512878417969
第19轮的生成器损失值:3500.480224609375,判别器损失值294.86407470703125
第20轮的生成器损失值:3470.27392578125,判别器损失值292.0498046875
第21轮的生成器损失值:3449.343505859375,判别器损失值283.53033447265625
第22轮的生成器损失值:3558.106689453125,判别器损失值301.805908203125
第23轮的生成器损失值:3544.840087890625,判别器损失值284.54559326171875
第24轮的生成器损失值:3507.136474609375,判别器损失值296.3019104003906
第25轮的生成器损失值:3535.285888671875,判别器损失值292.21417236328125
第26轮的生成器损失值:3483.247802734375,判别器损失值319.2896728515625
第27轮的生成器损失值:3452.71533203125,判别器损失值300.94207763671875
第28轮的生成器损失值:3441.982177734375,判别器损失值305.394287109375
第29轮的生成器损失值:3545.740234375,判别器损失值292.4477233886719
第30轮的生成器损失值:3500.8740234375,判别器损失值299.3537902832031
第31轮的生成器损失值:3530.58837890625,判别器损失值290.83367919921875
第32轮的生成器损失值:3547.6357421875,判别器损失值303.5927734375
第33轮的生成器损失值:3536.327392578125,判别器损失值299.1307373046875
第34轮的生成器损失值:3599.991943359375,判别器损失值293.924560546875
第35轮的生成器损失值:3553.3603515625,判别器损失值307.1707763671875
第36轮的生成器损失值:3607.927734375,判别器损失值301.6771240234375
第37轮的生成器损失值:3578.015380859375,判别器损失值307.1168212890625
第38轮的生成器损失值:3564.02197265625,判别器损失值304.1378479003906
第39轮的生成器损失值:3477.672119140625,判别器损失值307.8915100097656
第40轮的生成器损失值:3523.138427734375,判别器损失值300.7839660644531
第41轮的生成器损失值:3580.55615234375,判别器损失值296.95367431640625
第42轮的生成器损失值:3537.208984375,判别器损失值317.746826171875
第43轮的生成器损失值:3497.8994140625,判别器损失值333.478759765625
第44轮的生成器损失值:3499.179443359375,判别器损失值309.1123352050781
第45轮的生成器损失值:3470.083984375,判别器损失值319.6141052246094
第46轮的生成器损失值:3515.869873046875,判别器损失值321.9976806640625
第47轮的生成器损失值:3509.823486328125,判别器损失值310.7447814941406
第48轮的生成器损失值:3486.165283203125,判别器损失值330.5418395996094
第49轮的生成器损失值:3492.86083984375,判别器损失值324.3530578613281
第50轮的生成器损失值:3480.895263671875,判别器损失值343.64190673828125
第51轮的生成器损失值:3458.932373046875,判别器损失值335.3240661621094
第52轮的生成器损失值:3449.647216796875,判别器损失值320.6033630371094
第53轮的生成器损失值:3507.733154296875,判别器损失值340.7387390136719
第54轮的生成器损失值:3528.40185546875,判别器损失值352.86712646484375
第55轮的生成器损失值:3414.6552734375,判别器损失值343.109130859375
第56轮的生成器损失值:3427.310546875,判别器损失值352.00225830078125
第57轮的生成器损失值:3446.245849609375,判别器损失值371.7415771484375
第58轮的生成器损失值:3488.618896484375,判别器损失值343.9029846191406
第59轮的生成器损失值:3388.469482421875,判别器损失值351.0376281738281
第60轮的生成器损失值:3410.164794921875,判别器损失值354.8907165527344
第61轮的生成器损失值:3424.15625,判别器损失值354.5815124511719
第62轮的生成器损失值:3369.984130859375,判别器损失值371.8444519042969
第63轮的生成器损失值:3419.359619140625,判别器损失值375.1051025390625
第64轮的生成器损失值:3432.91796875,判别器损失值344.61578369140625
第65轮的生成器损失值:3324.12109375,判别器损失值364.02874755859375
第66轮的生成器损失值:3386.9599609375,判别器损失值387.5386962890625
第67轮的生成器损失值:3340.77392578125,判别器损失值369.8281555175781
第68轮的生成器损失值:3354.0810546875,判别器损失值367.2720642089844
第69轮的生成器损失值:3291.53662109375,判别器损失值378.1933898925781
第70轮的生成器损失值:3375.2119140625,判别器损失值350.12457275390625
第71轮的生成器损失值:3324.4580078125,判别器损失值357.1696472167969
第72轮的生成器损失值:3334.96875,判别器损失值363.599365234375
第73轮的生成器损失值:3353.963623046875,判别器损失值372.2528381347656
第74轮的生成器损失值:3279.52001953125,判别器损失值381.4432678222656
第75轮的生成器损失值:3248.873291015625,判别器损失值359.6973876953125
第76轮的生成器损失值:3334.107177734375,判别器损失值385.186279296875
第77轮的生成器损失值:3272.5595703125,判别器损失值373.97161865234375
第78轮的生成器损失值:3282.48388671875,判别器损失值374.6603698730469
第79轮的生成器损失值:3315.8173828125,判别器损失值400.2161865234375
第80轮的生成器损失值:3250.458984375,判别器损失值406.6080627441406
第81轮的生成器损失值:3347.8037109375,判别器损失值359.7836608886719
第82轮的生成器损失值:3269.06982421875,判别器损失值390.88812255859375
第83轮的生成器损失值:3244.718994140625,判别器损失值386.9516906738281
第84轮的生成器损失值:3229.3994140625,判别器损失值402.3242492675781
第85轮的生成器损失值:3282.469482421875,判别器损失值392.0705871582031
第86轮的生成器损失值:3261.463134765625,判别器损失值367.95782470703125
第87轮的生成器损失值:3246.7060546875,判别器损失值398.2889099121094
第88轮的生成器损失值:3325.021240234375,判别器损失值391.1697692871094
第89轮的生成器损失值:3181.181396484375,判别器损失值400.4288024902344
第90轮的生成器损失值:3212.197998046875,判别器损失值384.01031494140625
第91轮的生成器损失值:3181.767578125,判别器损失值386.2222595214844
第92轮的生成器损失值:3253.033447265625,判别器损失值381.6040344238281
第93轮的生成器损失值:3239.474853515625,判别器损失值393.23797607421875
第94轮的生成器损失值:3275.764404296875,判别器损失值387.4879150390625
第95轮的生成器损失值:3249.69482421875,判别器损失值353.1047668457031
第96轮的生成器损失值:3305.953857421875,判别器损失值386.5541687011719
第97轮的生成器损失值:3298.284423828125,判别器损失值380.4208068847656
第98轮的生成器损失值:3199.724609375,判别器损失值389.3112487792969
第99轮的生成器损失值:3217.61962890625,判别器损失值392.8823547363281
第100轮的生成器损失值:3273.804443359375,判别器损失值378.09771728515625
进程已结束,退出代码为 0生成图片
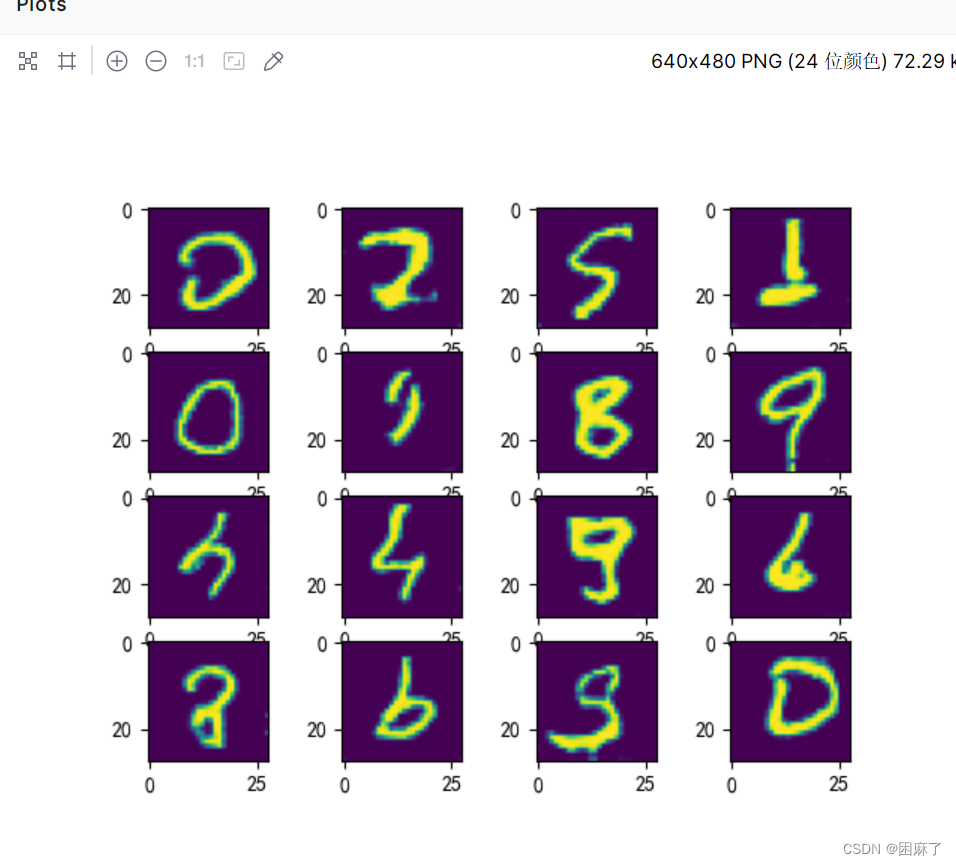
这里训练了100轮,其实30轮就差不多,这里可以清楚的看出来,我们生成器生成的图片(我们是以手写字体数据集为例子),很接近真实图片了。















 2188
2188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









