










图像翻译/Transformer:ITTR: https://arxiv.org/abs/2203.16015用Transformer进行非配对图像对图像的转换
0.摘要
未配对图像到图像的翻译是在没有成对训练数据的情况下,将图像从源域翻译到目标域。通过利用CNN提取局部语义,人们开发了各种技术来提高翻译性能。然而,基于CNN的生成器缺乏捕获长期依赖性的能力,无法很好地利用全局语义。近年来,视觉转换器在识别任务中得到了广泛的研究。虽然很有吸引力,但由于生成困难和计算限制,将基于识别的视觉转换器简单地转换为图像到图像的翻译是不合适的。在本文中,我们提出了一种有效的基于Transformer的非成对图像到图像翻译体系结构(ITTR)。它主要有两种设计:1)混合感知块(HPB),用于从不同感受域混合标记,以利用全局语义;2) 双剪枝自我注意(DPSA)可大幅降低计算复杂度。在六个基准数据集上,我们的ITTR在未配对图像到图像的翻译方面优于最新水平。
1.概述
未配对图像到图像的翻译是在没有成对训练数据的情况下,将图像从源域翻译到目标域。翻译结果应该由源域的内容和目标域的风格构成。大多数重要的未配对图像到图像翻译方法【59,34,58】都关注训练策略的制定。然而,生成器结构仍然基于卷积神经网络(CNN)。虽然CNN在提取局部语义方面是有效的,但它缺乏捕获图1中所示的长期依赖性的能力。
为了丰富美国有线电视新闻网的能力,之前的一项研究I2ISA[20]试图采用非局部块[49]。特别是,受SAGAN【56】的启发,I2ISA【20】在其生成器架构中嵌入了一个非局部块,以增强未成对图像到图像的转换性能。尽管I2ISA的翻译性能大体上是有效的,但如图2所示,I2ISA的翻译性能仍然在一定程度上受到限制。产生此结果的一个可能原因是I2ISA在生成器的解码器中只有一个非局部块,这仍然缺乏充分利用全局语义的能力。
为了完全捕获长距离依赖关系,一个潜在的解决方案是引入基于Transformer的生成器体系结构,用于未成对的图像到图像的转换。事实上,视觉Transformer可以与多个多头自我注意(MHSA)块堆叠在一起,以持续捕获长期依赖性。然而,基于识别的Transformer不适合像未成对图像到图像的转换这样的生成任务,这需要视觉质量和语义一致性。此外,当输入图像分辨率较高时,由于MHSA算法的复杂性,基于识别的Transformer也会遭受巨大的计算开销和内存消耗。因此,需要新的设计来处理生成困难和计算限制。
在本文中,我们提出了一种有效的基于Transformer的非成对图像到图像翻译体系结构(ITTR)。它有两种有针对性的设计。首先,我们提出了混合感知块(HPB),用于不同感受野的空间token混合,旨在解决生成器在生成过程中遇到的难点。HPB能够分别通过深度卷积分支和自我注意分支提取短距离和长距离上下文信息。其次,我们提出双重剪枝自我注意(DPSA)来降低MHSA的复杂性。在计算注意图之前,DPSA评估标记对行和列的贡献。然后,对贡献较少的标记进行修剪,以便大幅降低注意力地图的复杂性。
为了证明我们的方法的有效性,我们在包括Horse在内的六个基准数据集上对未成对图像到图像的翻译进行了定性和定量实验→ 斑马[59]、城市景观[6]、猫→ 狗,脸→ Metface【21】,女性→ 卡通【36】和自拍→ 动画【24】。图3显示了ITTR产生的一些定性结果。与最先进的方法相比,ITTR在定性和定量方面都取得了更好的性能。
我们的贡献总结如下:
- 针对未成对图像到图像的翻译任务,提出了一种基于转换器的体系结构ITTR
- 混合感知块(HPB)旨在从本地和全球的不同感知中捕获上下文信息
- 为了在保持性能的同时降低计算复杂度和内存消耗,提出了双剪枝自我注意(DPSA)
- 在六个数据集上的实验从定性和定量两方面验证了我们方法的有效性。特别是,我们的方法在FID【16】和DRN得分【34】方面都优于最先进的方法。
2.方法
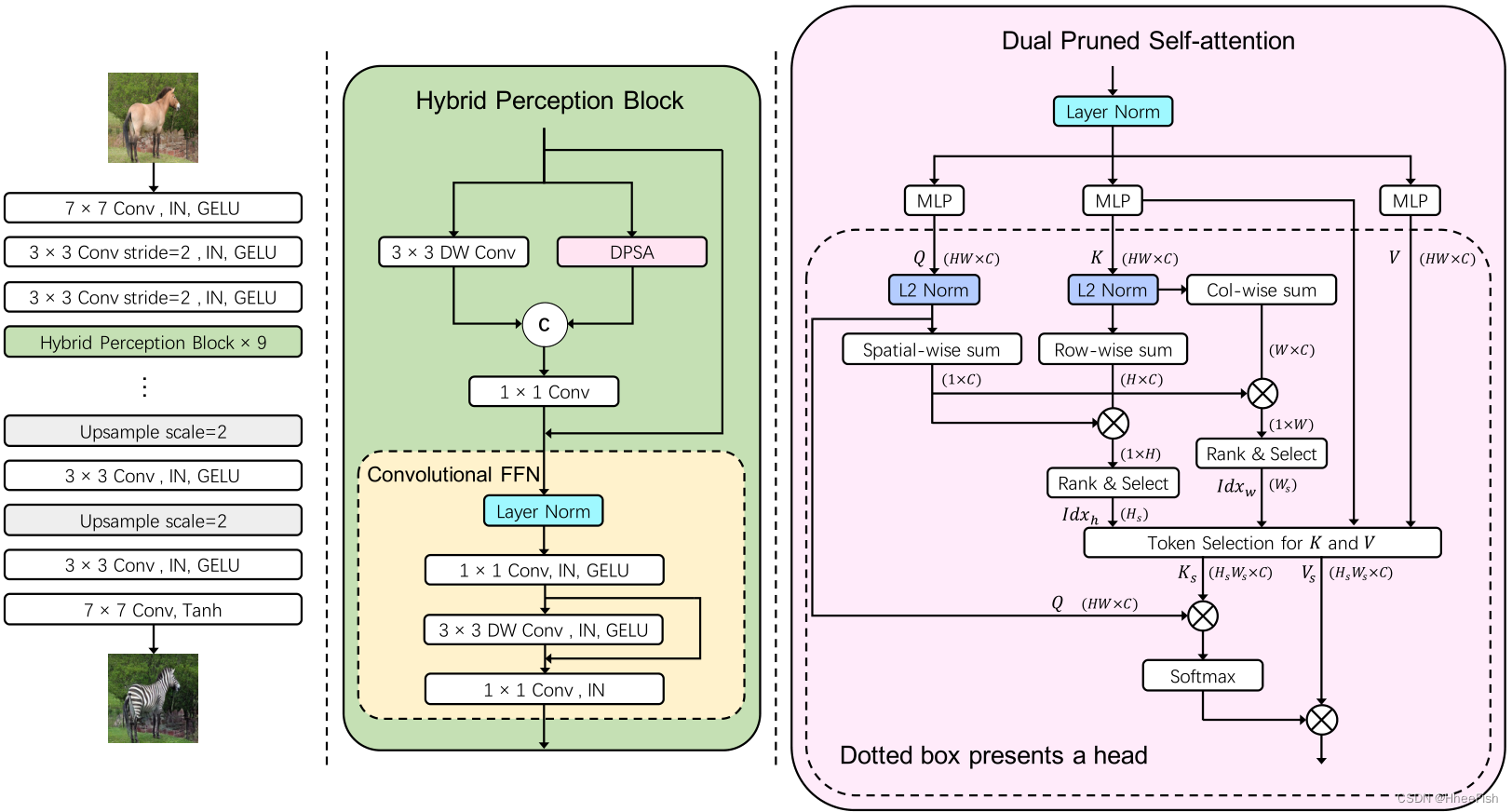
图4所示。ITTR的架构。从左到右分别为ITTR整体架构、HPB (hybrid perception block)架构、DPSA (dual pruned self-attention)架构。“Conv”意味着卷积。“IN”是实例规范化的缩写。“DW”意味着深度方面。圈中的“C”表示串联。“L2规范”是明智的L2规范化。space -wise sum是计算q中所有令牌的和。row -wise或Col-wise sum是计算k中同一行或同列令牌的和。Token selection是从一个有索引的矩阵中选择行和列。圈中的“×”表示矩阵乘法。右边的虚线框表示在DPSA单个头部进行的操作。
在本节中,我们首先介绍有关vision transformer的一般架构的一些预备知识。然后,我们从总体架构和构建块、混合感知块和双重修剪自我注意等方面说明了ITTR的详细设计,如图4所示。最后,我们提出了完整的学习目标。
2.1.预备知识
Transformer(Transformer)[43]最初是作为自然语言处理(NLP)任务的网络体系结构提出的。后来,ViT[8]为图像分类等视觉任务引入了基于transformer的体系结构。ViT是由MHSA和FFN组成的纯Transformer网络。在ViT中,二维图像的面片I∈ RH×W×3嵌入到Token X∈ RN×C中。然后将Token 拆分为Nh头X∈ RNh×N×C/Nh。Xi∈ RN×Dh,i∈ {1,2…Nh},Dh=C /Nh,用于按线性层计算Qi、Ki和Vi。
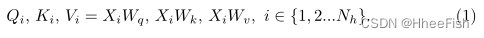
这里,Wq,Wk,Wv∈ RC×C表示对应于查询、键和值的可学习参数矩阵。然后,用Qi,Ki,Vi计算自我注意。
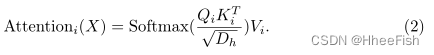
来自每个头部的结果被串联起来,并以偏差输入到线性层中。
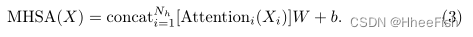
然后将串联的特征映射输入前馈网络(FFN)。
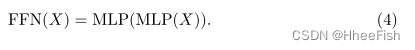
最近的一些工作【47,12】已经在FFN中插入了深度方向的卷积层。这种变体被称为反向前馈网络(IFFN),因为它类似于MobileNetV2中的反向残差块[37]。
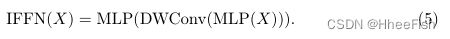
2.2.整体架构
如图4所示,我们提出的ITTR的总体架构由三部分组成:1)带有三个卷积层的stem,用于重叠的贴片嵌入和下采样操作;2) ITTR主体由9个串联的混合感知块组成;3) ITTR的解码器,是stem的镜像。设计动机描述如下
首先,为了扩大面片的大小,我们使用堆叠卷积层进行重叠面片嵌入。与非重叠面片嵌入相比,重叠面片嵌入的面片大小由4×4增加到13×13像素。此外,将重叠的面片嵌入层解耦为三个卷积层更有效。其次,为了确保生成器容量并进行公平比较,我们在ITTR主体中堆叠了9个HPB,以便块数与基线切割中的发电机相同【34】。第三,ITTR译码器采用三层卷积实现。卷积层比HPB更有效地处理上采样后的高分辨率特征映射。
使用输入图像I∈ RH×W×3执行上述步骤可描述如下:
2.3.混合感知块
提出了混合感知块(HPB)从局部感知和全局感知中获取上下文信息。为了实现这一点,HPB使用图4所示的两个并行分支在相邻或遥远的token之间进行空间token混合。局部分支采用卷积层以提高局部效率。更准确地说,我们使用了一个深度方向的卷积层来进一步降低复杂性。此外,全局分支机构采用自我关注来实现远程依赖。因为自我注意中的注意映射在每个标记对之间建立了关系。
此外,预计将进行信道融合。首先采用MLP层对两个分支提取的位置对应标记进行融合,目的是融合从不同感知中提取的上下文信息。然后,采用卷积FFN进行更详细的融合,并进行信道扩展和缩减。此外,在信道扩展后,还使用深度卷积层进行空间令牌混合。此外,Instance Normalization[41,42]和GELU[14]激活用于稳定分布和加速收敛。
2.4.双重修剪自我注意
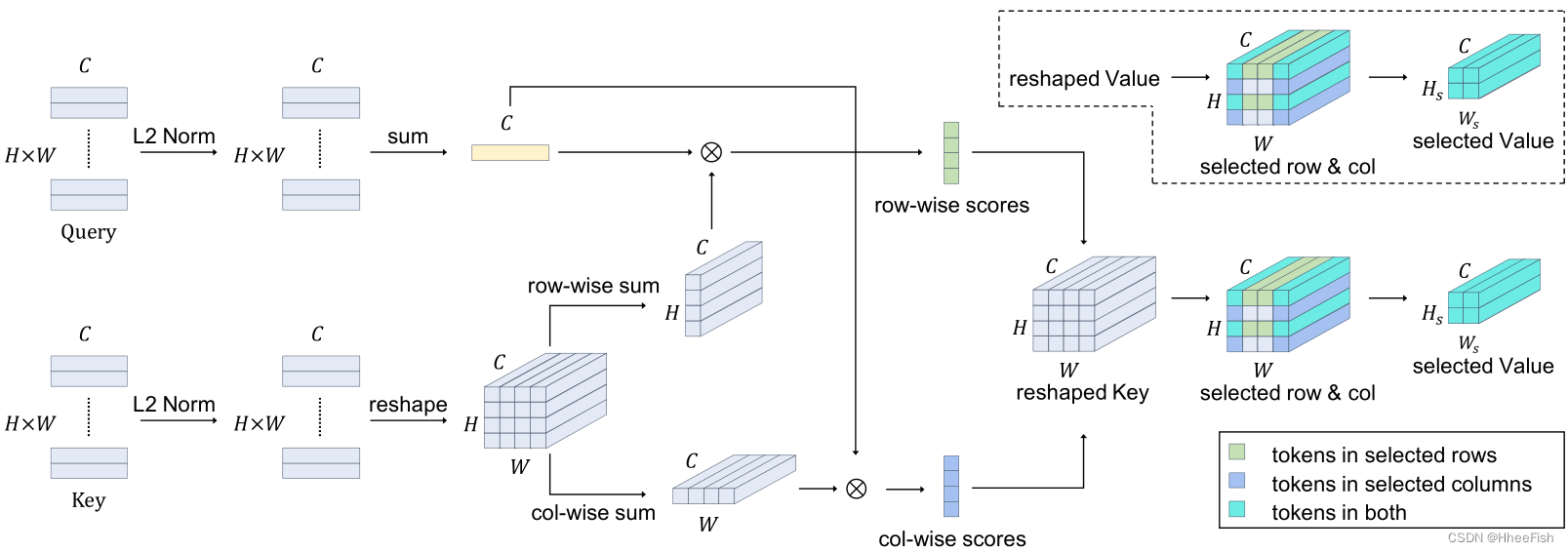
图5所示。DPSA中令牌预剪枝机制示意图,见3.4节。Key中的令牌按行和列分组,以计算贡献分数。贡献较小的行和列中的令牌将从Key和Value中删除。
为了简化描述,我们在本小节中采用单头DPSA来解释其机理。图5所示的DPSA的前向传播过程可以分解为token贡献测量和token修剪。
在DPSA中,标记kj在K∈ RN×C中的贡献定义为ΣNi=1aij。根据该定义,注意力图的计算应先于token贡献的计算。然而,这是不可接受的,因为设计DPSA的动机是在计算注意图之前对键和值进行预修剪。相反,我们计算按行或列分组的标记的贡献。因此,由于向量内积的分布性质,贡献度量的成本可以大幅降低。贡献度量公式如下所示,qi和kj是查询中的标记(Q∈ RN×C)和整形键(K′∈ RH×W×C):
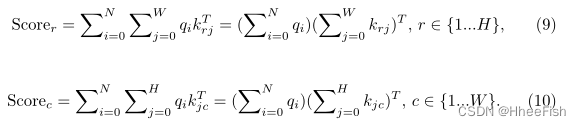
值得注意的是,只有在查询和密钥采用基于token的L2规范化时,才能以这种方式计算分组token的贡献。由于Q或K中标记向量的范数被归一化为1,因此注意图中的元素值被限制在该范围内(−1, 1). 通过该方法,可以在Softmax激活之前消除峰值token向量的负面影响
贡献分数的计算支持对行和列进行标记修剪。我们根据他们的贡献得分在行和列之间排名Scorer∈RH 和Scorec∈ RW。然后,选择贡献分数较高的行或列的索引。仅保留选定行和列中的标记,而修剪其他标记。此外,所选行数或列数Ns是一个超参数,在我们的实验中已设置为H的平方根。这些程序可描述如下:
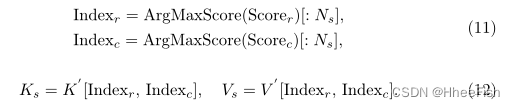
在这里,ArgMaxScore是通过参考行或列的贡献分数来对它们的索引排序。操作[:Ns]是选择n个排序最高的索引。然后我们使用这些索引来选择K '和V '∈R^H×W ×C中的token。修剪后,所选的令牌从K~s~∈RNs×Ns×C和V~s~∈RNs×Ns×C重构为K~s~∈RN2s ×C和V~s~∈RN2s ×C^。后续的计算过程类似于原来的自我注意。作为副产品,不再需要温度因子1/√Dh,因为令牌的修剪间接在Acos行中有元素值。为此,DPSA的计算方法如下:

在单头中,QKTs和AcosVs的计算复杂度降低到O(N N2s C), DPSA的内存空间复杂度降低到O(N N2s)。这里N等于H × W。贡献分数的计算成本相对而言可以忽略不计。由于实际设置Ns为√H,因此DPSA单头的整体计算复杂度和内存空间复杂度降低为O(N H C)和O(N H)。
2.5.目标
为了与现有的方法进行比较,我们可以选择CUT[34]和LSeSim[58]作为基线,用ITTR代替生成器架构。特别的是,由于我们的大多数实验都采用了CUT,我们将CUT的目标描述如下:
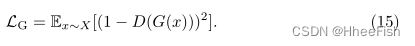
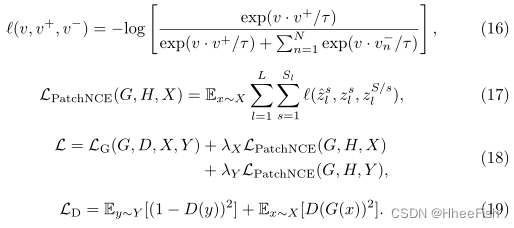
这里,X和Y是源域和目标域的真实图像。G和D是产生器和鉴别器。Hl是一个两层MLP网络,对应于发生器中选择的层ℓ。s∈S表示位置。zsl和zS/sl由Hl(Gl(X))产生,但位置不同。zˆsl由Hl(Gl(G(X))生产,与zsl的位置相同。λX和λY是超参数,在实验中均设为1。















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









