









ISPRS2020/云检测:Transferring deep learning models for cloud detection between Landsat-8 and Proba-V在Landsat-8和Proba-V间转移的云检测深度学习模型
0.摘要
准确的云检测算法是分析来自不同光学对地观测卫星的大数据流的必要条件。基于深度学习(DL)的云检测方案提供了非常精确的云检测模型。然而,训练这些模型为给定的传感器需要大量人工标记的样本数据集,这是非常昂贵的,甚至不可能在卫星还没有发射时创建。在这项工作中,我们提出了一种方法,利用一颗卫星的手动标记数据集来训练深度学习模型,用于云检测,可以应用(或转移)到其他卫星。考虑到获取信号的物理性质,我们提出了一种简单的迁移学习方法,使用Landsat-8和Proba-V传感器,它们的图像具有不同但相似的空间和光谱特征。
本文通过三种类型的实验来证明迁移学习的双向作用:(a)从Landsat-8到Proba-V,其中我们表明,仅使用Landsat-8数据训练的模型产生的云掩模比当前操作的Proba-V云掩模方法更准确5点;(b)从Proba-V到Landsat8,其中仅使用Proba-V数据进行训练的模型具有类似于公开可用的Biome数据集中的操作FMask的精度(87.79-89.77% vs 88.48%),以及©从Proba-V和Landsat-8联合到ProbaV,我们证明,联合使用这两种数据源,当很少有Proba-V标记的图像可用时,准确性提高1-10点。这些结果突出表明,利用现有的公开可用的云屏蔽标记数据集,我们可以为新卫星创建精确的基于深度学习的云检测模型,但无需收集和标记大量图像数据集。
1.概述
以监测地球系统和了解其动态为目标的新卫星和传感器的数量呈指数增长。在这些传感器中,光学仪器测量来自地球的电磁光谱的可见光和红外部分的辐射。来自光学传感器的数据用于广泛的应用,如估计生物物理参数,监测土地的长期使用,评估自然灾害后的损害,或监测城市地区等。在大多数这些应用中,云及其阴影的存在会影响信号,并被认为是不确定性的来源(Gómez-Chova et al., 2007)。然而,在单个场景中,云屏蔽可以手动处理,而在利用图像时间序列或多个位置的操作应用程序中,这是不可行的。因此,为了自动处理来自光学传感器的图像,精确和自动的云掩蔽算法是必要的。
云掩蔽算法为卫星图像中的每个像素分配一个清晰或模糊的二进制标签。云掩蔽的最基本方法是所谓的基于阈值的方法,它包括一组阈值,应用于图像的一个或多个光谱波段,或用于试图增强云的物理特性的提取特征。一般来说,阈值法简单易行,当卫星提供的光谱信息足够丰富时,阈值法在云分辨方面效果较好。当前基于操作阈值的云屏蔽方法包括FMask (Zhu和Woodcock, 2012;Zhu et al., 2015)用于Landsat-7和Landsat-8, Sen2Cor (Richter et al., 2012)用于Sentinel-2,以及对它们提出改进的几项近期工作(例如Zhai et al., 2018;邱等人,2019;Frantz等人,2018)。另一方面,基于机器学习(ML)的方法处理云检测作为一个统计分类问题。这些方法学习基于一组示例的云检测模型:观测数据对和标签。当训练数据的质量足够好时,基于机器学习的方法优于基于阈值的方法(GómezChova等,2007;Li等人,2019;Jeppesen等人,2019年)。用于云检测的机器学习方法可以进一步分为经典学习方法和深度学习方法。经典的方法是对训练集中的每个像素点提取一组人工选择的空间特征和光谱特征,然后优化分类器,根据这些特征区分这些像素点的标签。在最简单的情况下,只考虑两个类:云和清晰像素;然而,一些作品考虑了更广泛的范围,包括卷云、云阴影、冰/雪、水等(Hollstein等人,2016;休斯和海耶斯,2014;Wieland等人,2019年)。经典的机器学习方法通常是像素化的,在这种意义上,训练好的分类器可以独立地应用于特征提取后的测试图像中的每个像素。这些方法使用的分类器各不相同,包括:核方法和支持向量机(Azimi和Zekavat, 2000;Bai等人,2016;石田等人,2018;Gómez-Chova等,2010),神经网络(Torres Arriaza等,2003;Hughes和Hayes, 2014)或树和集合方法(Ghosh等人,2006;Hollstein等人,2016;2018年,Ghasemian和Akhoondzadeh;Wieland等人,2019年)。另一方面,用于云掩码的深度学习方法是端到端模型,输入是原始图像,输出是云掩码。如果将模型定义为一组堆叠的卷积运算,那么它就构成了一个完全卷积神经网络(FCNN) (Long et al., 2015)。在这些模型中,卷积滤波器的权值是需要优化的参数,因此模型可以学习直接从数据中利用周围像素的空间信息。应用于云探测的FCNNs已为若干卫星显示出最先进的性能,如Landsat-7 (Li等人,2019年)、Landsat-8 (Jeppesen等人,2019年;Li et al., 2019)、高分1 (Li et al., 2019)或MSG SEVIRI (Drönner et al., 2018)。
独立于所选的云屏蔽方法,该方法必须进行验证。对于大多数卫星传感器来说,这是云掩蔽算法发展的瓶颈,因为通常图像中没有关于云存在的独立和同时的信息。因此,为了进行定量验证,标准的方法是由人类专家手工标记一组像素或图像,这些像素或图像将构成地面真实值。该方法已在文献中广泛应用,如Landsat7 (Irish等人,2006年)、Envisat/MERIS (Gómez-Chova等人,2007年)、landsat8 (Foga等人,2017年)、Proba-V (Iannone等人,2017年)或Sentinel-2 (Coluzzi等人,2018年;Baetens等人,2019年)。在某些情况下,图像中只有一些像素被标记为多云或无云,而在其他情况下,图像中的所有像素都被标记,同时也捕获了云的空间分布。无论哪种情况,这一过程都不能避免错误:例如,在Scaramuzza等人(2012)中,作者报告了三个不同专家完全标记的11个Landsat-7场景的平均总体误差为7%。单独标记像素更准确,但它需要更高的奉献精神,因此标记像素的总量通常相当低。这使得结果在统计上不那么显著,当我们的目标是验证在不同季节和气候条件下全球有效的云检测算法时,这可能会成为一个问题。
此外,如果本文提出的云检测方法是基于机器学习的,那么除了验证数据外,还需要一组独立的、综合的标记样本来训练模型。如果目标是提供一种精确的全球云检测方法,那么这个训练集应该足够代表自然统计数据,包括来自不同土地覆盖、气候区和季节的数据。因此,对于机器学习方法来说,生成地面真相和开发云检测算法的努力是巨大的。机器学习方法的另一个缺点是,在卫星发射和数据可用之前,它们无法应用,因为开发模型需要具有相应地面真实情况的全面图像存档。由于这些原因,大多数卫星任务在发射时使用经验设计的基于阈值的云探测方法仍然是非常普遍的。之后,如果存在操作云检测性能问题,将原有算法替换为基于任务生命周期内获取数据的改进算法。这就是Proba-V任务(Sterckx et al., 2014)的情况,在这种情况下,欧洲航天局(ESA)最近组织了一个云检测轮罗宾实验(Iannone et al., 2017),旨在相互比较不同的云检测算法,以改进当前的操作算法(Wolters et al., 2015)
考虑到上述问题,我们可以得出结论,对于特定的卫星传感器,缺乏准确且具有代表性的地面真相将阻碍精确的机器学习模型的发展。然而,如今可用的地球观测数据量巨大,发布算法和人工标记的云掩码数据集越来越普遍,这是促进遥感领域研究的良好做法。特别是对于云检测,在Foga等人(2017)中,作者发表了超过250幅Landsat-7和Landsat-8的场景;在Mohajerani和Saeedi(2019年),他们发布了Landsat-8的额外38个场景;作品(Li et al., 2017, 2019)分别发表了108张高分1号图像和150张来自谷歌地球的高分辨率场景;和作品(Hollstein et al., 2016;Liu等人,2019;Baetens等人,2019年)也发布了哨兵-2的人工标记云掩码。在这种情况下,我们建议利用现有标记数据集中包含的丰富信息,在类似的卫星之间转移关于问题的以前的知识。这种方法允许我们解决机器学习方法的一些缺点。首先,从方法论的角度来看,为新卫星建立精确的云检测模型所需的人工标记训练集的大小大大减少。其次,从操作的角度来看,由于现有卫星的训练数据已经可用,所以可以在卫星发射前开发基于机器学习的云检测算法,因此可以从第一天开始应用。
本文以空间分辨率不同、光谱波段不同的Proba-V卫星和Landsat-8卫星为研究对象,利用人工标记的云探测数据集对模型进行训练和评估。Proba-V是一个空间分辨率中等的小卫星,只有4个光谱波段(Sterckx et al., 2014);我们将利用最近ESA Round Robin实验中人工标记的数据集进行云检测(Iannone et al., 2017)。与Proba-V相比,Landsat-8 (Irons et al., 2012)具有更高的空间和光谱分辨率,并且如前所述,存在大量人工标记的云探测图像集合(美国地质调查局,2016a,b)。
我们提出的Landsat-8和Proba-V之间的知识转移方法基于两个部分。第一个是对Lansdsat-8数据进行域适应变换,使其在光谱和空间特征上与Proba-V图像相似。我们的目标是在两个数据源之间进行简单的基于物理的转换,以便于从可用的手动标记数据集(即源域)到我们希望检测云的卫星图像(即目标域)进行迁移学习。第二部分是一个完全卷积的神经网络模型,能够从训练数据中学习尽可能多的光谱和空间信息。FCNNs擅长图像分割任务(Xie等人,2017;Chen等,2018a,b;林等,2018;Drozdzal等人,2016;Breininger等人,2018;Schuegraf和Bittner, 2019),他们以一种分层的方式整合光谱信息和空间信息:在我们看来,空间信息尤其在Proba-V的背景下至关重要,它的光谱波段数量有限。
使用域适应转换和FCNN模型,我们进行了三种类型的迁移学习实验:(a)从Landsat-8到Proba-V的转导迁移学习,其中我们只使用Landsat-8注释数据来开发一个在Proba-V域工作的模型;(b)从Proba-V到Landsat-8的转导迁移学习,其中标记的Proba-V数据用于训练Landsat-8的云检测模型;©从Landsat-8到Proba-V的归纳迁移学习,其中我们使用少量Proba-V标记的图像与带注释的Landsat-8数据集一起生成Proba-V的云检测模型。
在这些实验中,我们表明所提出的模型仅在Landsat-8数据(之前的项目a)上训练,其准确性至少比目前的Proba-V操作云检测算法高出5个点(Wolters等人,2015)。该模型没有使用任何Proba-V图像进行训练。在更具挑战性的Proba-V向Landsat-8转移方向中,仅使用Proba-V数据(前项b)训练的模型,其工作在低10倍的空间分辨率尺度上,仅比最先进的Landsat-8深度学习模型精度低2点(Jeppesen等人,2019;Li等人,2019年),在分析的数据集上,它与可操作的FMask (Zhu和Woodcock, 2012年)一样准确。最后,利用来自两个传感器的标记数据的模型的性能(前一项c)表明,仅使用少量Proba-V图像训练的模型的准确性明显低于将这些少量Proba-V图像与可用的Landsat-8数据联合训练的模型。特别地,结果显示,当使用两种数据源联合训练网络时,根据使用的Proba-V数据量,检测精度提高了1到10个点。
本文的组织结构如下。在第2节中,我们在当前的文献背景下构建了我们的建议,并详细介绍了我们的贡献。在第3节中,我们介绍了基于物理的图像转换方案,该方案有助于传感器之间的迁移学习、迁移学习方案和所提出的网络架构。在第4节中,我们展示了Landsat-8和Proba-V数据集。第5节为实验设计,详细描述迁移学习实验。在第6节中,显示并讨论了结果。最后,第7节给出结论。
2.方法
在本节中,我们首先介绍Proba-V和Landsat-8的特性。然后,我们提出了两种迁移学习(TL)方案:第一种将用于将学习从Landsat-8迁移到Proba-V,第二种将学习从Proba-V迁移到Landsat-8。这些TL计划分别指定如何在源和目标领域中进行培训和测试。根据域适应是从源域到目标域还是反向进行的,每种方案可以应用于不同的情况。然后,我们详细介绍了将在两种TL方案的实验中使用的域适应转换。该转换是基于传感器的仪器特性,以适应Landsat-8图像的Proba-V域。最后,第3.4小节解释了实验中使用的完全卷积神经网络架构。在本文中,我们主要关注Landsat-8和Proba-V的情况,然而,这种迁移学习的过程可以在其他具有类似特征的传感器中重现,因为我们只需要两个传感器有一些响应重叠的光谱波段。
2.1.Landsat-8和Proba-V传感器
Proba-V是一颗用于全球植被监测的小型卫星(Sterckx et al., 2014)。它于2013年发射,以弥合Envisat/MERIS、SPOT植被和最近发射的Sentinel-3之间的差距。Proba-V是一颗预算有限的实验卫星,其设计规模比之前的MERIS和SPOT小得多。它获得了可见光(BLUE和RED)、近红外(NIR)和短波红外(SWIR)四个波段的大气顶部(TOA)辐亮度。Proba-V有三个摄像头:一个中央摄像头,指向最低点,另外两个在侧面。这三个摄像机为Proba-V提供了较宽的视距,可以实现1-2天的短重访周期。中央(最低点)相机在100米(从90到110米)获取数据,而两侧相机的空间分辨率范围从110米到350米。2A级操作处理利用Lanczos插值将这些不同分辨率的数据投影成统一的333米板块Carrée投影(Dierckx等人,2014)。由于频谱信息的有限性,Proba-V中的云检测具有特殊的挑战性。目前运行的基于阈值的Proba-V云检测算法(Wolters et al., 2015)经过多次修改,仍然存在一些缺陷,如对光照和观察几何形状的依赖、边缘检测和大量的调试误差(Stelzer et al., 2016)
Landsat-8 (Irons et al., 2012)以15天的复视周期测量电磁光谱11个波段的TOA辐射。Landsat-8有两个传感器:业务陆地成像仪(OLI),从9个光谱波段以30米分辨率收集数据;热红外传感器的目标是热成像,它可以在100米的空间分辨率范围内测量另外两个波长的数据。与Proba-V相比,有两个因素使Landsat-8的云检测问题更容易解决。首先,OLI传感器的9波段是专门为探测卷云而设计的。其次,热带对云特别有鉴别性,因为一些云明显比下垫面冷。FMask等算法(Zhu等人,2015)利用这些事实设计了简单而稳健的基于阈值的云检测算法,可以在全球范围内应用。
2.2.迁移学习策略
正如我们在前面的第2节中所讨论的,迁移学习包括利用来自一个(源)领域的数据来解决类似但不同(目标)领域中的问题。但是,根据源域和目标域之间的关系,执行TL有不同的可能性。在本研究中,我们考虑了两种不同的TL方案。这些方案假设我们已经在源域(S)标记了数据,我们希望在目标域(T)进行预测,并且可以在两个域之间应用域适应变换(DA)。各个TL方案的适用性取决于域适应转换的方向:
- 方案1:目标域中的训练模型。在本例中,我们有一个从源域到目标域的域适应转换。我们首先使用域适应变换将标记数据从源域适应到目标域,然后使用适应数据训练模型。由于图像和标签都被转换到目标领域来训练模型,所以将学习到的模型应用到目标领域的数据是很简单的(因为模型已经在这个领域中构建了)。另一方面,如果我们想在源域中测试模型,我们需要将源域输入转换为目标域,应用预测模型,并将预测转换回源域。
- 方案2:在源域中训练模型。该方案基于直接在源域中训练模型。在该方案中,我们进行了从目标域到源域的域适应变换。为了将模型应用于目标域的新数据,必须首先将输入样本应用于源域,然后应用预测模型,最后将预测转换回目标域。注意,在这种情况下,在来自源域的数据上测试模型是直接的。
在本研究中,我们将使用Scheme 1进行Landsat-8到Proba-V的迁移学习,使用Scheme 2进行反向迁移学习。方案总结如图1所示。特别地,在这项工作中,X是卫星图像(无论是Landsat或Proba-V);Y是云掩码标签;DAX表示从Landsat-8图像到Proba-V(章节3.3)的适应;DAY是通过增加或减少掩码来调整标签(第3.3节);f为预测模型,Y=f(X),使用完全卷积神经网络(第3.4节)实现。此外,图1说明了训练模型的数据转换,以及在来自目标域或源域的数据集中测试它们的过程。
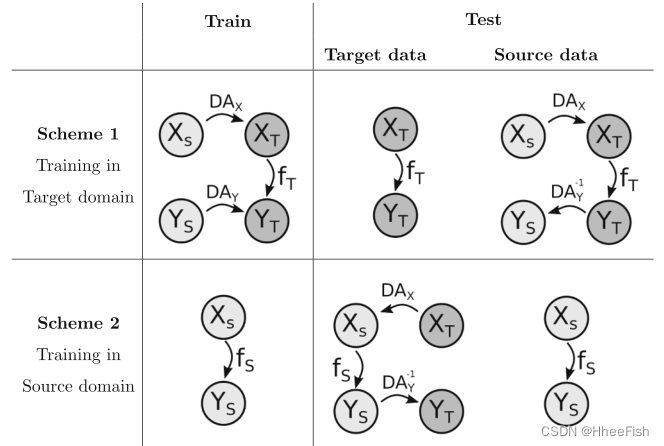
图1所示。迁移学习计划。在两种方案中,我们都假设源(S)域中有标记数据,但我们希望在目标(T)域中进行预测。图像X和标签Y的改编分别使用DAX和DAY转换来执行。训练后的ML模型分别用fT或fS表示,这取决于它是在源域还是在目标域训练。
2.3.Landsat-8至Proba-V域适配
为了应用TL方案(第3.2节),我们需要一个程序将图像从一个域调整到另一个域(图1中的DAX)。虽然有大量方法可以从数据中学习域自适应转换(例如,Tuia等人,2014年;Hoffman等人,2018年;Csurka,2017年),但在本文中,我们采用的方法仅基于采集信号的物理特性。学习转换意味着从两个传感器获得数据来训练模型,在某些情况下可能不可行(例如,如果我们的目标卫星尚未发射)。因此,本研究的几个部分假设没有来自目标域的数据(或很少)。在可以学习领域适应转换的情况下,这种更简单的方法可以作为比较此类方法的基线。当两个域中的采集信号之间存在频谱重叠时,我们提出的变换通常可以应用。在我们的特殊情况下,这些域是Proba-V和Landsat-8卫星图像。在两种可能的域适应转换(从Landsat-8到Proba-V或从Proba-V到Landsat-8)中,鉴于Landsat-8和Proba-V图像的特点,从Landsat-8到Proba-V的转换似乎更自然,因为它从较高的空间和光谱分辨率到较低的空间和光谱分辨率。相反的转变也是可能的;然而,从Proba-V图像插值到30米空间分辨率是一个不适定问题,插值图像不太可能具有陆地卫星-8图像的空间光谱质量。因此,在所有的论文中,我们将只考虑从Landsat-8到Proba-V的域自适应,以转换TOA反射图像。
我们提出的从陆地卫星8到Proba-V的图像转换(图3)基于两个传感器的仪器特性。该转换包括两个适应步骤:首先,选择更合适的光谱带,其次,我们缩放Landsat-8图像以匹配Proba-V的空间特性。光谱转换考虑了两颗卫星的光谱响应函数(SRF)。它基本上包括选择两颗卫星之间的重叠光谱带,并最终将其贡献作为其光谱重叠的函数进行加权。图2(左)显示了Proba-V(实心)和Landsat-8(虚线)中常见波段的光谱响应函数。在SWIR波段和红色波段的情况下可以看到良好的一致性。在近红外波段的情况下,Proba-V的光谱响应更宽,其峰值与Landsat-8 B5波段不一致,这可能导致检索到的辐射差异。最后,对于Proba-V蓝色波段,在同一光谱范围内,陆地卫星-8上有两个波段。在这种情况下,Landsat-8的B1和B2波段的贡献根据光谱响应的重叠面积进行加权,如图2(右)所示,其对应于B1的25%和B2的75%。

图2。左:Landsat-8和Proba-V的光谱响应。右:光谱蓝色区域的缩放;我们根据陆地卫星-8的B1和B2波段与ProbaV光谱响应函数的重叠来加权其贡献。
第二个自适应步骤改变了Landsat-8图像的空间分辨率。为了尽可能地类似Proba-V的空间特性,我们将陆地卫星8号图像放大到更粗的Proba-V分辨率。首先,我们使用每个Proba-V谱带的点扩散函数(PSF)将陆地卫星-8观测值转换为最低点的标称Proba-V空间分辨率。对于蓝色、红色和近红外通道,Proba-V中心摄像机的地面采样距离(GSD)约为96.9米,而SWIR中心摄像机的分辨率为184.7米(Wouter Dierckx personal communication(Dierckx等人,2014),2018年6月26日)。SWIR PSF的宽度约为其他频带的PSF的两倍,这强调了一个事实,即可以对每个频带应用不同的空间自适应。这些波段的功率谱函数被建模为二维高斯滤波器,应用于30米分辨率的陆地卫星-8波段。通过每3个像素取1个,将过滤后的图像放大到最低点的标称90米分辨率。最后,应用Lanczos插值将图像放大到最终333 m Proba-V分辨率。请注意,Lanczos是Proba-V地面段处理中使用的插值方法,用于将获取的原始Proba-V数据提升到333 m平板车网格(Dierckx等人,2014)。
我们使用基本相同的程序转换了Landsat-8数据集的相关地面真实值(DAY在图1中)。对于二进制云掩模,我们应用高斯滤波、 3×3上采样和lanczos插值生成333 m分辨率的图像;然后,应用阈值对图像进行二值化,对于混浊像素,阈值设置为0.5。对于将云掩码从333 m分辨率的Proba-V转换到30 m分辨率,我们使用简单的双三次插值。图3描述了Landsat-8图像和相关云遮罩的光谱和空间转换。

图3所示。将Landsat-8产品和掩模改造成类似Proba-V特性。
2.4.全卷积神经网络
完全卷积神经网络(FCNN)是学习映射函数(图1中的fS和fT)的首选模型。FCNN是最先进的图像分割模型,因为它能够利用输入数据的空间光谱信息。当提供大量训练数据时,FCNNs在几个图像分割任务上显示出非常高的精度水平(Chen等人,2018a;林等,2018;Chen等人,2018b)。尽管他们成功的原因仍然知之甚少(Zhang et al., 2017;Szegedy et al., 2014),众所周知,空间光谱卷积堆栈的层次结构是视觉系统的良好先验(Yosinski et al., 2014)。此外,许多研究表明,它们通常比手动设计空间光谱特征的分类方法获得更高的性能(Wieland等人,2019;Mateo-García et al., 2017)。
在这项工作中,全卷积神经网络解决了一个标准的多输出二值分类问题,其中输入为4波段图像,输出为二维地图。该输出的值介于0到1之间,可以解释为基础像素的云概率。卷积滤波器的叠加集寻求利用附近像素的空间信息来提供每个像素的云掩码,这在光谱信息减少的情况下至关重要,如Proba-V只有4个光谱带。
自图像分割的深度学习应用爆发以来,全卷积神经网络设计一直在不断发展(Farabet等人,2013;Long等人,2015;Chen等人,2015)。在大多数应用中,FCNN架构包括一个编码器模块,该模块由卷积滤波器组成,卷积滤波器多次汇集图像,再加上一个解码器模块,该解码器模块将减少的特征向量解调到原始图像大小,以符合预测。由于所有运算都是卷积和逐点非线性,因此该网络可以应用于任意大小的图像,推理时间很快。Ronneberger等人(2015)提出的U-Net架构是一种众所周知的完全卷积架构,已应用于从计算机视觉到医学图像的多个领域(Ronneberger等人,2015;Drozdzal等人,2016;Breininger等人,2018)。它还被广泛应用于遥感(Schuegraf和Bittner,2019年;Wieland等人,2019年;Jeppesen等人,2019年;Drönner等人,2018年),尤其是遥感网络的云检测(Jeppesen等人,2019年),以及陆地卫星8号的Wieland等人(2019年)。它有5个池化/非池化阶段,并在相同分辨率的特征映射之间添加跳过连接。总的来说,U-Net在概念上简单但准确,并提供快速预测,这在遥感特别是云检测中是强制性的。在这项工作中,我们通过使用可分离卷积层(Chollet,2017),将池化步骤的数量从五个减少到两个,并通过将网络的输出替换为二进制分类而不是多类分类,来调整U-Net架构。这些修改遵循的假设是,333米分辨率的云检测可以用较少的参数和较小的降尺度步骤来解决。Landsat-8的遥感网络(Jeppesen等人,2019)使用了5个降尺度步骤,而我们使用了2个,这是有意义的,因为它们使用的是30米分辨率的数据。

图4所示。基于Ronneberger等人(2015)提出的用于云检测的FCNN架构:输入是4波段TOA反射图像
图4显示了拟议架构的方案。编码器部分由两个块组成,两次3×3可分离卷积、批量归一化(Ioffe和Szegedy,2015)和ReLU激活,然后是2×2最大池。瓶颈也是两个3×3可分离卷积、批量归一化和ReLU激活的块。该解码器由两个转置卷积块组成,转置卷积块与编码器的先前激活连接,以及两次3×3可分离卷积、批量归一化和ReLU激活。最后,应用1×1卷积来获得通过sigmoid激活获得最终云概率的输出。总之,我们的FCNN架构有95769个可训练参数,并执行2.18 M浮点运算来计算256×256图像的云掩码。与Jeppesen等人(2019)、Wieland等人(2019)提出的U-Net架构相比,我们提出的架构的参数减少了99%,浮点运算减少了92%。U-Net有大约780万个参数,需要27.97 M浮点运算来计算256×256图像的云掩码
在这项工作中,使用了两种不同的训练策略:网络要么从头开始训练,要么使用微调。从头开始训练是指随机初始化网络的权重,而微调对应于使用先前训练网络的权重进行初始化。由于神经网络的优化通常是一个非凸问题,权重的不同初始化可能导致损失函数的不同局部最小值,这可能具有不同的测试性能。
一旦权重初始化,我们使用小批量随机梯度下降来最小化相对于这些权重的标准二进制交叉熵损失。该损失定义为:

其中,y^i,j,k是批次中第i个图像的(j,k)像素中的预测网络输出;yi,j,k是其相应标签中的地面真值;B是批量;S1×S2是图像的大小。
3.标记数据集
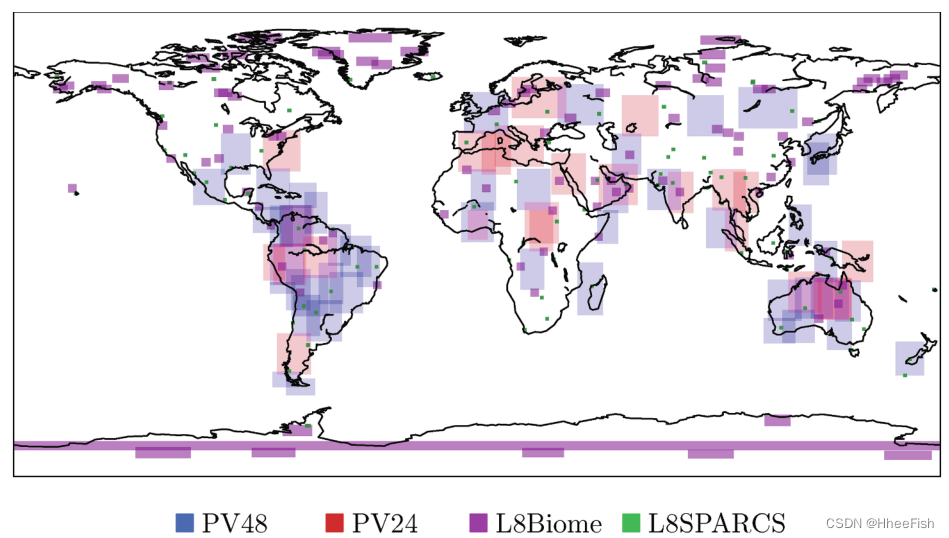
图5。使用的陆地卫星8号和Proba-V数据集的位置。每个图像都有一个手动生成的云掩码。
本节描述了用于Landsat-8和Proba-V的标记数据集。手动注释的云掩码对于训练和验证设计用于全球、不同土地覆盖和不同大气条件下的云检测算法至关重要。在这项工作中,我们将公开可用的L8Biome(美国地质调查局,2016b)和L8SPARCS(美国地质调查局,2016a)数据集用于Landsat-8,并将在欧空局循环演习(Iannone等人,2017)背景下开发的数据集的改进版本用于Proba-V(图5)。
3.1. 陆地卫星-8数据集和地面实况
如前所述,在Landsat-8和Proba-V中探索TL的动机之一是具有相应云掩码的公共Landsat-8图像数据集的可用性,这些图像数据集通过监督机器学习算法用作地面实况。我们使用Foga等人(2017)提供的开放获取L8Biome(美国地质调查局,2016b)和L8SPARCS(美国地质调查局,2016a)数据集。
L8Biome数据集由Foga等人(2017)的作者开发。它包含96个Landsat-8 1T级产品,全部使用三类进行标记:透明云、薄云和云。我们融合了最后两个(薄云和云)以获得二元云掩码。产品分布在世界各地,涵盖8个主要生物群落。每个产品的平均尺寸为8000×8000像素。对于一些实验,我们使用了与Li等人(2019)相同的训练测试分割,分别包含73个训练和19个测试图像。
收集了L8SPARCS数据集,以验证Hughes和Hayes(2014)提出的方法。它包含80个陆地卫星-8 1T级子场景。他们使用五种不同的类别手动标记:云、云影、雪/冰、水、洪水和晴空。为了这项工作,我们将所有非云类(云阴影、雪/冰、水、洪水和晴空)合并到了clear类中。每个亚场景是1000×1000像素,因此与L8Biome数据集相比,数据量要低得多。
3.2.Proba-V数据集和地面实况
Proba-V数据集由作者手动标记的72个Proba-V 2A级产品(处理版本v101)组成。该数据集是在欧空局循环演练框架内创建的数据集的更正和扩展版本(Iannone等人,2017),Mateo García等人(2017)、MateoGarcía和Gómez Chova(2018)也使用了该数据集。在这项工作中,两位不同的专家按照手动程序对手动标签进行了广泛改进。72个场景中的所有像素都被标注为多云、清晰或不确定。对于不确定像素,人类专家无法清楚地确定它们是被云污染的还是无云的。因此,不确定像素既不用于训练也不用于测试目的。
为了评估地面实况的质量,独立专家还对来自12个不同图像的950个像素进行了逐像素标记(Stelzer等人,2017年)。这些像素级标签与完全标记的场景之间的差异为6.62%。该误差与Scaramuzza等人(2012年)报告的7%误差相似。此外,对差异的进一步分析表明,它们主要出现在海洋上方的半透明薄云中,在那里,即使是有经验的用户也很难区分云。然而,该误差构成了模型使用这些标签可以实现的误差下限;i、 e.我们无法用该数据集真正区分误差低于6%的模型。
我们将Proba-V数据集分为训练和测试。列车数据集由48个图像组成:我们将此数据集称为PV48。测试数据集由剩余的24个产品组成,我们将其称为PV24。图5显示了培训和测试产品的位置。这些贴有标签的产品也可供检查。3.
4.实验设置
实验设计试图回答几个问题,这些问题可以概括为三个:
(1)使用Landsat-8数据训练的模型能否适应Proba-V领域的工作?
(2) 使用Proba-V图像(333米分辨率)训练的模型能否应用于陆地卫星-8图像(30米分辨率)?
(3)合并源域和目标域的数据是否会提高训练模型的准确性?
因此,问题1和2与transductive TL问题相关,而问题3涉及归纳TL。为了回答这些问题,我们进行了表1中总结的两组实验:一组用于transductive TL,另一组用于归纳TL。
在transductive TL中,我们探索了两种不同的场景:(1)仅具有Landsat-8标记数据和(2)仅具有Proba-V标记数据。对于每个场景,一旦模型经过训练,我们将执行两项任务:首先,我们在源域中验证模型,然后在目标域中评估它们,在目标域中它们被设计用于工作。如前所述,在第一种场景中,我们将使用TL方案1,在第二种场景中,我们将使用TL方案2(第3.2节)。
归纳性TL实验回答了上述的第三个问题。它包括同时使用Proba-V数据和自适应Landsat-8数据在Proba-V域中训练模型。使用3.3节解释的空间光谱变换将Landsat-8数据转换到Proba-V域进行训练。

表2 根据传感器之间的转移学习方向(即用于训练和测试的数据),不同训练模型的实验设置。
各实验的TL模型如表2所示。模型表示为TLSat,SR,其中Sat指的是训练数据来自的卫星(L8, Landsat-8和PV, Proba-V);SR是指训练模型时使用的空间分辨率,可以是30米(Landsat-8分辨率)或333米(Proba-V分辨率)。注意,当卫星是L8,分辨率为333 m时,这意味着,为了训练模型,L8图像和地面真实值已经使用3.3节中的空间-光谱域适应转换到Proba-V域。
4.1. 转导迁移学习:从Landsat-8到Proba-V
在这个实验中,我们假设我们只使用Landsat-8的标记数据进行训练。在这个设置中,我们训练了两个遵循TL方案1的模型。第一个模型TLL8,30只使用光谱变换作为域适应步骤,而不使用空间变换(3.3节)。第二个模型,TLl8,333,使用了光谱和空间两个步骤,使Landsat-8标记的图像适应Proba-V域。两种模型都可以直接应用于Proba-V数据。对于第一个模型,这在技术上是可能的,尽管它是在不同空间分辨率的图像上训练的,因为模型是基于完全卷积架构(第3.4节),因此它可以应用于任何大小的图像。
为了确保模型正常工作,我们对Landsat-8数据进行了初步测试。注意,这是一种现实的情况,因为我们假设只有来自该域的标记数据。在Landsat-8域中测试第一个模型很简单(即预测的云掩码的空间分辨率与原始模型相同),而要在Landsat-8域中测试第二个模型,我们必须撤销空间适应。为了做到这一点,我们通过简单的双三次插值(第3.3节),将得到的云遮罩缩小到30 m分辨率。具体来说,我们对Landsat-8源域进行了两次测试,以便与工作进行比较(Li等人,2019年和Jeppesen等人,2019年):在第一次测试中,我们按照Li等人(2019年)的实验设置,包括使用来自L8Biome数据集的73张图像进行训练,其余19张用于测试4。第二种是按照Jeppesen等人(2019)的设置,使用所有L8Biome图像进行训练,使用L8SPARCS进行测试
一旦我们检查了训练的模型在源域工作,我们就评估它们在目标域的性能(即来自PV24测试数据集的ProbaV图像)。通过这个实验,我们想证明(1)从Landsat8到Proba-V的转导迁移学习是有效的,(2)**两个域适应步骤(光谱和空间)**都需要使迁移学习成为可能。
4.2. 转导迁移学习:从Proba-V到Landsat-8
假设我们只有Proba-V标记的数据用于训练(Proba-V是源域,Landsat-8是目标域),我们将应用TL Scheme 2(章节3.2)。该模型(TLPV,333在表2中)首先使用PV48和PV24数据集在Proba-V域中进行训练和评估。随后,我们对其在Landsat-8图像中的性能进行了评估。为了将该模型应用于Landsat-8图像,TL方案2包括:(1)对Landsat-8图像应用空间-光谱域适应变换(第3.3节),(2)应用Proba-V训练模型,(3)通过简单的双三次插值将得到的云掩膜预测降尺度到30 m分辨率。
4.3. 归纳迁移学习:从Landsat-8到Proba-V
最后,在归纳块中,我们评估了用来自Proba-V和所有Landsat-8数据的越来越多的数据训练的几个模型。请注意,与转导TL实验的第一个场景一样,我们使用TL Scheme 1在目标域中训练模型;因此,从Proba-V中加入额外的标记图像用于联合训练实验是很简单的。我们分析了两种不同的训练策略:(1)从头开始训练模型,同时包括Landsat-8和Proba-V图像,(2)使用模型TLL8,333的参数初始化模型,并使用Proba-V图像微调模型。此外,我们还与仅用相同的Proba-V图像从零开始训练的模型进行了比较。所有模型的训练细节可以在附录A中找到。
5.实验结果与讨论

在本节中,我们讨论了第4节中描述的不同迁移学习实验的结果,并总结在表1中。我们首先展示了转导迁移学习的结果:我们从Landsat-8到Proba-V的TL(章节6.1)开始,然后从Proba-V到Landsat-8的TL(章节6.2),然后是与转导模型的鲁棒性相关的结果(章节6.3),最后总结了两个领域中的所有转导迁移学习模型,并与独立的最新模型进行了比较(章节6.4)。最后,我们给出了归纳迁移学习的结果(第6.4节)。
为了对模型进行测试,我们在Proba-V域中使用PV24数据集。在Landsat-8领域,我们使用L8SPARCS和L8Biome数据集,当它们不用于训练时。测试总是在给定域的本机解析中执行;因此,对于Proba-V,预测掩码是在333 m分辨率域上获得的,对于Landsat-8,预测掩码是在30 m分辨率Landsat-8图像上获得的。
5.1. 转导迁移学习结果:Landsat-8到Proba-V
在本小节中,我们将展示4.1节中解释的实验设置的结果。首先,我们展示了我们模型的结果,使用Li等人(2019年)对L8Biome数据集使用的相同的训练测试分割进行评估,并将我们的结果与他们的结果进行比较。然后,我们展示了使用来自L8Biome数据集的所有图像训练模型的结果,这些结果首先在Landsat-8领域使用L8SPARCS数据集进行评估,然后在目标Proba-V领域使用PV24测试数据集进行评估。本节的目标是证明使用提出的空间-光谱域适应在Landsat-8和Proba-V之间的迁移学习是有用的。此外,一个互补的结果是,仅使用谱域适应是不足以获得一个准确的模型。
我们在L8Biome数据集上使用Li等人(2019)提出的训练试验分割方法评估这些模型。特别是,我们使用相同的73张图像进行训练,19张用于测试,因此结果可以直接与(Li等人,2019)进行比较。我们按照TL方案1训练了两个模型:第一个模型TLL8,30只使用光谱步骤作为域适应变换,第二个模型TLL8,333,使用整个光谱和空间适应(参见2.3节)。值得强调的是,为了将模型应用于Landsat-8图像,必须先对图像进行相应的域适应变换。应用模型之后,必须将相应的云掩码转换回源域。在TLL8,333的情况下,掩模使用双三次插值被缩小到30米。表3显示了Landsat-8测试图像的结果。可以看到,这两个模型具有相似的性能。虽然模型TLL8,333在不同的空间分辨率下工作,但其精度只比直接使用30m分辨率数据的模型(TLL8,30)低一个点。

表3 Li等人(2019年)使用的L8Biome数据集的19张测试图像的结果。提出的模型(TLL8,333和TTLL8,30)和Li等人(2019)的模型(MSCFF)都使用L8Biome数据集的相同73张图像进行训练。
表3中包含了MSCFF网络(Li等人,2019年)和FMask网络(Zhu等人,2015年)的结果,以便进行比较。对于MSCFF网络,我们考虑了使用所有波段和仅使用NIR、Red、Green和Blue波段(NRGB)的结果。我们可以看到,我们在30m分辨率下训练的网络比使用NRGB波段的MSCFF具有相似的性能,这表明我们的FCNN架构比MSCFF压缩了相似的信息量,尽管它的可训练参数和池化步骤要少得多。此外,使用333 m分辨率数据(TLL8,333)训练的网络比使用所有波段的MSCFF精度低2点(Li等人,2019年)。然而,对于这19幅图像,它提供了比可操作的Landsat-8云检测算法FMask (Zhu et al., 2015)更精确的云掩码。这强调了333 m分辨率的图像保留了足够的信息,可以为30m的产品提供准确的云掩膜;也就是说,采用的升尺度和降尺度方法的隐式平滑效应不会影响整体的云检测精度——尽管在云边界可能会有一些影响。
由于这些初步结果令人满意,我们使用第4.1节中描述的L8Biome数据集的所有图像从头开始重新训练了这两个网络。为了分析网络对不同权值初始化的鲁棒性,我们使用不同的随机种子训练了10个使用光谱空间域自适应(TLL8,333)的网络副本。稳健性结果将在第5.3节中进一步分析。
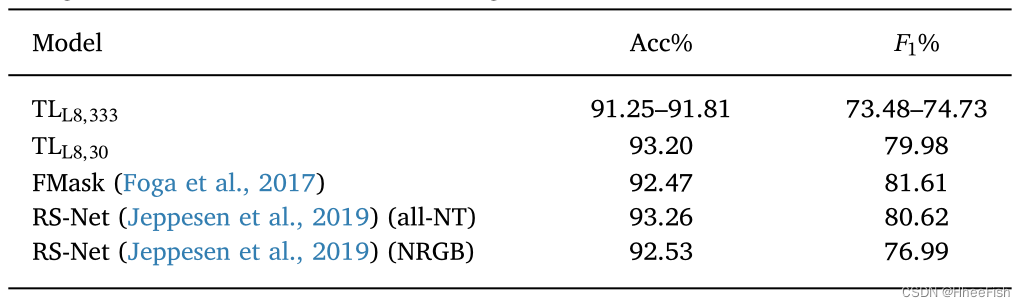
表4 使用L8Biome数据集训练并使用L8SPARCS数据集在源Landsat-8域测试的模型结果。RS-Net模型和我们的模型都使用L8Biome数据集进行训练。
表4显示了在Landsat-8 L8SPARCS数据集上测试这些模型的结果。首先,我们看到,正如预期的那样,10个TLL8,333拷贝的结果在10次不同的运行中表现出较低的可变性。这与我们的假设一致,即不同的权重初始化会导致一致的训练和测试精度值。关于网络性能,使用空间-光谱域适应(TLL8,333)训练的网络比工作在30m分辨率的网络(TLL8,30)和工作的RS-Net网络(Jeppesen等人,2019)约低2点。对于RS-Net,我们再次考虑使用RGB波段加近红外(NRGB)的结果,以及使用除热(all- nt)以外的所有波段的结果,热(all- nt)是Jeppesen等人(2019)的L8SPARCS数据集表现最好的模型。在这种情况下,还值得一提的是,仅使用光谱域适应变换(TLL8,30)的网络几乎与RS-Net (Jeppesen et al., 2019)具有相同的精度,甚至(a)该网络的可训练参数减少了99%,(b)它使用更少的Landsat-8光谱波段。

表5使用L8Biome数据集训练的模型的结果,以及使用PV24数据集在ProbaV目标域上测试的结果。
一旦我们证明了在迁移学习框架中训练的模型具有具有竞争力的性能,即使是专门为源领域训练的模型,我们也会评估模型在目标领域的性能。表5显示了Landsat-8模型对Proba-V数据的迁移学习结果。特别地,该表5显示了使用Landsat-8 L8SPARCS数据集训练的模型的测试结果,并使用PV24测试集在Proba-V域中进行了测试。首先,我们发现使用空间-光谱域自适应(TLL8,333)训练的模型比使用Operational Proba-V云掩码训练的模型更精确。这表明提出的策略可以用于设计精确的ML模型,甚至在卫星发射之前。另一方面,TLL8,333提供的结果比仅使用光谱变换训练的模型(TLL8,30)更精确8到10点。这说明FCNN学习的空间模式依赖于空间分辨率,因此,为了在不同空间分辨率的传感器之间转移学习,需要进行考虑空间尺度的域适应变换。10次运行网络的结果显示了一种不寻常的行为:对于不同的随机初始化,云检测精度和F1得分在3点以内变化。这种对初始化的依赖与表4所示的Landsat-8域中这10次运行的结果形成对比。我们的假设是,在提出的适应后,Landsat-8适应数据的分布与真实的Proba-V分布之间仍然存在数据转移(Torralba和Efros, 2011)。在我们看来,对于真实的Proba-V域中的一些图像,网络可以进行外推。因此,对这些区域的预测对于某些网络是正确的,而对于其他网络则是错误的,这取决于它的初始化。然而,这种隐式外推并不会显著影响预测的质量;我们可以看到,即使在最糟糕的情况下,使用空间光谱适应的Landsat-8数据训练的网络,也在很大程度上优于Proba-V操作云检测算法(Wolters等人,2015)。


图6所示。地面真实数据与PV24测试数据集的三个测试地点应用的三个模型之间的差异。
最后,图6给出了三种不同模型的云掩码的一些说明结果,这些都应用于未用于训练的Proba-V图像。这些图像被用来突出关键的云探测案例,如云冰识别、明亮的不透水表面、沙子和沿海地区。我们用白色表示模型预测与地面真实值的一致性,用橙色表示遗漏误差(模型预测清晰,地面真实值多云),用蓝色表示委托误差(预测表明云层和地面真实值清晰)。第一个例子展示了在沙滩和水中操作PV云面具的调试错误。卷积模型没有出现这些问题,尽管在L8Biome数据集上训练的模型仍然有几个主要在云边界的遗漏错误。第二个例子展示的是在南美洲安第斯山脉的冬季采集。在这种情况下,运算算法在卷积模型正确检测的雪山区域产生委托误差;特别是用Proba-V图像训练的模型,TLPV,333。最后一个例子还突出了操作算法在土耳其伊斯坦布尔上空的几个委员会错误。再一次,卷积模型呈现出更低的佣金数额。在附录B中,我们为感兴趣的读者提供了更多关于Proba-V图像的例子。
5.2. 转导迁移学习结果:Proba-V对Landsat-8
在本节中,我们介绍并分析仅使用Proba-V数据训练的网络的结果。这些网络首先使用PV24测试集在Proba-V源域中进行测试,然后使用L8Biome数据集在目标Landsat-8域中进行测试。目的是证明用10倍低分辨率的Proba-V数据训练的模型也可以传输到30 m Landsat-8分辨率,精度损失可以忽略不计。
我们按照第4.2节解释的设置,使用迁移学习方案2(图1)训练模型TLPV,333。特别是,我们使用PV48数据集进行训练,我们还训练了10个网络副本,以评估对初始化的鲁棒性。表6显示了使用PV24测试数据集在源Proba-V域中的该模型的结果。我们可以看到,该模型达到了非常高的精度,这对网络的初始化不是很敏感。

表6在使用PV24数据集的Proba-V PV48数据集上在Proba-V源域上训练模型的结果。

表7:L8Biome数据集上TLPV模型333的结果与其他已发表结果的比较。RS-Net(Jeppesen等人,2019)模型使用L8SPARCS数据集进行训练
为了在Landsat-8域中测试模型,我们遵循第5.2节中描述的过程。注意,正如我们之前讨论的,使用333 m分辨率的数据来分辨30 m分辨率的图像是一个欠确定的问题,因为在重采样过程中存在信息丢失。表7显示了使用L8Biome数据集作为测试集的Landsat-8域上所提出的模型的性能指标。我们可以看到,用Proba-V数据TLPV,333训练的模型的精度与FMask的精度相似(Zhu和Woodcock, 2012),并与近期研究的深度学习方法不远(Jeppesen et al., 2019)。这表明,使用较低分辨率的数据可以很好地解决给定分辨率的云检测问题,这表明由于升级而导致的大部分信息丢失不会影响最终的云掩码预测。附录B为一些额外精选的Landsat-8图像提供了该模型的云掩码。
5.3.FCNN鲁棒性

图7。使用来自L8Biome数据集TLL8333(蓝色)的Landsat-8数据和来自PV48数据集TLPV,333(橙色)的Proba-V数据训练的模型的测试精度。X轴:L8SPARCS数据集中的精度;Y轴:PV24数据集中的精度。(有关此图例中颜色的说明,请参阅本文的网络版本。)
如前所述,我们训练了同一个网络的十个副本,改变两个TL方向实验的随机种子,以测试转导迁移学习模型对初始化的鲁棒性。图7显示了这些模型(TLPV,333和TLL8,333)分别使用PV24和SPARCS数据集在Proba-V和Landsat-8域的测试精度。我们可以看到的最清晰的模式是,当网络在源域(即在它们被训练的同一域)测试时,其准确性比在目标域测试时更高,且变异性更低。正如我们之前解释的,我们将这种行为归因于目标域网络的隐式外推:不同的训练网络在目标域的某些未知部分给出了不同的预测。当调整网络的超参数时,这些结果应该被考虑在内,因为超参数配置之间的差异可能是由这种外推效应引起的噪声造成的。另外值得一提的是,在Proba-V域(TLPV,333)训练的网络与在空间-光谱域适应(TLL8,333)的Landsat-8数据上训练的网络具有相似的精度,尽管具有更高的可变性
5.4. 转导结果总结

表8 列出了拟议模型和文献中选定模型的不同测试集的结果。范围显示在10次运行中获得的最小值和最大值,更改网络权重初始化的随机种子值。
在这一小节中,我们探索所有以前的实验之间的联系,并比较他们的结果。由于提出的模型可以在两个领域(Landsat-8和Proba-V)进行评估,它们可以相互比较。表8显示了前几节的结果摘要。第一列,模型,指的是所采用的特定架构和TL方案。特定模型的TL方案指定了如何在源和目标域中测试该模型(参见第5节了解详细信息)。第二列显示用于训练模型的数据集;第三列显示了测试模型的数据集。其余的列是测试模型性能的不同度量。注意,如果使用不同的数据集训练给定的模型,它将以不同的参数结束(即网络的权值将是不同的)。
首先,在Proba-V域测试的情况下,我们可以看到仅用Landsat-8训练的模型仍然比基于阈值的Proba-V操作云检测模型好得多(Wolters et al., 2015);然而,它与用真实的Proba-V图像训练的网络还有很大差距。因此,它被证明是一种有效的策略,并具有改进的视角。其次,依赖于专家开发基本真理所采用的手工标注程序:我们看到,使用相同的方法进行训练和测试的数据进行训练的模型具有显著更高的准确性。例如,使用Li等人的训练-测试分割(2019)对L8Biome数据训练的网络比使用所有L8Biome数据训练并在L8SPARCS数据集测试的网络(91.25-91.81%)具有更高的准确性(92.90%)。在Proba-V域的情况下,我们看到用PV48数据集训练的网络在PV24数据集中也具有非常高的精度(94.81-95.10%),这可能也是由于PV48和PV24数据集是由相同的专家使用相同的手动标记方法开发的。在Recht等人(2018)、Torralba和Efros(2011)等涉及分类的其他环境中也记录了这种依赖性。在云检测的情况下,在数据集中包含薄云的不同标准可能会加剧这种情况,因为在一个数据集中,非常薄的半透明云可能被认为是清晰的像素,而在其他数据集中,这个像素可能被注释为云。最后,在这些结果中,重要的是要考虑在标签过程中的误差。据估计,Landsat的误差约为7% (Scaramuzza等人,2012),Proba-V的误差约为6.62%(见第4.2节)。因此,从统计的角度来看,使用这些数据集,超过93%的准确性的模型无法进行真正的比较或排名。
5.5.归纳迁移学习结果
在本节中,我们将同时展示和讨论使用两个数据集进行训练的模型的结果。这种设置旨在探索这样一种场景:给定(目标)卫星传感器很少有标记图像,这种情况经常发生,原因是手工标记云的成本很高,而来自不同但相似的传感器的标记图像的语料库更大。在这些实验中,Proba-V将作为目标域,其中很少有带云掩码的标记图像可用,而Landsat-8卫星将作为源域,L8Biome数据集作为标记图像的大型语料库。因此,实验的目标是测试使用微调或与L8Biome数据集联合训练的网络是否比使用少量Proba-V图像从头训练的网络具有显著更好的性能。
为了使用Landsat-8数据训练模型,我们应用TL方案1(第3.2节),并在第5.3节中解释了拟议的光谱空间域适应。在此设置中,模型在Proba-V域中进行训练,因此,联合训练包括将少数Proba-V图像的数据集与Landsat-8自适应图像的数据集合并。
我们用PV48数据集中越来越多的真实Proba-V图像训练了几个网络。对于每一组Proba-V图像d,我们从PV48数据集中选取8个不相交的子集,包含d张图像。对于每个子集,分别训练三个模型:(a)使用子集内的d Proba-V图像从零开始训练;(b)微调,使用这些d Proba-V图像微调之前在L8Biome数据集中训练的网络5;©联合训练,使用d Proba-V图像和L8Biome数据集中的所有图像从头开始训练。

图8所示。用不同数量的Proba-V图像训练FCNN联合模型的PV24测试集,红色为从无到有,黄色为微调,绿色为联合训练。(关于这个图例中有关颜色的解释,读者可参阅本文的网页版本。)
图8为本实验在PV24测试集上的测试结果。总的来说,我们发现联合训练比从零开始训练或使用微调训练有更好的表现,后者显示了类似的准确性。特别地,我们可以看到,在1到3张图像的稀缺数据场景中,使用联合训练可以提高2到4点之间的平均精度。在有4到6张图像进行训练的场景中,联合训练仍然在精度上有小的提高,并减少了结果精度值的方差。这表明联合训练方案具有更强的鲁棒性。在数据量较大的场景中,我们看到这三种方法具有相似的性能。还值得一提的是,与仅使用Landsat-8数据而不使用任何Proba-V图像训练的模型相比,联合训练系统地提高了平均精度(第6.1节)。

图9。测试使用不同数量的Proba-V图像训练的模型的准确性。对于左侧的每个值,仅使用Proba-V数据;在右侧,模型根据陆地卫星8号和Proba-V数据联合训练。蓝色阴影区域表示仅在L8Biome数据集中训练的模型的准确性。橙色区域表示在所有Proba-V图像(PV48)上训练的模型的准确性。(有关此图例中颜色的说明,请参阅本文的网络版本。)
图9比较了联合训练和从头开始的训练。在该图中,每个点表示d图像的子集,其中d在X轴中变化。左侧的点显示了仅使用这些d图像从头开始训练的模型的PV24测试集的准确性,而右侧的点将这些d图像与L8Biome数据集中的图像一起用于训练(联合学习)。我们看到,对于这些子集中的绝大多数,使用联合训练对模型的最终性能有积极影响(右侧的点)。我们再次看到,联合模型的方差减少,联合训练始终利用新的Proba-V数据,也比不使用它的模型表现更好,该模型仅使用L8Biome数据集进行训练,并由蓝色阴影区域描述。请注意,橙色区域描述了在所有Proba-V图像(PV48)上训练的模型的精度,这为云检测精度提供了上限
6.总结
在本文中,我们探索了不同的转移学习(TL)方法来训练用于遥感图像中云检测的机器学习(ML)方法。特别是,我们以Landsat-8和Proba-V为例分析了transductive和归纳TL框架。这两种框架都依赖于域自适应转换,该转换将来自一颗卫星的图像转换为与另一颗卫星获取的图像相似的图像。
我们提出了一种图像转换方法,以使Landsat-8图像适应Proba-V光谱和空间特征,从而实现跨卫星的TL。我们的结果表明,为了充分利用TL的优势,必须同时使用空间和光谱自适应。
transductive transfer learning框架假设我们只有来自一个卫星的数据。在此背景下,提出了两种不同的TL方案,并成功地进行了测试。根据域自适应转换的特定方向,每个方案都允许不同的TL:从源域到目标域或从目标域到源域。我们表明,仅使用Landsat-8数据训练的ML模型在Proba-V上的性能优于当前的运算算法(Wolters等人,2015)。这意味着ML方法甚至可以在卫星发射之前进行训练,并获得比基于阈值的方法更好的性能。我们在基于深度学习的最先进云检测方法的背景下评估了拟议方法的结果(Jeppesen等人,2019;Li等人,2019)。
为了使用Proba-V数据在Landsat-8图像上进行预测,我们提出了一种TL方案,该方案利用了拟议的Landsat8到Proba-V域自适应变换。我们表明,仅使用Proba-V数据训练的ML模型的精度与操作Landsat-8方法(如FMask)相似(朱和Woodcock,2012),并且仅比(李等人,2019)低两个点,即使我们的方法是使用低11倍空间分辨率的数据训练的。















 3455
3455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









