






一、梯度下降的优化算法
1、动量优化法(加速下降)
1.Momentum-使用动量的随机梯度下降法
(1)训练速度快(积攒历史梯度,有惯性的下降)
(2)波动更小(取前几次波动的平均值当做本此的权重参数)
2.NAG-算法(Momentum的变种)
(1)训练速度快(校正积攒历史梯度,提前预知下一次梯度)
(2)能够预知梯度底部的位置(不仅增加了动量项,并且在计算参数的梯度时,在损失函数中减去了动量项。在底部速度会降下来,不会冲上另一个山坡)
2、自适应学习率优化算法
1.AdaGrad算法
(1)每个变量用不同的学习率,学习率越来越慢(对于已经下降的变量,则减缓学习率,对于还没下降的变量,则保持较大的学习率).
(2)模型收敛稳定(由于学习率越来越小,接近目标的时候震荡小)。
2.RMSProp算法
蓝色为Momentum,绿色为RMSProp
(1)自适应调整学习率(避免了学习率越来越低的问题)
(2)模型收缴稳定(消除了摆动大的方向,各个维度的摆动都较小)

3.AdaDelta算法-结合了AdaGrad和RMSProp
(1)训练速度快(模型训练初中期加速效果好,速度快)
(2)模型收敛不稳定(模型训练的后期,会反复在局部最小值附近抖动)
4.Adam算法-结合了AdaGrad和RMSProp
(1)对内存需求较小(适用于大数据集和高维空间)
(2)不同参数有独立自适应学习率(通过计算梯度的一阶矩估计和二阶矩估计)
(3)解决稀疏梯度和噪声问题(结合了AdaGrad和RMSProp算法最优的性能)
二、优化器的可视化比较
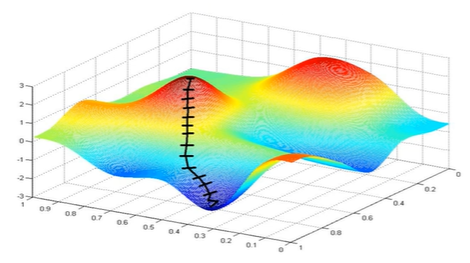
(1) 示例一
上图描述了在一个曲面上,6种优化器的表现,从中可以大致看出:
① 下降速度:
- 三个自适应学习优化器Adagrad、RMSProp与AdaDelta的下降速度明显比SGD要快,其中,Adagrad和RMSProp齐头并进,要比AdaDelta要快。
- 两个动量优化器Momentum和NAG由于刚开始走了岔路,初期下降的慢;随着慢慢调整,下降速度越来越快,其中NAG到后期甚至超过了领先的Adagrad和RMSProp。
② 下降轨迹:
- SGD和三个自适应优化器轨迹大致相同。两个动量优化器初期走了“岔路”,后期也调整了过来。
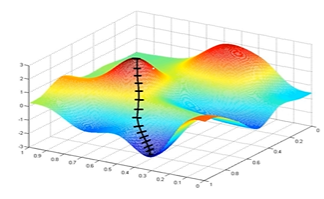
(2) 示例二
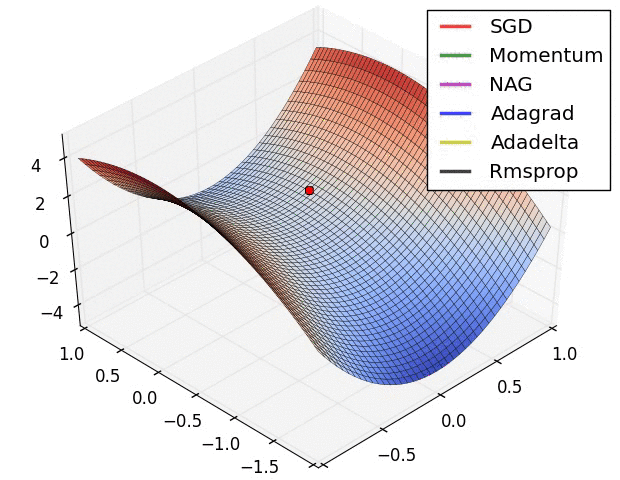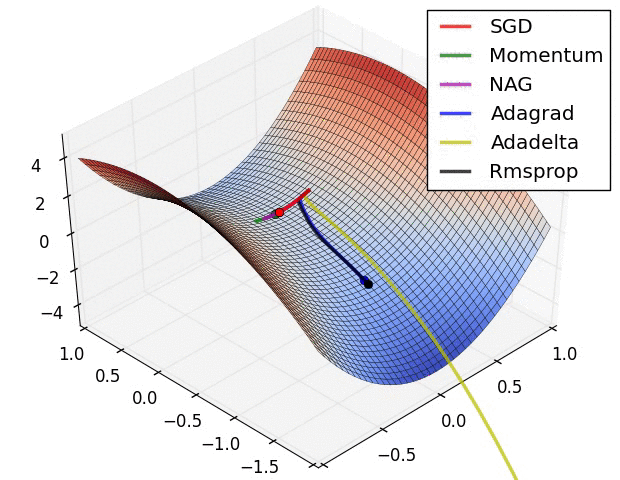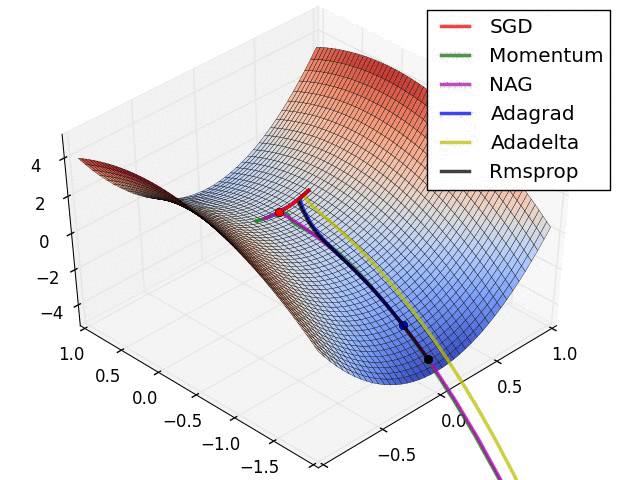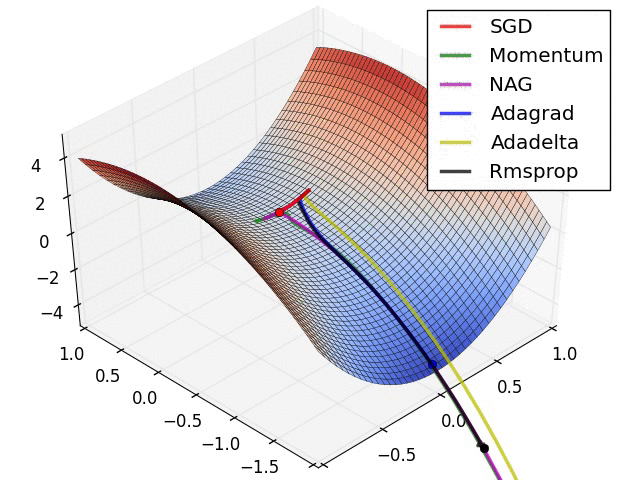
上图在一个存在鞍点的曲面,比较6中优化器的性能表现,从图中大致可以看出:
- 三个自适应学习率优化器没有进入鞍点,其中,AdaDelta下降速度最快,Adagrad和RMSprop则齐头并进。
- 两个动量优化器Momentum和NAG以及SGD都顺势进入了鞍点。但两个动量优化器在鞍点抖动了一会,就逃离了鞍点并迅速地下降,后来居上超过了Adagrad和RMSProp。
- 很遗憾,SGD进入了鞍点,却始终停留在了鞍点,没有再继续下降。
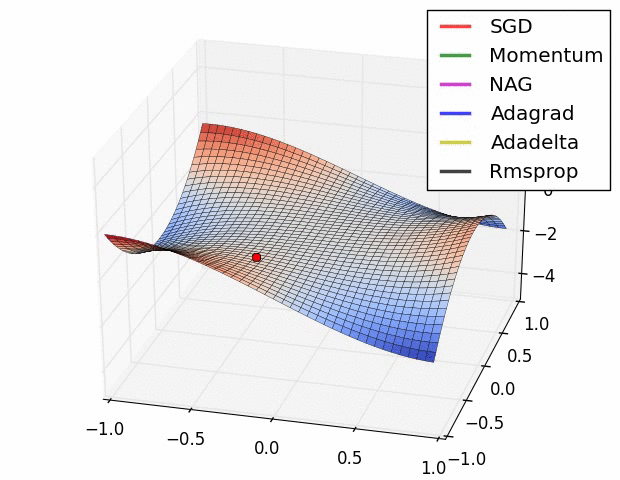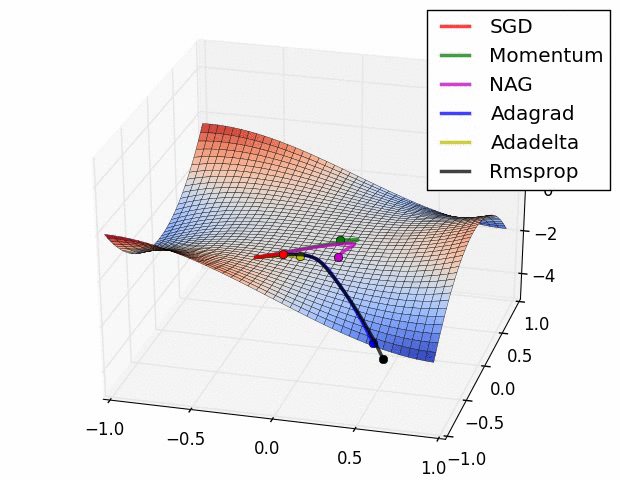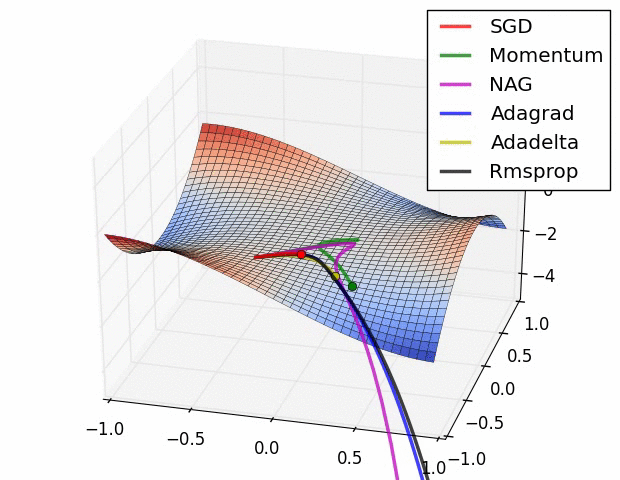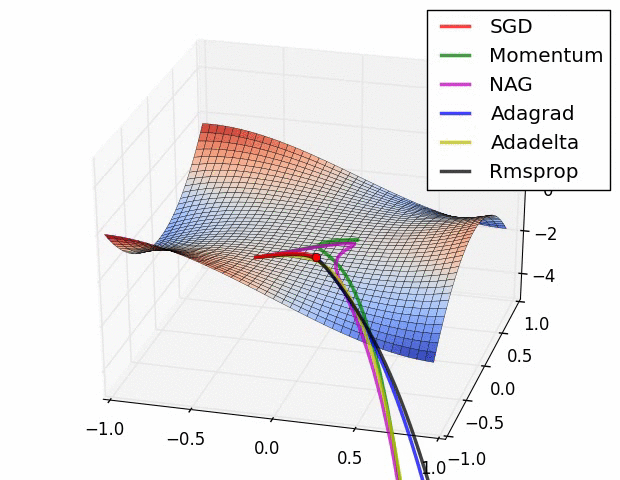
(3) 示例三
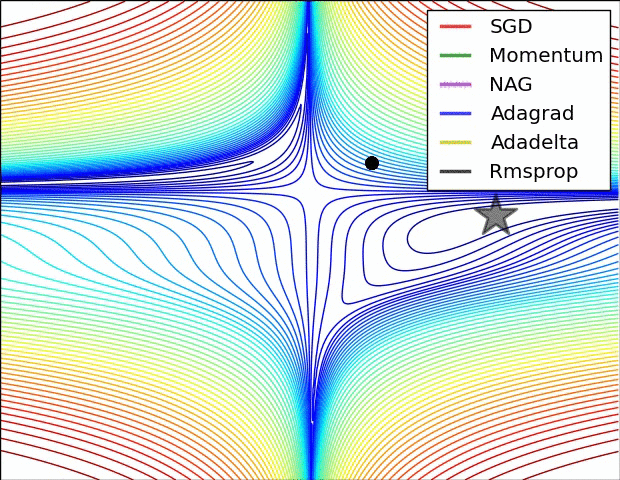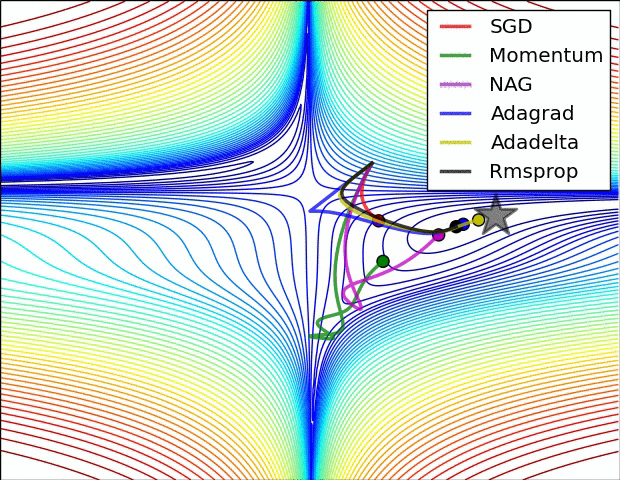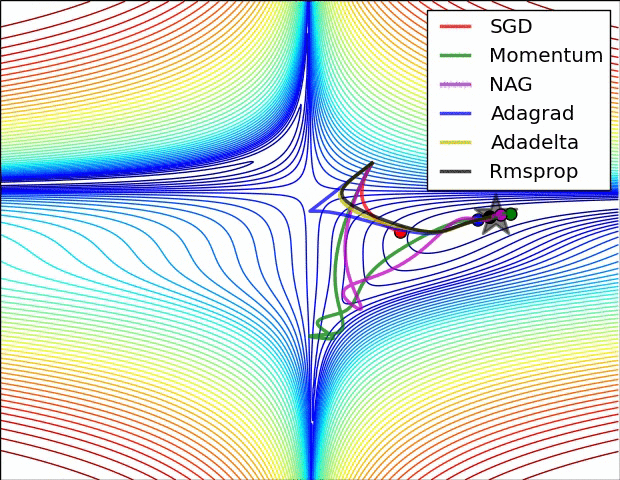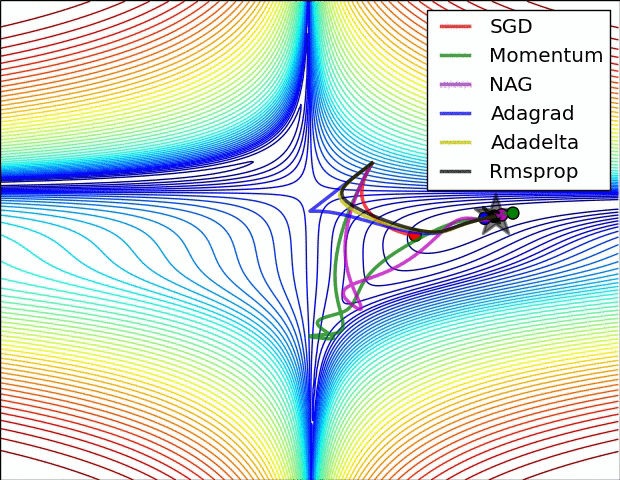
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
- 两个动量优化器Momentum和NAG的速度最快,其次是三个自适应学习率优化器AdaGrad、AdaDelta以及RMSProp,最慢的则是SGD。
② 在收敛轨迹方面
- 两个动量优化器虽然运行速度很快,但是初中期走了很长的”岔路”。
- 三个自适应优化器中,Adagrad初期走了岔路,但后来迅速地调整了过来,但相比其他两个走的路最长;AdaDelta和RMSprop的运行轨迹差不多,但在快接近目标的时候,RMSProp会发生很明显的抖动。
- SGD相比于其他优化器,走的路径是最短的,路子也比较正。
部分内容节选自:
https://zhuanlan.zhihu.com/p/77396618
https://blog.csdn.net/weixin_40170902/article/details/80092628















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









