







1.自动分段与清洗
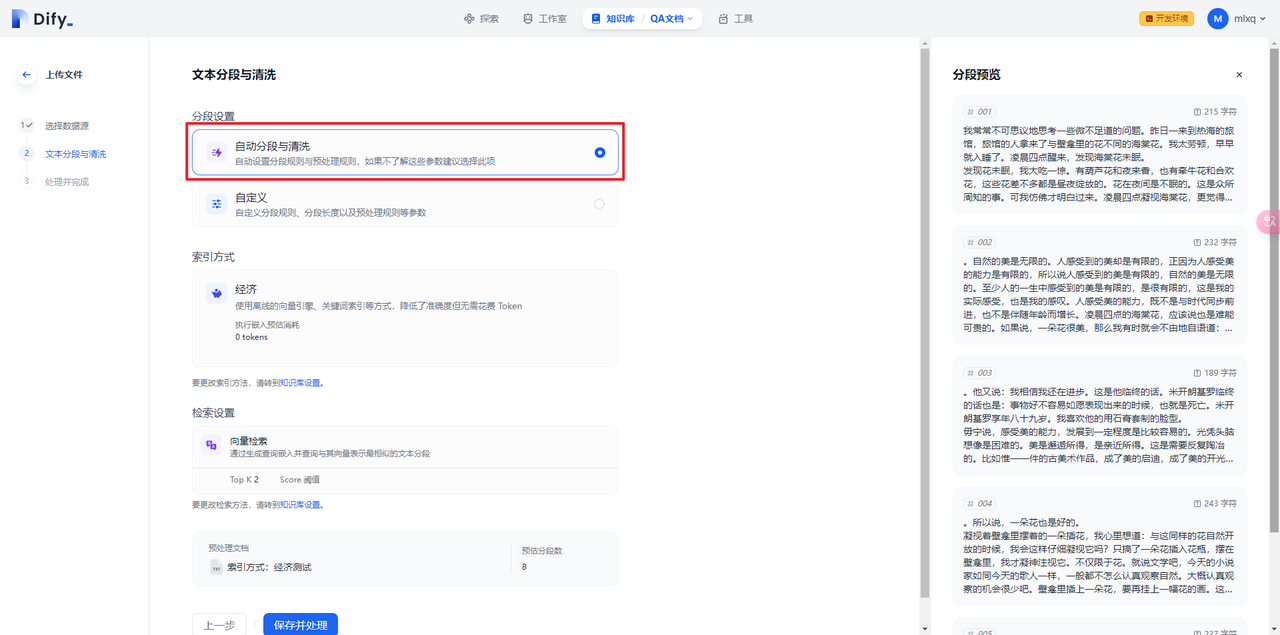
自动设置分段规则与预处理规则,如果不了解这些参数建议选择此项。
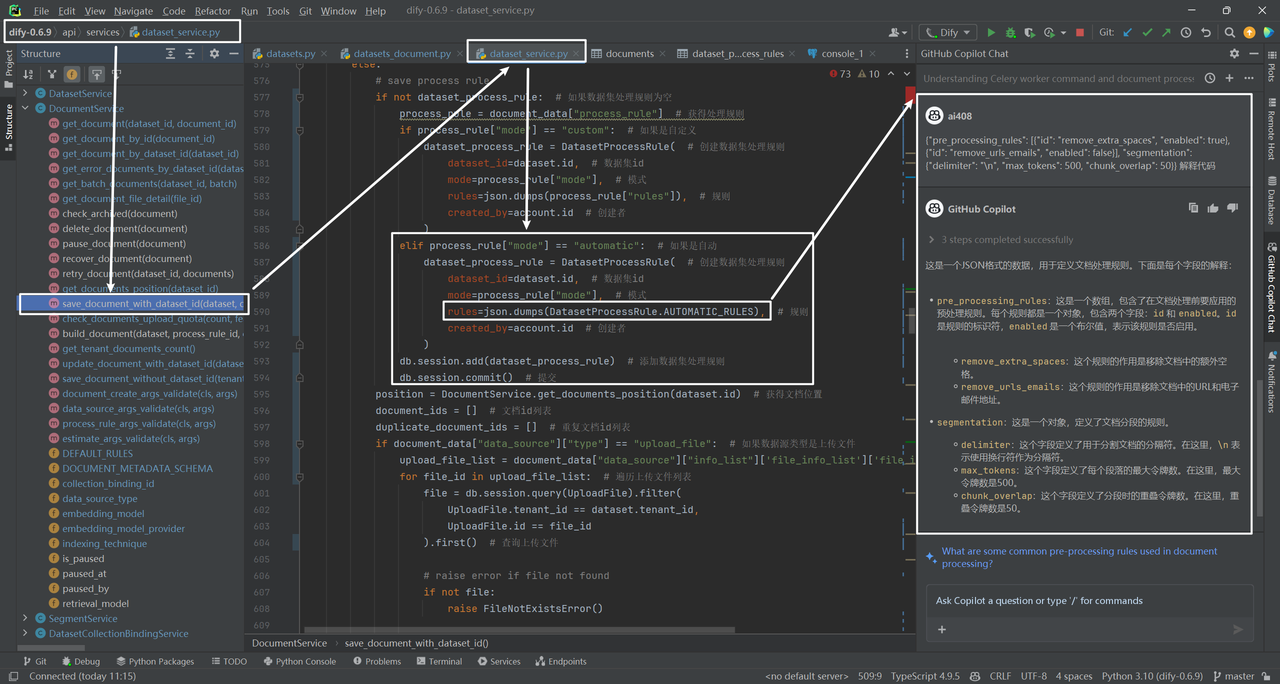
rules字段的 JSON 格式化的配置,以及每个组件的解释:
{
"pre_processing_rules": [
{
"id": "remove_extra_spaces",
"enabled": true
},
{
"id": "remove_urls_emails",
"enabled": false
}
],
"segmentation": {
"delimiter": "\n",
"max_tokens": 500,
"chunk_overlap": 50
}
}
(1)pre_processing_rules(预处理规则):这是一个规则数组,在处理文本之前应用。
(2)segmentation(分段):定义如何将文本分段成小块。
此配置对于需要预处理和分段文本的任务非常有用。预处理规则帮助清理文本,分段规则确定如何将文本分割以进行进一步分析或处理。
2.自定义分段设置
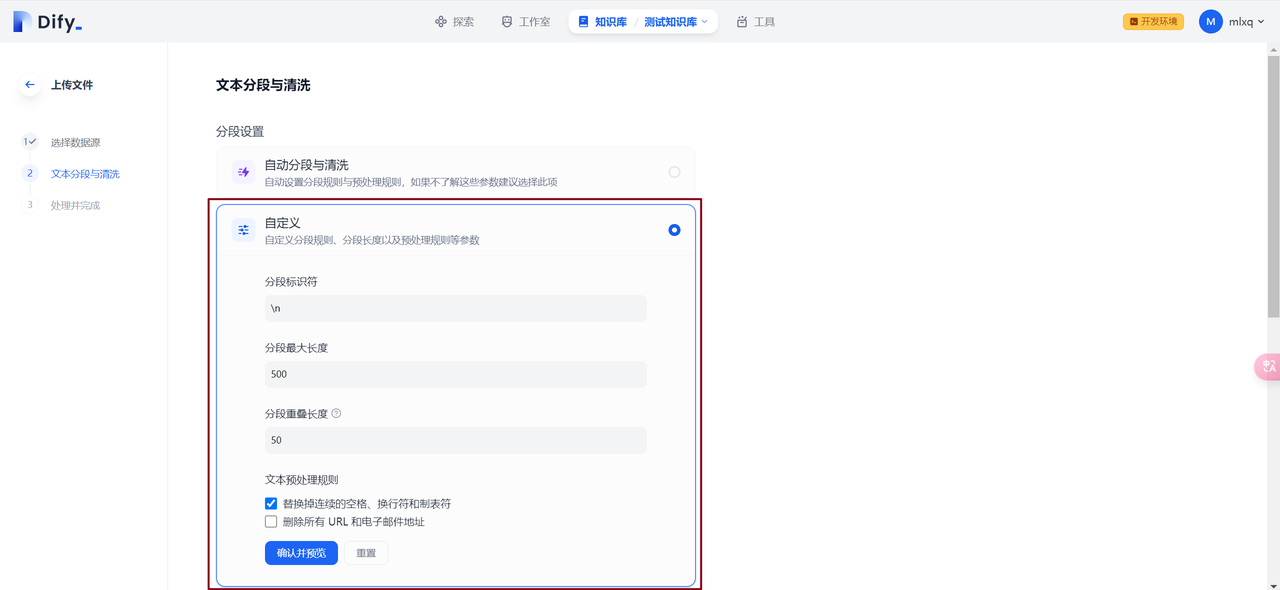
可根据实际需要自定义分段规则、分段长度以及预处理规则等参数。默认规则参数如下:
DEFAULT_RULES = { # 默认规则
'mode': 'custom',
'rules': {
'pre_processing_rules': [
{'id': 'remove_extra_spaces', 'enabled': True},
{'id': 'remove_urls_emails', 'enabled': False}
],
'segmentation': {
'delimiter': '\n',
'max_tokens': 500,
'chunk_overlap': 50
}
}
}



















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











