







本文主要解释了Dify中语音和文字间转换可能会遇到的问题,并给出了一种暂时注释的解决方案。
一.文本转语音可能问题
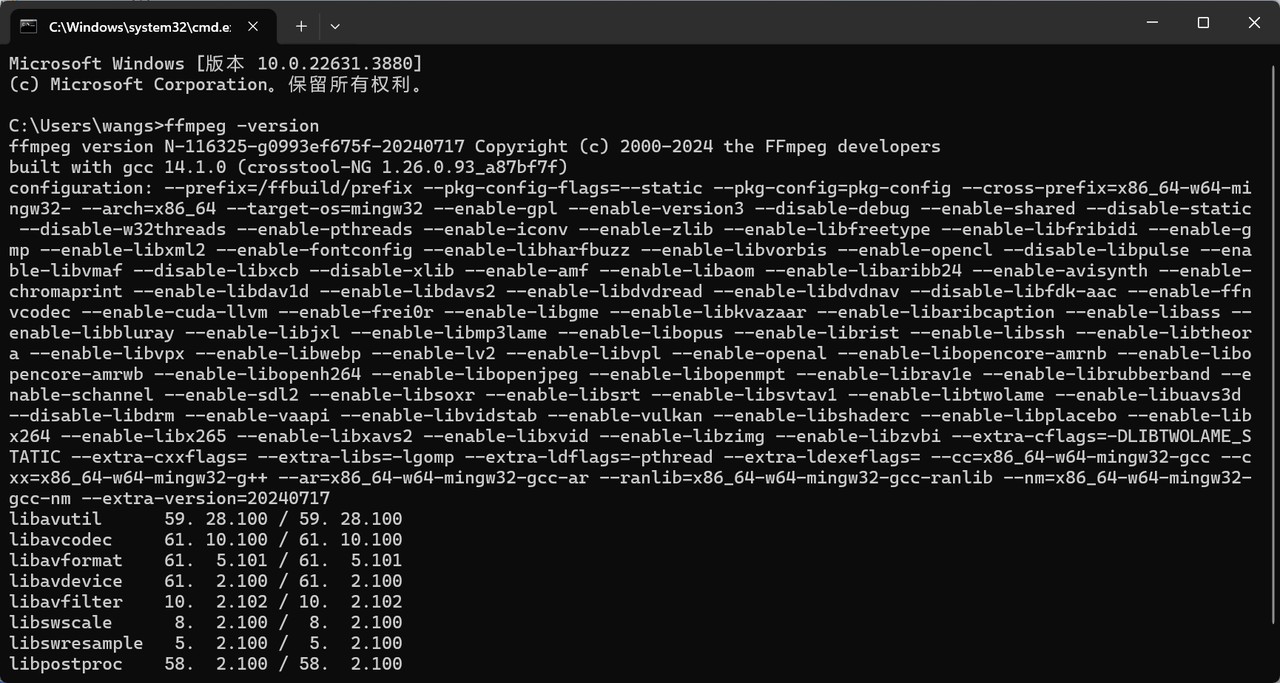
本地部署文本转语音时,如果遇到如下问题,安装ffmpeg即可。但是如果安装后,重启系统还是遇到这个问题该如何办?

ffmpeg -version信息:
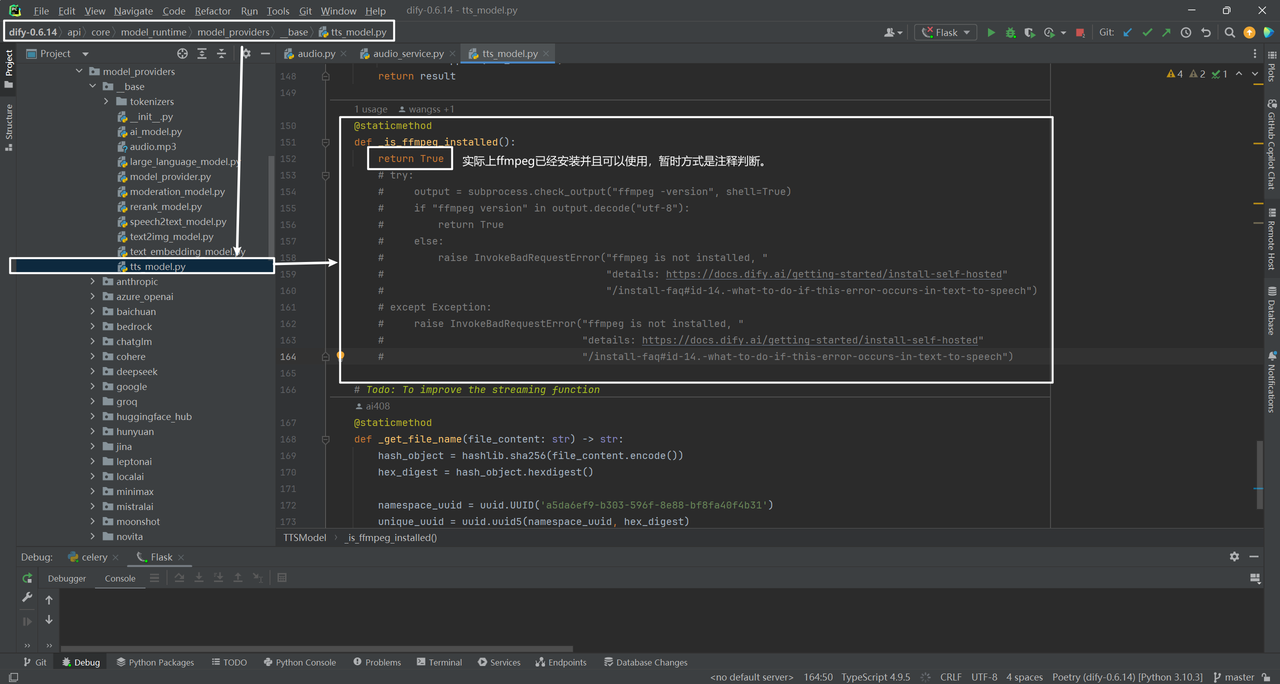
暂时解决方案是把判断ffmpeg是否安装注释掉,如下所示:
二.语音转文本可能问题
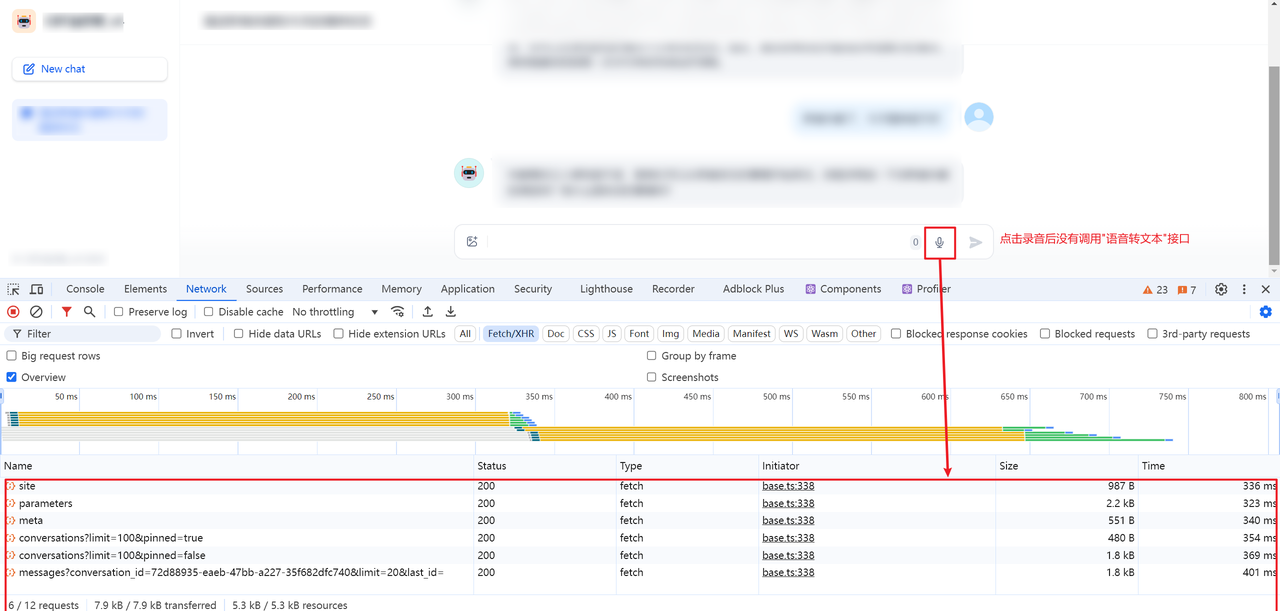
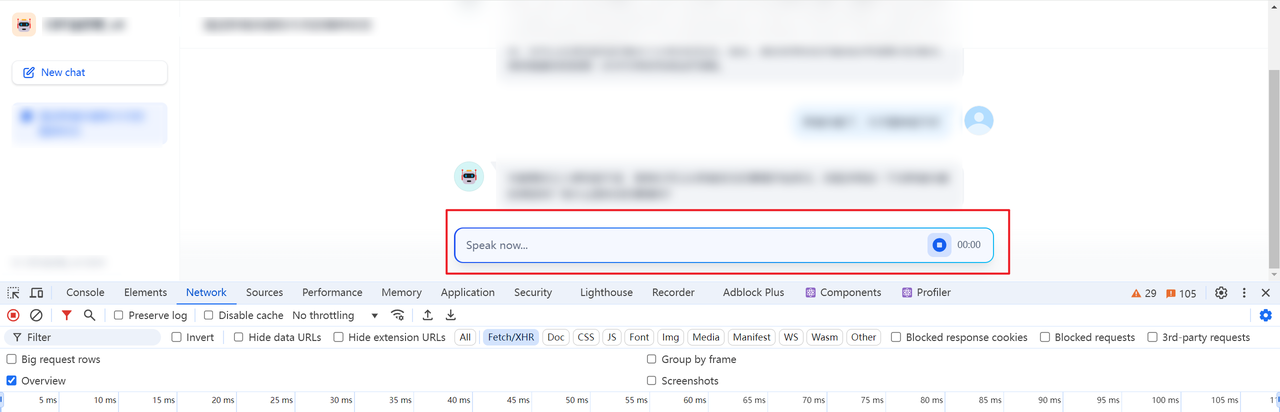
在测试语音转文本时,点击录制后发现并没有显示波形进行录音:
然后顺着前段代码找到dify\web\app\components\base\voice-input\index.tsx:
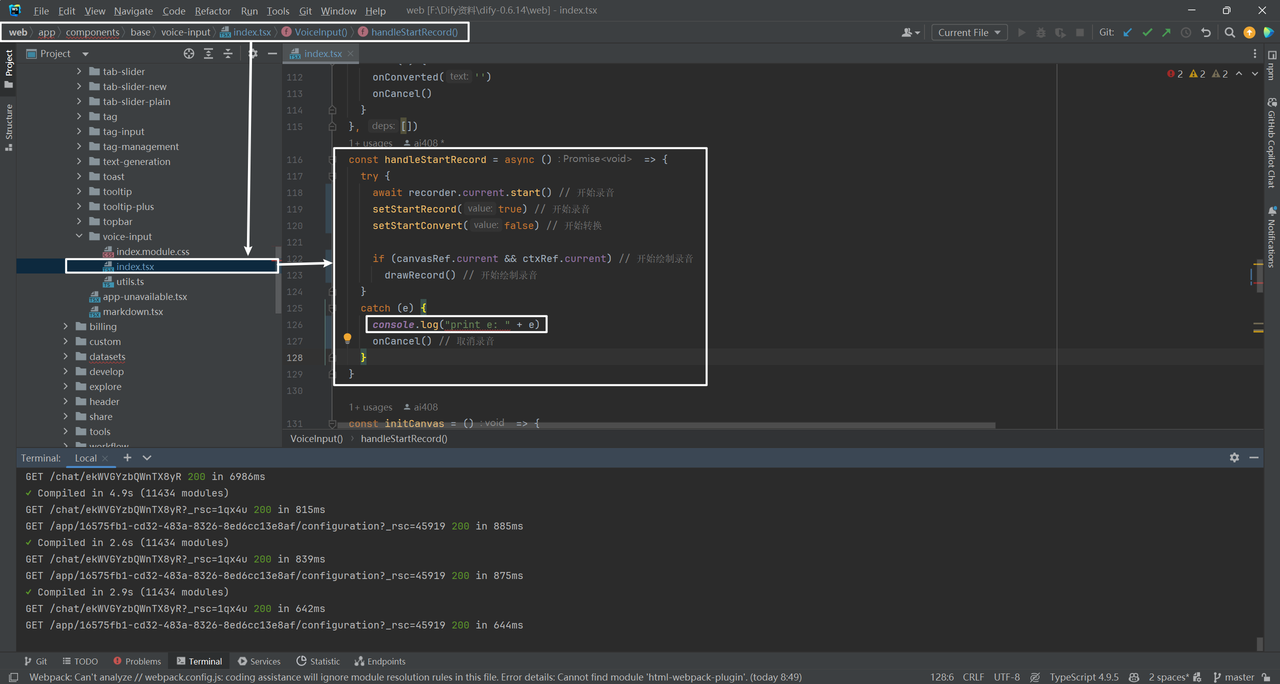
const handleStartRecord = async () => {
try {
await recorder.current.start() // 开始录音
setStartRecord(true) // 开始录音
setStartConvert(false) // 开始转换
if (canvasRef.current && ctxRef.current) // 开始绘制录音
drawRecord() // 开始绘制录音
}
catch (e) {
console.log("print e: " + e)
onCancel() // 取消录音
}
}
把e打印出来发现是undefined,但好像上面代码也没有问题,暂时解决方案是注释onCancel(),然后发现好了。
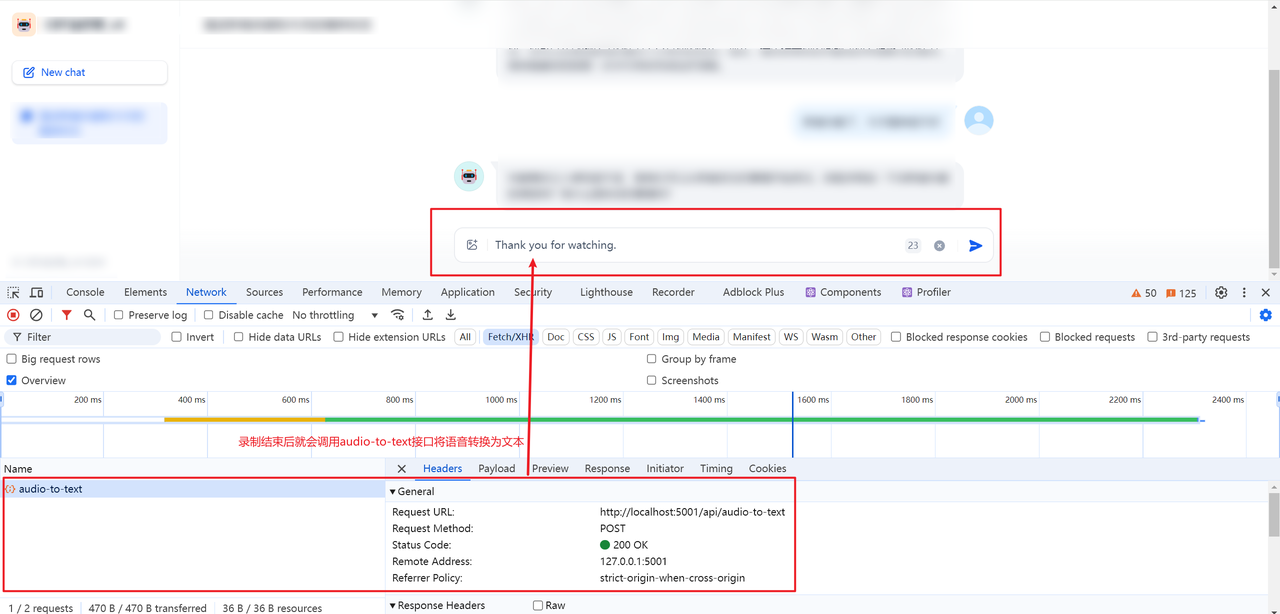
录音结束后,会调用audio-to-text接口将语音转换为文本:
参考文献
[1] 本地部署相关常见问题:https://docs.dify.ai/v/zh-hans/learn-more/faq/install-faq



















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











