







课程名称:CS20: Tensorflow for Deep Learning Research
视频地址:https://www.bilibili.com/video/av15898988/index_4.html#page=4
课程资源:http://web.stanford.edu/class/cs20si/index.html
参考资料:https://zhuanlan.zhihu.com/p/29598122
一、结构化模型
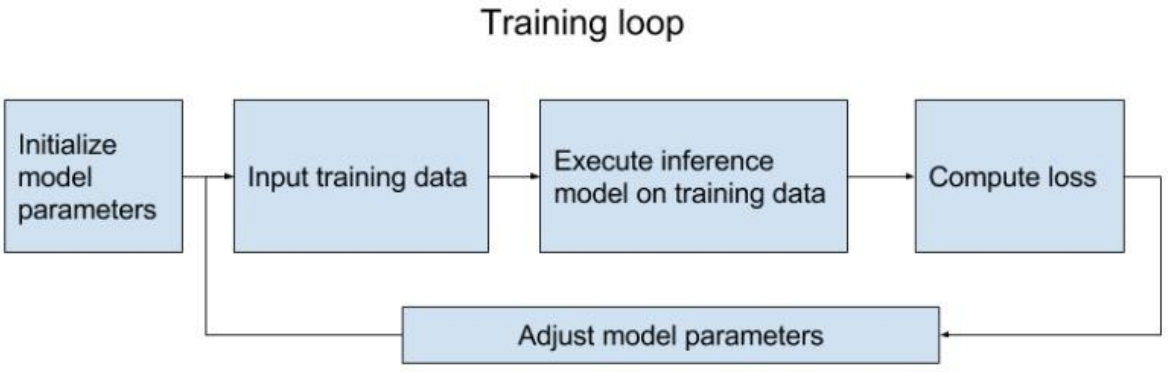
结构化我们的模型,可以方便我们Debug和良好的可视化。一般我们的模型都是由以下两步构成,第一步是构建计算图,第二步是执行计算图。
Assemble Graph
- Define placeholders for Input and output
- Define the weights
- Define the inference model
- Define loss function
- Define optimizer
Compute
二、Word Embedding
首先我们先理解一下词向量的概念。简单来说就是用一个向量去表示一个词语。下面我们介绍两个常用的word embedding 模型——CBOW 和 Skip-gram。
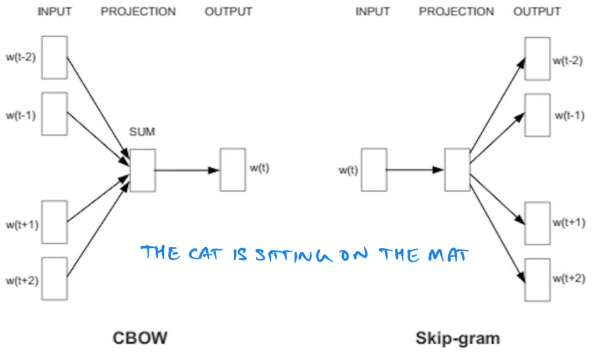
在CBOW模型中,我们给出的是预测目标词汇的上下文,例如上面的句子中,假设窗口大小为2,我们给出词汇是“the”“cat”和“sitting”“on”,目标词汇为“is”;而Skip-gram相反,它给出的是中间的词汇“is”,然后预测两边的词汇。
关于Skip-gram的具体介绍详见这篇文章
三、Skip-gram实现
数据集
这里使用的是text8数据集,这是一个大约100 MB的清理过的数据集,当然这个数据集非常小并不足以训练词向量,但是我们可以得到一些有趣的结果。
构建计算图
读取数据部分在 process_data.py 有定义的函数可以直接使用。代码如下:
def main():
batch_gen = process_data(VOCAB_SIZE, BATCH_SIZE, SKIP_WINDOW)
ceters, targets = next(batch_gen)
word2vec(batch_gen)
if __name__ == '__main__':
main()之后我们将的skip-gram的实现都写入 word2vec(batch_gen) 函数中。
首先定义好一些超参数
VOCAB_SIZE = 50000
BATCH_SIZE = 128
EMBED_SIZE = 128 # dimension of the word embedding vectors
SKIP_WINDOW = 1 # the context window
NUM_SAMPLED = 64 # Number of negative examples to sample.
LEARNING_RATE = 1.0
NUM_TRAIN_STEPS = 20000
SKIP_STEP = 2000 # how many steps to skip before reporting the loss① 建立输入和输出的占位符(placeholder)
center_word = tf.placeholder(tf.int32, [BATCH_SIZE], name='center_words')
y = tf.placeholder(tf.int32, [BATCH_SIZE, SKIP_WINDOW], name='target_words')这里SKIP_WINDOW表示预测周围词的数目,超参数里面取值为1。
② 定义词向量矩阵
embed_matrix = tf.get_variable(
"WordEmbedding", [VOCAB_SIZE, EMBED_SIZE],
tf.float32,
initializer=tf.random_uniform_initializer(-1.0, 1.0))这里相当于新建一个Variable,维数分别是总的词数x词向量的维度。
③ 构建网络模型
我们可以通过下面的操作取到词向量矩阵中所需要的每一个词的词向量。
embed = tf.nn.embedding_lookup(embed_matrix, center_word, name='embed')这里embed_matrix和center_word分别表示词向量矩阵和需要提取词向量的单词,我们都已经定义过了。
④ 定义loss函数
NCE已经被集成进了tensorflow,所以我们可以非常方便地进行使用,下面就是具体的api。
tf.nn.nce_loss(weights, biases, labels, inputs, num_sampled,
num_classes, num_true=1, sampled_values=None,
remove_accidental_hits=False, partition_strategy='mod',
name='nce_loss')labels和inputs分别是target和输入的词向量,前面有两个参数分别时weights和biases,因为词向量的维度一般不等于分类的维度,需要将词向量通过一个线性变换映射到分类下的维度。有了这个定义之后,我们就能够简单地进行实现了。
nce_weight = tf.get_variable('nce_weight', [VOCAB_SIZE, EMBED_SIZE],
initializer=tf.truncated_normal_initializer(
stddev=1.0 / (EMBED_SIZE**0.5)))
nce_bias = tf.get_variable('nce_bias', [VOCAB_SIZE],
initializer=tf.zeros_initializer())
nce_loss = tf.nn.nce_loss(nce_weight, nce_bias, y, embed,
NUM_SAMPLED,
VOCAB_SIZE)
loss = tf.reduce_mean(nce_loss, 0)⑤ 定义优化函数
接下来我们就可以定义优化函数了,非常简单,我们使用随机梯度下降法。
optimizer = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(loss)执行计算图
构建完成计算图之后,我们就开始执行计算图了,下面就不分开讲了,直接放上整段session里面的内容。
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
total_loss = 0.0 # we use this to calculate the average loss in the last SKIP_STEP steps0
writer = tf.summary.FileWriter('./graphs/no_frills/', sess.graph)
for index in range(NUM_TRAIN_STEPS):
centers, targets = next(batch_gen)
train_dict = {center_word: centers, y: targets}
_, loss_batch = sess.run([optimizer, loss], feed_dict=train_dict)
total_loss += loss_batch
if (index + 1) % SKIP_STEP == 0:
print('Average loss at step {}: {:5.1f}'.format(
index, total_loss / SKIP_STEP))
total_loss = 0.0
writer.close()通过阅读代码,也能看到非常清晰的结构,一步一步去运行结果。
结构化网络
结构化网络非常简单,只需要加入Name Scope。
with tf.name_scope(name_of_taht_scope):
# declare op_1
# declare op_2
# ...举一个例子,比如我们定义输入输出的占位符的时候,可以如下方式定义
with tf.name_scope('data'):
center_word = tf.placeholder(
tf.int32, [BATCH_SIZE], name='center_words')
y = tf.placeholder(
tf.int32, [BATCH_SIZE, SKIP_WINDOW], name='target_words')代码可参考这里(引自 Sherlock 知乎专栏 深度炼丹)















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









