









es关于在集群中特大搜索范围的问题
问题描述
在大规模的es集群中,如果一次搜索行为,触发的命中的所以太多,或者涉及的分片太多,则会可能存在串行的动作。这会让搜索变得慢N倍。
问题发现
在对es的agg聚合分析,执行profile分析计划,发现每个分片的执行时间都不长。但是总的执行时间很长。所以怀疑是es中某个环节是串行了。
es最佳工作机制
为了好描述问题,我以五个节点的集群为案例,假如我们的单个索引的分片数为25个,此时对这个索引的检索效果是最佳的。标准是每个节点5个分片。
为什么是每个节点单个索引最多五个分片?这是因为es官方为了保证节点的安全,而去设置的一个限制。一次检索,单个索引在一个节点上命中的分片数只能有5个。假如单个节点大于5个分片,则需要串行去处理数据了。比如一个节点上分片有11个要参与本次搜索,按照5个一拨。那么要串行三次,才能完成本次检索。
看官方文档:

Search API | Elasticsearch Guide [8.4] | Elastic
参数调优
我们可以通过参数:max_concurrent_shard_requests来改变es默认每次请求在单节点上只能有5个分片执行检索机制。在取消这个排队的过程。
测试结果
测试环境:1个node 1个index 30个分片
![]()
es默认参数下的检索情况
先清除一下es的缓存影响
执行:
POST _cache/clear
然后看检索效果:耗时11.7s
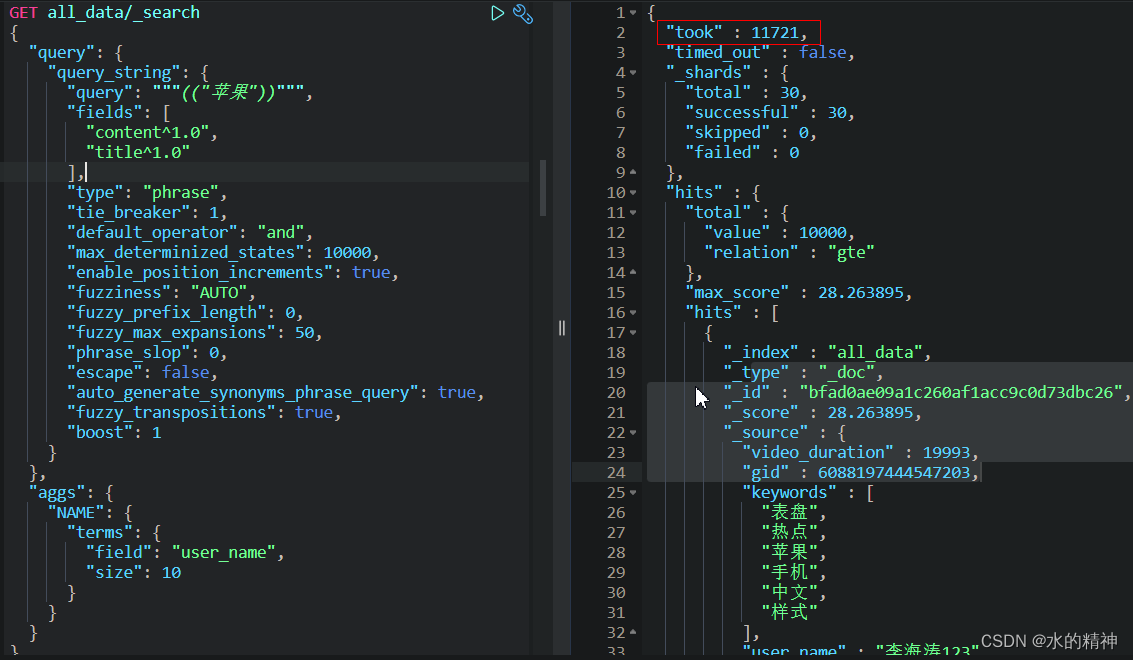
然后同样,再清除一下缓存,避免缓存的影响。
然后加上max_concurrent_shard_requests这个参数,因为我这里单台机器上是30个分片,所以这里我指定为30.
2.4s,提升了将近5倍!
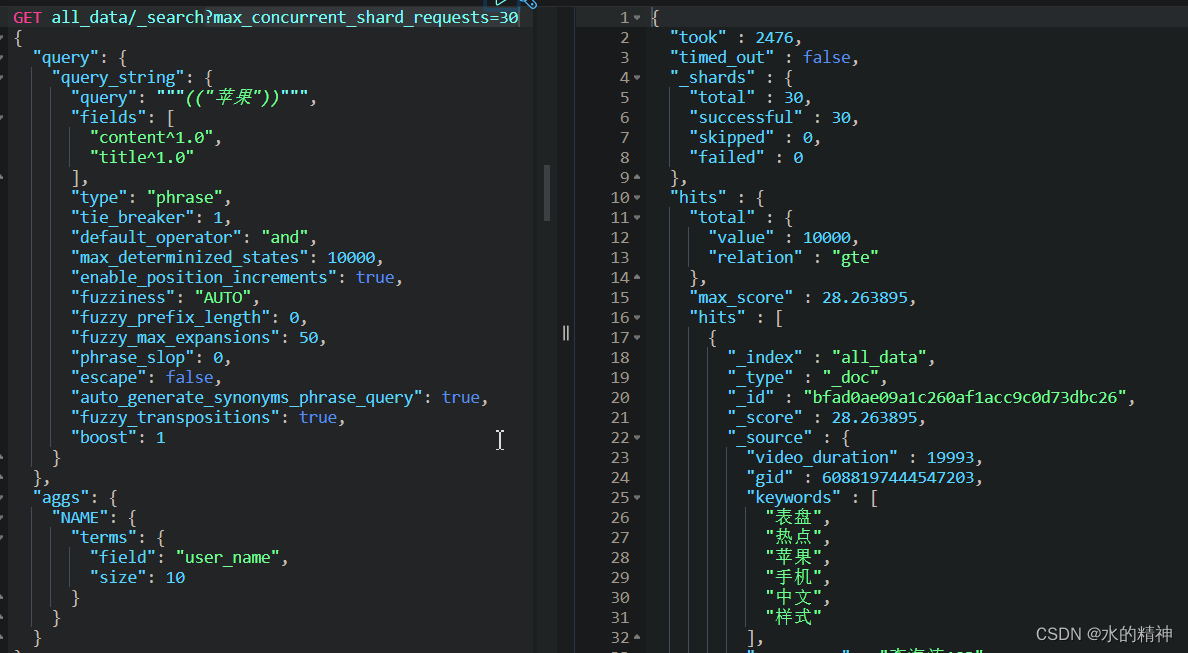
该参数正确使用
该参数可以设置在单次请求上
![]()
也可以对整个集群设置
PUT /_cluster/settings
{
"persistent" : {
"max_concurrent_shard_requests : "80"
}
}
该参数注意点
官方之所以这样设置来限制最大的并发两,是出于对es集群的保护,避免占用过多的资源,引发OOM等问题。在线上调试这个参数一定要注意,需要进行测试,以及压力测试,确保集群的稳定性。

















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









