









 北大论文探讨了在大语言模型中使用检索策略来扩展查询,以提高召回率。论文提出通过结合原始查询检索和模型生成,缓解大模型的幻觉问题。实验结果显示这种方法在特定模型和数据集上显著优于单纯的大模型预测,但存在对检索结果质量的依赖性。
北大论文探讨了在大语言模型中使用检索策略来扩展查询,以提高召回率。论文提出通过结合原始查询检索和模型生成,缓解大模型的幻觉问题。实验结果显示这种方法在特定模型和数据集上显著优于单纯的大模型预测,但存在对检索结果质量的依赖性。
北大论文,关于使用模型进行query扩展,提升召回率。并且合理解决模型的幻觉问题。
论文地址:SYNERGISTIC INTERPLAY BETWEEN SEARCH AND LARGE LANGUAGE MODELS FOR INFORMATION RETRIEVAL
一、论文的核心思想
如何有效的丰富扩展query,是一个提升召回率的关键问题。在大模型时代到来后,大家都开始使用LLM来扩展query。尽管LLM具有显著的文本生成能力,但它也容易产生幻觉,仍然难以代表其训练语料库中包含的完整的长尾知识。
在北大的论文中,介绍了通过检索和大模型的结果,提升召回率的方法。论文提出:为了缓解上述模型的幻觉问题,方案是由原始query检索到的文档D,将D提供给模型,作为辅助材料,再让模型生成新的query。先进行一次普通检索,召回数据有可能帮助llm做出更好的预测。相比较由原始query生成假设性回答,是一个不一样的思路。在论文中,看到此方法提示了15%的top10的召回率(但是我个人认为这样做也有问题,如果在第一次召回的文档和query的内容不相关怎么?)
二、如何使用LLM来扩展query
论文中的流程图如下图所示,其中红框的部分是我标记的,我个人认为这部分是不执行的。否则和论文中描述的思路就不一样了。应该是先拿原始query做召回(可以做BM25召回和稀疏向量的召回),然后只取top1的结果,送给模型,让模型基于召回的内容,以及原始query重新生成一个query,然后再用新生成的query再执行一次普通查询。最后将结果给召回。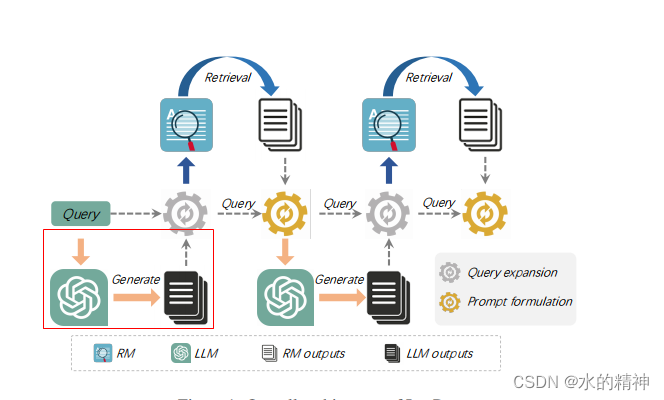
为此,我去看了源代码(源码地址:https://github.com/Cyril-JZ/InteR/blob/master/main.py)。的确和上述的图的流程是一样的。它第一次就拿着query,去生成一个假设性回答。

Prompt是这样构建的:
Please write a passage to answer the question\nQuestion: {}\nPassage:也就是走了红框的逻辑,之后拿着模型的输出结果,去执行Bm25的查询。
上述提到过,把搜索召回的结果,作为依据,来让模型重新生成假设性回答。在如下的prompt中,query就是原始的query,passage就是第一次query召回的内容。
Give a question {query} and its possible answering passages {passages}
Please write a correct answering passage:然后再拿着模型生成的query去做BM25检索。召回的结果作为最终的响应结果,结束整个流程
三、细节问题
在论文中,GTP模型下,第一次BM25召回top15。Vicuna-33B-v1.3模型下,召回top5。对于召回的数据,只取256个token。并且让模型输出的结果的最大token数为256。
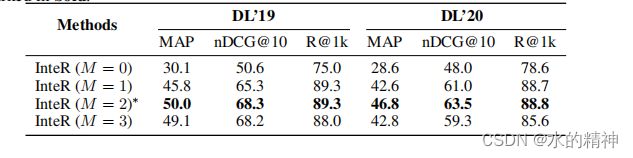
论文中,还讨论的循环迭代的次数。最终的结果和上图一样。循环两次效果是最好的。也就是过两次模型,做两次检索。
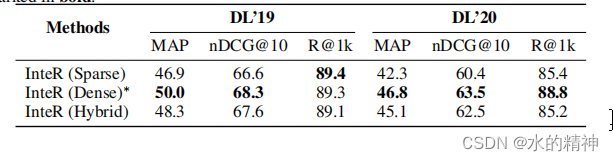
论文中还讨论了召回是使用Bm25稀疏召回还是稠密向量召回,稠密向量召回的方式,效果会更好一些。虽然稠密向量召回效果更好,但是还是要考虑到效率的问题。组中均采用BM25 的召回。
四、效果如何
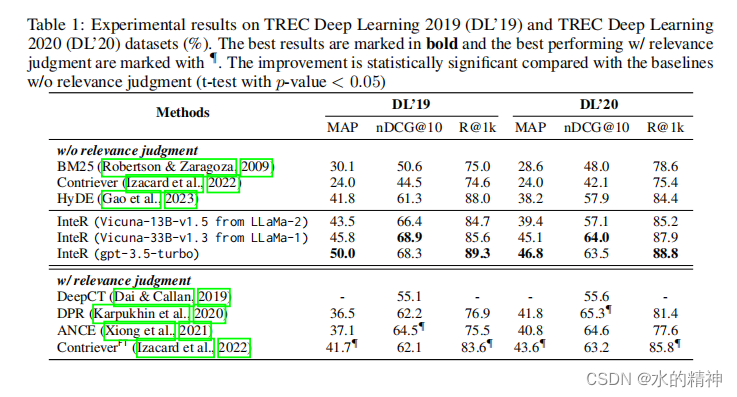
在论文中对比了开源的LLM Vicuna-33B-v1.3,已经chatGPT的 Vicuna-33B-v1.3。论文中的效果相比较BM25,还是有非常明显的提升效果。基本上大于15%,其中开源的模型和chatGPT相差不大。
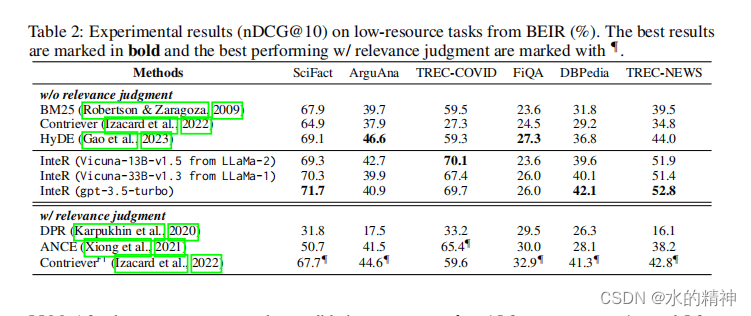
测试数据说明
采用了广泛使用的网络搜索查询集TREC深度学习2019(DL‘19)(克拉斯维尔等人,2020)和TREC深度学习2020(DL’20)(克拉斯维尔等人,2021),它们基于MS-MARCO(Bajaj等人,2016)。此外,我们还使用了来自BEIR基准(Thakur等人,2021)的6个不同的低资源检索数据集,符合(高等人,2023),包括SciFact(事实核查)、ArguAna(参数检索)、TREC-covid(生物医学IR)、FiQA(财务问题回答)、DBPedia(实体检索)和TREC-NEWS(新闻检索)。值得指出的是,我们没有使用任何训练查询-文档对,因为我们在零镜头设置中进行检索,并在这些测试集上直接评估我们提出的方法。与之前的工作一致,我们报告了TREC DL‘19和DL’20数据的MAP、nDCG@10和Recall@1000(R@1k),并且在BEIR基准测试中的所有数据集都使用了nDCG@10。
五、此方案的弊端
我在开篇就提到的问题,因为这很比较依赖第一检索的数据的质量。所以这里是一个待解决的问题。设想一下,如果第一次检索召回的数据质量很差,那么在第二次根据召回的数据和query重新生成query的时候,解决肯定是错误的。

















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









