









1. 为什么需要QR
查询改写,即 Query Rewrite,主要解决的问题是用户的搜索 Query 和 被搜索的文档 不显式匹配。
Query和Doc/Item有Semantic Gap,Query是用户端语言,Doc/Item是商户/平台端语言,风格和词汇都不一样。e.g. Query端是“通马桶”、“剪头”,Doc端是“管道疏通”、“理发”。
Semantic Match是一种解决方案,通过把Query和Doc都表示成同一语义空间(Semantic Space)下的 dense vector,然后计算相似度。比如双塔模型(DSSM系列)。缺点是需要大量标注数据,通常用ClickThrough数据。但是Click是Biased和Noisy的,用户的点击不光受Query-Doc的Relenvance的影响,也受其他的(图片,位置,价格,偏好)。我们要学习一个度量Relenvance的模型,但是ClickThrough数独不完全是。
所以还是需要Query Rewrite,可解释性也好。
2. 好的改写
一个好的改写Query,召回的Doc跟原Query是要相关的。反过来,一个改写Query召回的Doc跟原Query的相关性,也决定该改写Query是不是原Query的一个好的改写。
3. QR
Query Rewrite分成两个子问题,Candidate Generation和Candidate Ranking。
Candidate Generation又多种方法:基于Content,同义/近义替换,语义vector找近义词;基于Context,搜索Session,Query-Click Graph。
Candidate Ranking,学习一个函数 F(query, rewrite; theta),PointWise,PairWise都可以。Rank也需要大量的Label数据,用ClickThrough数据效果不会太好。对于(Q,R),按这个分数排序,
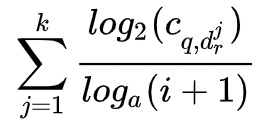 TOP N定义为正样本,其他为负样本
TOP N定义为正样本,其他为负样本
4. QR的主要内容
- 相似Query:“冰与火之歌”和“权利的游戏”
- 动态丢词:绝大多数情况下“的”字是无效词,但“北京的大学”中“的”是不能丢弃的,因为“北京的大学”和“北京大学”有明显不同的含义
- 意图预测:当你搜“苍老师”的时候,你究竟是想搜“苍老师的微博”还是“苍老师的电影”呢?
- 跨媒体查询:搜索“鲜花 jpg”想要直接获取到的图片素材,而不是介绍鲜花的百科
- 相关搜索:“知乎”和“黄继新”和“中文UGC社区”
- 自动纠错:“炒鸡好吃” ->“超级好吃”
主要训练语料为用户的搜索点击日志
参考:
1. https://zhuanlan.zhihu.com/p/77018857
2. https://www.zhihu.com/question/22855572/answer/288432579
3.《Efficient Query Rewrite for Structured Web Queries. Microsoft Research, Silicon Valley》















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









