








 本文探讨了在处理长文本和复杂问题时,Raptor如何通过高斯混合模型和UMAP降维构建递归树结构,以提高检索系统的性能。论文通过实例和实验展示了在NarrativeQA、QASPER和QuALITY数据集上,Raptor在长文本理解和跨文档问题解答中的优势。
本文探讨了在处理长文本和复杂问题时,Raptor如何通过高斯混合模型和UMAP降维构建递归树结构,以提高检索系统的性能。论文通过实例和实验展示了在NarrativeQA、QASPER和QuALITY数据集上,Raptor在长文本理解和跨文档问题解答中的优势。
当信息蕴含在较长的上下文时,基于片段的搜索召回,一定会丢失数据,导致最终无法正确的回答问题。
实际上复杂的问题,这里只是说问题本身倾向于从全文获取答案,而不仅仅是基于片段。
斯坦福论文提出的核心问题和解决思路:传统RAG在非连续文档、跨文档主题和分散型主题内容时效果不佳。而RAPTOR则可以利用高斯混合模型和UMAP降维等技术,使用递归形式将散落的片段先按层级组织起来。
论文如下
一、RAG中的挑战
如果RAG中的搜索有困难级别,根据段落就有标准答案的问题是容易级别,需要思考和考虑上下文的是困难级别。
经常说,开始做rag很容易,但是想要做出效果是真难。最大感触是,你知道流程和步骤,但是仍然做不好。里边有非常多的复杂的问题。想要做到50的准确度效果很容易,想要做到90的准确度效果就比较难了。
对于容易级别的检索,要解决的是搜索问题。如何拿query找到正确的答案,是首先应该解决的问题。
对于困难级别的检索,就不是简单的搜索问题了。例如要思考的问题,小明和小红谁更有钱?比如总结性的问题,灰姑娘是如何达到幸福的生活的?显然这些复杂的问题,很难从任何一个段落中就获取到答案,换句话说,答案不在任何单个段落中,而是在整篇文章中,或者整本书中。此类问题对于RAG来说,是极其困难的。
对于困难的检索,困难点在于,如何保留文档中的上下文信息。只是简单的获取段落,企图从段落中获取总结性问题的答案,从一开始就是错误的,这不就是断章取义嘛。
本文来精读斯坦福大学的论文,论文提到了以树形结构,来组织数据的方式,来解决上述提到的上下文关联问题(或者说多跳问题)。流程图如下
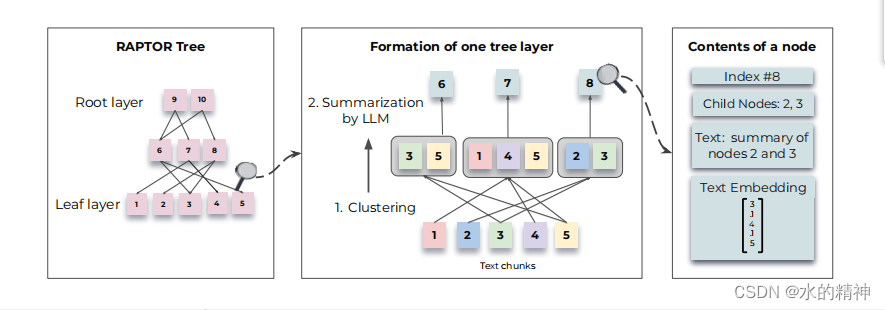
通过构建一个递归树结构来解决阅读中语义深度和连接的问题,该结构平衡了更广泛的主题理解和颗粒细节,并允许基于语义相似性对节点进行分组,而不仅仅是文本中的顺序。
二、如何把内容构建成结构树
问题最关键的是如何构建一颗分层的树。
2.1 数据切分
首先将检索语料库分割成长度为100的短的连续文本,类似于传统的检索增强技术。如果一个句子超过了100个标记的限制,我们将整个句子移到下一个块,而不是在句子中间删除它。这保留了每个块中文本的上下文和语义一致性(即保留完整的句子,不要分隔句子)。
将切分好的数据,使用文本嵌入模型,做embedding。此时得到了最下层的叶节点。
2.2 聚类分组
分类算法是最至关重要的。目标是,将内容相关的知识分成一个类,这里我更喜欢叫做topic。做好分类以后,便于总结归纳,并继续向上层传递知识。 把叶子节点进行分类,并抽取摘要,然后作为新的新生成层,在新生成层上,继续做分类和提取摘要,再生成新的层。这样就会有一个金字塔的结构。如下图所示
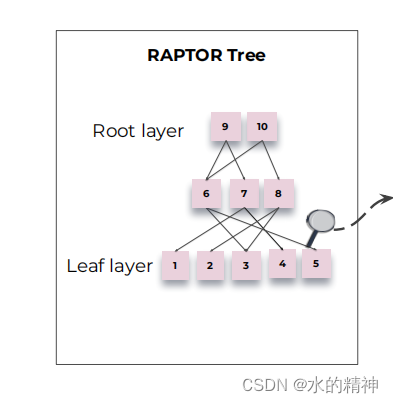
论文中提供的聚类算法有以下两个特点,称之为软聚类
- 不限制每个topic中节点的数量
- 不限制节点所在的topic,也即节点可能出现在多个topic。如下图所示。
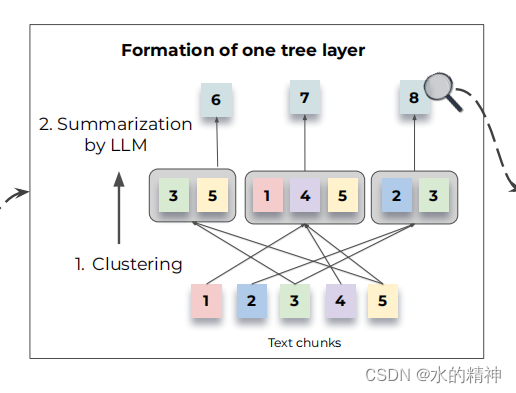
2.3 软聚类算法
个人认为最精髓的就是聚类算法,但是很遗憾,论文中的介绍并不是很详细。
论文中只提到,聚类算法是基于高斯混合模型(GMMs),这是一种同时提供了灵活性和概率框架的方法。并使用一种降维技巧(UMAP) 来优化向量。
以下是论文原文关于高斯混合模型,和降维方法,最终完成分类。
Given a set of N text segments, each represented as a d -dimensional dense vector embedding, the likelihood of a text vector, x , given its membership in the k th Gaussian distribution, is denoted by P ( x | k ) = N ( x ; µ k , Σ k ) . The overall probability distribution is a weighted combination P ( x ) = P K k =1 π k N ( x ; µ k , Σ k ) , where π k signifies the mixture weight for the k th Gaussian distribution. The high dimensionality of vector embeddings presents a challenge for traditional GMMs, as distance metrics may behave poorly when used to measure similarity in high-dimensional spaces ( Aggarwal et al. , 2001 ). To mitigate this, we employ Uniform Manifold Approximation and Projection (UMAP), a manifold learning technique for dimensionality reduction ( McInnes et al. , 2018 ). The number of nearest neighbors parameter, n neighbors , in UMAP determines the balance between the preservation of local and global structures. Our algorithm varies n neighbors to create a hierarchical clustering structure: it first identifies global clusters and then performs local clustering within these global clusters. This two-step clustering process captures a broad spectrum of relationships among the text data, from broad themes to specific details.Should a local cluster’s combined context ever exceed the summarization model’s token threshold, our algorithm recursively applies clustering within the cluster, ensuring that the context remains within the token threshold. To determine the optimal number of clusters, we employ the Bayesian Information Criterion (BIC) for model selection. BIC not only penalizes model complexity but also rewards goodness of fit ( Schwarz , 1978 ). The BIC for a given GMM is BIC = ln( N ) k − 2 ln(ˆ L), where N is the number of text segments (or data points), k is the number of model parameters, and ˆ L is the maximized value of the likelihood function of the model. In the context of GMM, the number of parameters k is a function of the dimensionality of the input vectors and the number of clusters. With the optimal number of clusters determined by BIC, the Expectation-Maximization algorithm is then used to estimate the GMM parameters, namely the means, covariances, and mixture weights.While the Gaussian assumption in GMMs may not perfectly align with the nature of text data, which often exhibits a sparse and skewed distribution, our empirical observations suggest that it offers an effective model for our purpose. We run an ablation comparing GMM Clustering with summarizing contiguous chunks and provide details in Appendix B .
2.4 提取摘要
为了避免歧义下边给出了论文的原文。关于摘要,这里我的理解是,把分类后的topic所包含的叶子节点。一起送给LLM去生成一个摘要。
Model-Based SummarizationAfter clustering the nodes using Gaussian Mixture Models, the nodes in each cluster are sent to a language model for summarization. This step allows the model to transform large chunks of text into concise, coherent summaries of the selected nodes. For our experiments, we use gpt-3.5-turbo to generate the summaries. The summarization step condenses the potentially large volume of retrieved information into a manageable size. We provide statistics on the compression due to the summarization in Appendix C and the prompt used for summarization in Appendix D .
摘要提取的prompt

You are a Summarizing Text Portal,Write a summary of the following, including as many key details as possible: {context}:2.5 关于模型生成摘要的幻觉问题
三、如何查找树
按照分层,逐层找到最相关的。
两种查询机制:分层和不分层。这些方法提供了独特的方法来遍历多层结构树来检索相关的信息,每一种都有自己的优点和权衡。
3.1 分层按照树遍历
树遍历方法首先根据其与查询嵌入的余弦相似度,选择前k个最相关的根节点。在下一层考虑这些节点被选择的子节点,并根据它们与查询向量的余弦相似度再次从这个池中选择前k个节点。重复这个过程,直到我们到达叶节点。最后,将来自所有选定节点的文本连接起来,以形成检索到的上下文。该算法的步骤概述如下:
把原始query转成向量。然后使用向量检索,注意对知识树是分层检索。一层一层的向下传递。把每层最先关的数据,最后汇总到一起,通过LLM生成最终的答案。
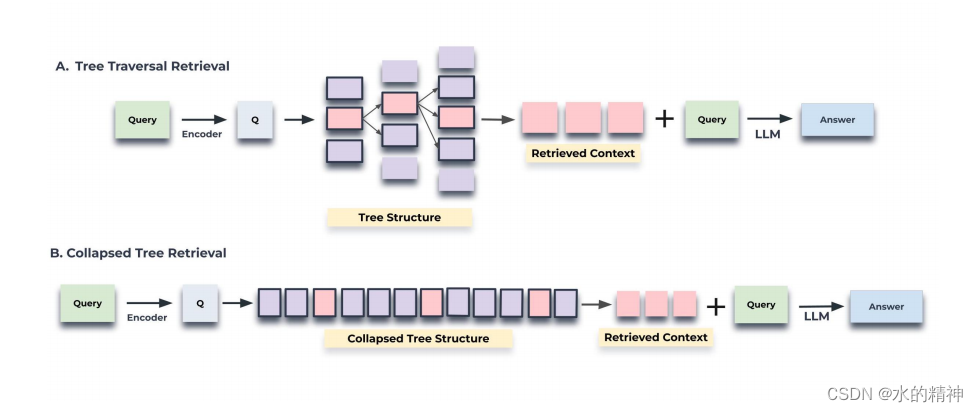
3.2 不分层
直接对全部节点执行检索。这种方法不是分层进行,而是将多层树扁平化成一层,本质上是将所有节点放到同一级别上进行比较。获取最相关的topK。
3.3 哪种检索方式更好?
不分层的检索方式更好,因为它提供了比树遍历更大的灵活性;也就是说,通过同时搜索所有节点,它检索到给定问题的正确粒度级别的信息。相比之下,当使用具有相同的d和k值的树遍历时,来自树的每个级别的节点的比率将是恒定的。因此,无论问题如何,高阶主题信息与颗粒状细节的比例都将保持不变。
四、效果如何
论文中使用的测试数据集: NarrativeQA, QASPER, and QuALITY。
NarrativeQA数据集,包括基于书籍和电影文本全文的问答对,总计1572个文档。
QASPER数据集包括1585篇NLP论文中的5049个问题,每个问题都在探索嵌入全文中的信息
QuALITY数据集由多项选择题组成,每个问题都伴随有平均约5000个标记的上下文段落(Pang et al.,2022)。这个数据集要求对整个文档的QA任务进行推理,从而使我们能够度量我们在中等长度文档上的检索系统的性能。该数据集包括一个具有挑战性的子集,QuALITYHARD,它包含了大多数人类注释者在速度设置中回答错误的问题。
NarrativeQA is a dataset that comprises question-answer pairs based on the full texts of booksand movie transcripts, totaling 1,572 documents ( Koˇcisk`y et al. , 2018 ; Wu et al. , 2021 ). The NarrativeQA-Story task requires a comprehensive understanding of the entire narrative in order to accurately answer its questions, thus testing the model’s ability to comprehend longer texts in the literary domain. We measure performance on this dataset using the standard BLEU (B-1, B-4), ROUGE (R-L), and METEOR (M) metrics. Please see appendix H for more details on the NarrativeQA evaluation script used in our experiments.The QASPER dataset includes 5,049 questions across 1,585 NLP papers, with each question probing for information embedded within the full text ( Dasigi et al. , 2021 ). The answer types in QASPER are categorized as Answerable/Unanswerable, Yes/No, Abstractive, and Extractive. Accuracy is measured using standard F1. Lastly, the QuALITY dataset consists of multiple-choice questions, each accompanied by context passages averaging approximately 5,000 tokens in length ( Pang et al. , 2022 ). This dataset calls forreasoning over the entire document for QA tasks, enabling us to measure the performance of our retrieval system on medium-length documents. The dataset includes a challenging subset, QuALITYHARD, which contains questions that a majority of human annotators answered incorrectly in a speed-setting. We report accuracies for both the entire test set and the HARD subset.
整体的提示功能在 3% -20%,其中在困难的数据集上的测试,提升效果来到了20%

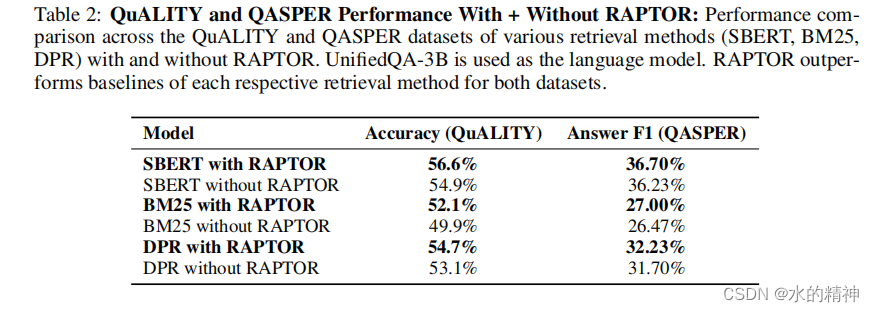
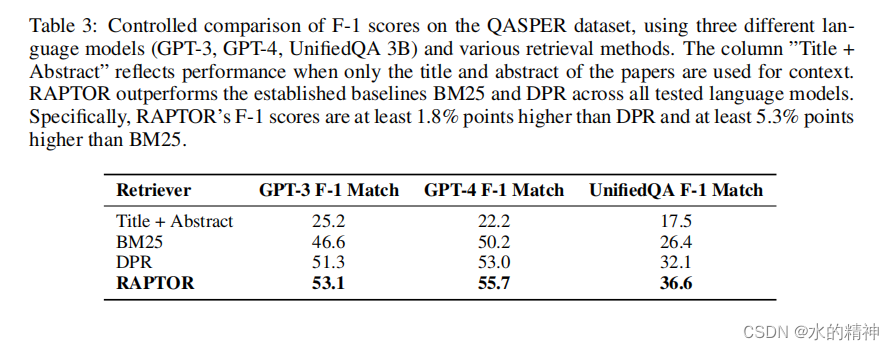
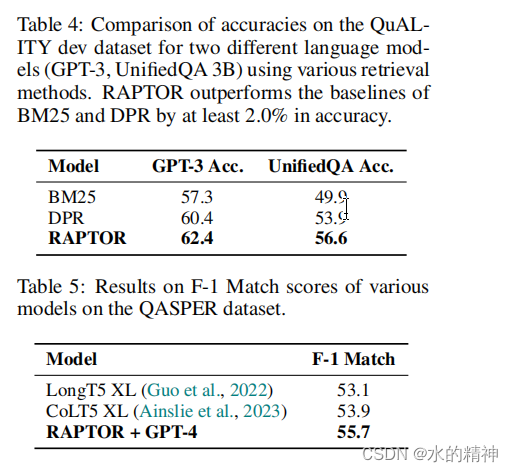
五、数据分层真的有意义吗?
直方图显示了使用三个检索器(SBERT、BM25和DPR)在三个数据集的不同层中检索到的节点的百分比。数据表明,对最终检索有贡献的很大一部分节点来自非叶层,其中显著的比例来自第一层和第二层,突出了树状的层次总结在检索过程中的重要性。

下图展示的是,数据不是来远不叶子节点的比例。也就是说这些数据无法只在叶子节点得到正确的回答。
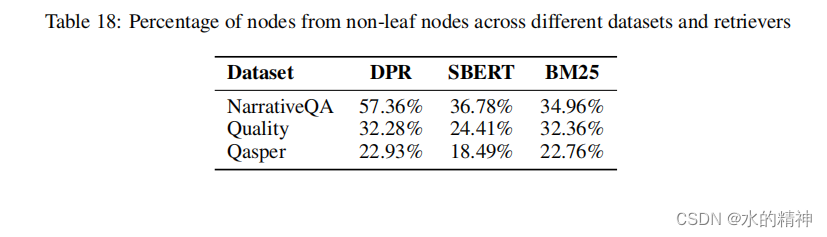















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









